深度学习-Pytorch:Pytorch 创建CNN神经网络模型【ResNet模型】
一、自定义ResNet神经网络-Pytorch【cifar10图片分类数据集】
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
from torch.nn import functional as F
# 两层的残差学习单元 BasicBlock [(3×3)-->(3×3)]形状,如果是三层的BasicBlock,形状则为:[(1×1)-->(3×3)-->(1×1)]
# filter_count_in≠filter_count_out时,则通过该层Layer后的FeatureMap的大小改变,identity层也需要reshape
class BasicBlock(nn.Module):
def __init__(self, filter_count_in, filter_count_out, stride=1):
super(BasicBlock, self).__init__()
# we add stride support for resbok, which is distinct from tutorials.
self.conv1 = nn.Conv2d(in_channels=filter_count_in, out_channels=filter_count_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(filter_count_out)
self.conv2 = nn.Conv2d(filter_count_out, filter_count_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(filter_count_out)
self.identity = nn.Sequential()
if filter_count_in != filter_count_out: # 将输入值x的维度调整为和F(x)的输出维度保持一致 [b, filter_count_in, h, w] => [b, filter_count_out, h, w]
self.identity = nn.Sequential(
nn.Conv2d(filter_count_in, filter_count_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(filter_count_out)
)
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
F_out = self.bn2(x)
# short cut
identity_out = self.identity(input) # 调整input的维度与F_out保持一致,然后才能和F_out相加:[b, ch_in, h, w] => [b, ch_out, h, w]
H_out = identity_out + F_out
H_out = F.relu(H_out)
return H_out
# 由多个BasicBlock组成的ResidualBlock
class ResidualBlock:
def __init__(self, filter_count_in, filter_count_out, residualBlock_size=1, stride=1):
self.filter_count_in = filter_count_in
self.filter_count_out = filter_count_out
self.residualBlock_size = residualBlock_size
self.stride = stride
def __call__(self):
basic_block_stride_eq = BasicBlock(self.filter_count_in, self.filter_count_in, stride=1) # stride = 1 时的BasicBlock H(x)=x+F(X),identity_layer层的输出为直接返回输入
basic_block_stride_not_eq = BasicBlock(self.filter_count_in, self.filter_count_out, stride=self.stride) # stride != 1 时的BasicBlock H(x)=x+F(X),identity_layer进行SubSampling
residualBlock = nn.Sequential()
for _ in range(0, self.residualBlock_size - 1): # 其余的BasicBlock都是 filter_count_in == filter_count_out 时的BasicBlock
residualBlock.add_module('basic_block_stride_eq', basic_block_stride_eq)
residualBlock.add_module('basic_block_stride_not_eq', basic_block_stride_not_eq) # 有一个BasicBlock必须是 filter_count_in != filter_count_out 时的BasicBlock
return residualBlock
# 由多个ResidualBlock组成的ResidualNet
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64)
)
# followed 4 ResidualBlock
self.residualBlock1 = ResidualBlock(filter_count_in=64, filter_count_out=128, residualBlock_size=2, stride=2)() # [b, 64, h, w] => [b, 128, h ,w]
self.residualBlock2 = ResidualBlock(filter_count_in=128, filter_count_out=256, residualBlock_size=2, stride=2)() # [b, 128, h, w] => [b, 256, h, w]
self.residualBlock3 = ResidualBlock(filter_count_in=256, filter_count_out=512, residualBlock_size=2, stride=2)() # [b, 256, h, w] => [b, 512, h, w]
self.residualBlock4 = ResidualBlock(filter_count_in=512, filter_count_out=512, residualBlock_size=2, stride=2)() # [b, 512, h, w] => [b, 1024, h, w]
self.outlayer = nn.Linear(512 * 1 * 1, 10)
def forward(self, X):
X = F.relu(self.conv1(X))
# [b, 64, h, w] => [b, 1024, h, w]
X = self.residualBlock1(X)
X = self.residualBlock2(X)
X = self.residualBlock3(X)
X = self.residualBlock4(X) # [b, 512, 2, 2]
X = F.adaptive_avg_pool2d(X, [1, 1]) # [b, 512, 2, 2] => [b, 512, 1, 1]
X = X.view(X.size(0), -1) # [b, 512, 1, 1] => [b, 512]
X = self.outlayer(X) # [b, 512] => [b, 10]
return X
def main():
batch_size = 200
# 一、获取cifar10训练数据集
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batch_size, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batch_size, shuffle=True)
# 二、设置GPU
device = torch.device('cuda')
# 三、实例化ResNet18神经网络模型
model = ResNet18().to(device)
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 六、训练
for epoch in range(3):
# **********************************************************训练**********************************************************
print('**************************训练模式:开始**************************')
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(cifar_train):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_index % 100 == 0:
print('epoch = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch, batch_index, loss.item()))
print('**************************训练模式:结束**************************')
# **********************************************************模型评估**********************************************************
print('**************************验证模式:开始**************************')
