HigherHRnet/DEKR骨骼关键点检测笔记:heatmap和offset理解
本文是对HigherHRnet/DEKR骨骼关键点检测项目代码阅读后的笔记。
Github:https://github.com/HRNet/DEKR
论文:https://arxiv.org/abs/2104.02300
HigherHRnet/DEKR骨骼关键点检测是MIT提出一种新颖的bottom-up方法,并且在COCO和Crowdpose中达到了SOTA,利用HRnet网络预测骨骼点的heatmap和offset,得到骨骼关键点的坐标和置信度。
heatmap+offset是谷歌在CVPR2017提出的一种谷歌关键点检测思路,但在谷歌的论文《Towards Accurate Multi-person Pose Estimation in the Wild》中,heatmap在骨骼关键点附近的值均为1,并且通过Hough voting方式将heatmap和offset结合,而DEKR采用了完全不同的思路。
以Crowdpose数据格式为例(COCO关键点有17个,Crowdpose有14个,即num_joints=14),在DEKR中,推理过程中网络预测的直接结果是heatmap和offset,其中heatmap的shape为[1,15(num_joints+1),h/4, w/4],offset的shape为[1, 28(2*num_joints), h/4, w/4],h和w是原图(指处理后输入网络的图片)高和宽。在这里不考虑第一个batch维度,相当于heatmap为15张热力图,offset为28张图,分辨率都为原来的1/4。heatmap很好理解,前14张热力图代表14个关键点(与Crowdpose顺序一致)的概率分布,最后一张热力图代表中心点的概率分布,中心点在训练中是通过标注数据14个关键点加权求和得到的,后续会解释为什么要多预测中心点的概率图。
以这张图为例分析heatmap和offset:

网络预测得到的15个heatmap:

前面14个heatmap代表14个关键点的概率分布,最后一个heatmap是中心点的概率分布。
需要注意的是heatmap只负责预测概率(置信度),而坐标全由offset得到。
offset包括28个通道,偶数通道预测x坐标的偏移量,奇数通道预测y坐标的偏移量。具体来说,offset[1, 2 * i, m, n] 代表m, n位置处第i个关键点的x坐标偏移量, offset[1, 2 * i+1, m, n] 代表m, n位置处,第i个关键点的y坐标偏移量。
既然知道了offset是坐标偏移量,但具体是怎么偏移的呢?网络上并没有找到相关的资料,只能看代码理解了。这里引入两个概念:location_map(代码中的locations)和posemap,这两个map的shape和offset一样,都是[1, 28, h/4, w/4]。
location_map和posemap以及offset的关系如下:
posemap = location_map - offset
先解释location_map, location_map的所有的偶数通道图像都是一样的,所有的奇数通道图像也是。f(x, y)表示图像像素值,对于偶数通道的location_map,f(x, y)=x,对于奇数通道,f(x, y)=y,下面这两张图分别展示了偶数通道和奇数通道的location_map:
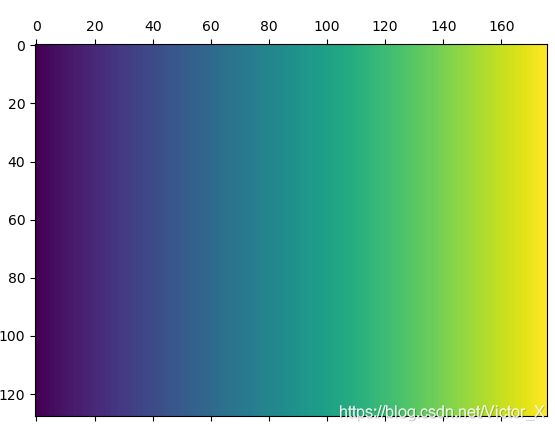

将location_map和offset相减后便得到posemap,注意posemap的维度也是[1, 28, h/4, w/4],对posemap进行4倍上采样得到[1, 28, h, w]的posemap,这个posemap就可以用来得到关键点坐标。理解posemap非常重要,我是这么理解的:把posemap看作一个w * h的28通道图像,这28个通道对应[14, 2]的坐标信息,即第一个通道代表第一个关键点的x坐标,第二个通道代表第一个关键点的y坐标,以此类推。因此在posemap的28通道图像上,每个位置28个值,代表骨骼中心点在这个位置处的14个关键点坐标信息。这时第15个通道的heatmap预测的中心点信息就用上了,比如我们在中心点的heatmap上得到(i, j)位置处的中心点概率最大,就可以用(i, j)这个坐标去posemap中索引得到14个骨骼关键点坐标。我一开始以为这个网络检测关键点的思路是通过heatmap得到所有关键点的坐标,再进行组合,实际上并不是这样的思路。
到此HigherHRnet/DEKR骨骼关键点检测的后处理大体思路也已经一目了然:
1.先通过网络得到heatmap和offset,通过location_map和offset生成posemap
2.在中心点heatmap上,找到中心点概率最大的点集以及对应概率,这个点集中的每个点都满足条件:在其周围3X3(可变动)领域中,该点的中心点概率最大。
3.对所有可能的中心点,在posemap中索引得到它们对应的14个关键点坐标。
4.进行非极大值抑制(NMS),选取置信度在阈值之上的关键点作为最终结果。
其余的一些细节比如:图像尺寸和关键点的预处理,最终如何把关键点坐标映射回原图,以及怎么通过其余14个heatmap得到每个关键点的置信度等。这些细节都就去看代码理解吧。