model.eval() # 切换至验证模式
with torch.no_grad(): # torch.no_grad()所包裹的部分不需要参与反向传播
# test
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(cifar_test):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
acc = total_correct / total_num
if batch_index % 100 == 0:
print('epoch = {0}, batch_index = {1}, test acc = {2}'.format(epoch, batch_index, acc))
print('**************************验证模式:结束**************************')
if __name__ == '__main__':
main()
打印结果:
Files already downloaded and verified
Files already downloaded and verified
15,826,314 total parameters.
15,826,314 training parameters.
model = ResNet18(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(residualBlock1): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock2): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock3): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock4): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(outlayer): Linear(in_features=512, out_features=10, bias=True)
)
**************************训练模式:开始**************************
epoch = 0, batch_index = 0, loss.item() = 2.784912109375
epoch = 0, batch_index = 100, loss.item() = 1.2591865062713623
epoch = 0, batch_index = 200, loss.item() = 1.2418736219406128
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 0, batch_index = 0, test acc = 0.515
**************************验证模式:结束**************************
**************************训练模式:开始**************************
epoch = 1, batch_index = 0, loss.item() = 1.0537413358688354
epoch = 1, batch_index = 100, loss.item() = 1.088006615638733
epoch = 1, batch_index = 200, loss.item() = 1.0332653522491455
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 1, batch_index = 0, test acc = 0.635
**************************验证模式:结束**************************
**************************训练模式:开始**************************
epoch = 2, batch_index = 0, loss.item() = 0.9080470204353333
epoch = 2, batch_index = 100, loss.item() = 0.7950635552406311
epoch = 2, batch_index = 200, loss.item() = 0.7487978339195251
**************************训练模式:结束**************************
**************************验证模式:开始**************************
epoch = 2, batch_index = 0, test acc = 0.64
**************************验证模式:结束**************************
Process finished with exit code 0
二、自定义ResNet18 & 自定义数据集-Pytorch
import torch
from torch.utils.data import DataLoader
from torch import nn, optim
from torch.nn import functional as F
import visdom
import csv
import glob
import os
import random
from PIL import Image
from torch.utils.data import Dataset # 自定义数据集的父类
from torchvision import transforms
torch.manual_seed(1234) # 随机种子
device = torch.device('cuda') # 设置GPU
# =============================================================================Pokemon自定义数据集:开始=============================================================================
class Pokemon(Dataset):
# root表示数据位置;resize表示数据输出的size;mode表示训练模式/测试模式
def __init__(self, root, resize, mode):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
# 给各个类型进行编号
self.name2label = {} # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)): # 过滤掉不是文件夹的文件
continue
self.name2label[name] = len(self.name2label.keys())
print('self.name2label = {0}'.format(self.name2label)) # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
# 读取已保存的图片+标签数据集
self.img_paths, self.labels = self.load_csv('img_paths.csv') # 数据对(img_path + image_label):img_paths, labels
# 对数据集根据当前模式进行裁剪
if mode == 'train': # 60%
self.img_paths = self.img_paths[:int(0.6 * len(self.img_paths))]
self.labels = self.labels[:int(0.6 * len(self.labels))]
elif mode == 'val': # 20% = 60%->80%
self.img_paths = self.img_paths[int(0.6 * len(self.img_paths)):int(0.8 * len(self.img_paths))]
self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
else: # 20% = 80%->100%
self.img_paths = self.img_paths[int(0.8 * len(self.img_paths)):]
self.labels = self.labels[int(0.8 * len(self.labels)):]
def load_csv(self, filename):
# 1、如果没有csv文件,则创建该csv文件
if not os.path.exists(os.path.join(self.root, filename)):
img_paths = [] # 把所有图片的path都保存在该list中,各个图片的label可以从path推断出来,所有没有单独保存。
for name in self.name2label.keys():
img_paths += glob.glob(os.path.join(self.root, name, '*.png')) # 'pokemon\\mewtwo\\00001.png
img_paths += glob.glob(os.path.join(self.root, name, '*.jpg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.jpeg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.gif'))
print('len(img_paths) = {0}, img_paths = {1}'.format(len(img_paths), img_paths)) # len(img_paths) = 1168, img_paths = ['pokemon\\bulbasaur\\00000000.png','pokemon\\bulbasaur\\00000001.png',...]
random.shuffle(img_paths) # 打乱list中的图片顺序
# 向csv文件保存图片的path+label
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img_path in img_paths: # 'pokemon\\bulbasaur\\00000000.png'
name = img_path.split(os.sep)[-2]
label = self.name2label[name]
writer.writerow([img_path, label]) # 'pokemon\\bulbasaur\\00000000.png', 0
print('writen into csv file:', filename)
# 2、如果已经有csv文件,则读取该csv文件
img_paths, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
img_path, label = row # 'pokemon\\bulbasaur\\00000000.png', 0
label = int(label)
img_paths.append(img_path)
labels.append(label)
assert len(img_paths) == len(labels)
return img_paths, labels
def __len__(self):
return len(self.img_paths)
def denormalize(self, x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x-mean)/std
# x = x_hat*std = mean
# x: [c, h, w]
# mean: [3] => [3, 1, 1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print('denormalize-->mean.shape = {0}, std.shape = {1}'.format(mean.shape, std.shape))
x = x_hat * std + mean
return x
def __getitem__(self, img_idx): # img_idx~[0~len(img_paths)]
img_path, label = self.img_paths[img_idx], self.labels[img_idx] # img_path: 'pokemon\\bulbasaur\\00000000.png';label: 0
transform = transforms.Compose([
lambda x: Image.open(x).convert('RGB'), # string path --> image data
transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
transforms.RandomRotation(15), # rotate如果比较大的话,可能会造成网络不收敛
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 该数值是实践中统计的效果比较好的值
])
img = transform(img_path)
label = torch.tensor(label)
return img, label
# =============================================================================Pokemon自定义数据集:结束=============================================================================
# =============================================================================ResNet18神经网络:开始=============================================================================
# 两层的残差学习单元 BasicBlock [(3×3)-->(3×3)]形状,如果是三层的BasicBlock,形状则为:[(1×1)-->(3×3)-->(1×1)]
# filter_count_in≠filter_count_out时,则通过该层Layer后的FeatureMap的大小改变,identity层也需要reshape
class BasicBlock(nn.Module):
def __init__(self, filter_count_in, filter_count_out, stride=1):
super(BasicBlock, self).__init__()
self.filter_count_in = filter_count_in
self.filter_count_out = filter_count_out
self.stride = stride
# we add stride support for resbok, which is distinct from tutorials.
self.conv1 = nn.Conv2d(in_channels=filter_count_in, out_channels=filter_count_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(filter_count_out)
self.conv2 = nn.Conv2d(filter_count_out, filter_count_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(filter_count_out)
self.identity = nn.Sequential()
if filter_count_in != filter_count_out: # 将输入值x的维度调整为和F(x)的输出维度保持一致 [b, filter_count_in, h, w] => [b, filter_count_out, h, w]
self.identity = nn.Sequential(
nn.Conv2d(filter_count_in, filter_count_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(filter_count_out)
)
def forward(self, input):
x = self.conv1(input)
x = self.bn1(x)
x = F.relu(x)
x = self.conv2(x)
F_out = self.bn2(x)
# short cut
identity_out = self.identity(input) # 调整input的维度与F_out保持一致,然后才能和F_out相加:[b, ch_in, h, w] => [b, ch_out, h, w]
# print('stride = {0},filter_count_in = {1},filter_count_out = {2},F_out.shape = {3},identity_out.shape = {4}'.format(self.stride, self.filter_count_in, self.filter_count_out, F_out.shape, identity_out.shape))
H_out = identity_out + F_out
H_out = F.relu(H_out)
return H_out
# 由多个BasicBlock组成的ResidualBlock
class ResidualBlock:
def __init__(self, filter_count_in, filter_count_out, residualBlock_size=1, stride=1):
self.filter_count_in = filter_count_in
self.filter_count_out = filter_count_out
self.residualBlock_size = residualBlock_size
self.stride = stride
def __call__(self):
basic_block_stride_eq = BasicBlock(self.filter_count_in, self.filter_count_in, stride=1) # stride = 1 时的BasicBlock H(x)=x+F(X),identity_layer层的输出为直接返回输入
basic_block_stride_not_eq = BasicBlock(self.filter_count_in, self.filter_count_out, stride=self.stride) # stride != 1 时的BasicBlock H(x)=x+F(X),identity_layer进行SubSampling
residualBlock = nn.Sequential()
for _ in range(0, self.residualBlock_size - 1): # 其余的BasicBlock都是 filter_count_in == filter_count_out 时的BasicBlock
residualBlock.add_module('basic_block_stride_eq', basic_block_stride_eq)
residualBlock.add_module('basic_block_stride_not_eq', basic_block_stride_not_eq) # 有一个BasicBlock必须是 filter_count_in != filter_count_out 时的BasicBlock
return residualBlock
# 由多个ResidualBlock组成的ResidualNet
class ResNet18(nn.Module):
def __init__(self, num_class): # num_class 表示最终所有分类数量
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64)
)
# followed 4 ResidualBlock
self.residualBlock1 = ResidualBlock(filter_count_in=64, filter_count_out=128, residualBlock_size=2, stride=2)() # [b, 64, h, w] => [b, 128, h ,w]
self.residualBlock2 = ResidualBlock(filter_count_in=128, filter_count_out=256, residualBlock_size=2, stride=2)() # [b, 128, h, w] => [b, 256, h, w]
self.residualBlock3 = ResidualBlock(filter_count_in=256, filter_count_out=512, residualBlock_size=2, stride=2)() # [b, 256, h, w] => [b, 512, h, w]
self.residualBlock4 = ResidualBlock(filter_count_in=512, filter_count_out=512, residualBlock_size=2, stride=1)() # [b, 512, h, w] => [b, 1024, h, w]
self.outlayer = nn.Linear(512 * 1 * 1, num_class)
def forward(self, X):
X = F.relu(self.conv1(X))
# [b, 64, h, w] => [b, 1024, h, w]
X = self.residualBlock1(X)
X = self.residualBlock2(X)
X = self.residualBlock3(X)
X = self.residualBlock4(X) # [b, 512, 2, 2]
X = F.adaptive_avg_pool2d(X, [1, 1]) # [b, 512, 2, 2] => [b, 512, 1, 1]
X = X.view(X.size(0), -1) # [b, 512, 1, 1] => [b, 512]
X = self.outlayer(X) # [b, 512] => [b, 5]
return X
# =============================================================================ResNet18神经网络:结束=============================================================================
# =============================================================================训练主体:开始=============================================================================
batch_size = 32
viz = visdom.Visdom() # 在控制台开启Visdom:python -m visdom.server
global_step = 0
# 一、获取Pokemon训练数据集
train_db = Pokemon('pokemon', 224, mode='train')
val_db = Pokemon('pokemon', 224, mode='val')
test_db = Pokemon('pokemon', 224, mode='test')
train_loader = DataLoader(train_db, batch_size=batch_size, shuffle=True, num_workers=0) # num_workers表示开启的线程数量
val_loader = DataLoader(val_db, batch_size=batch_size, num_workers=0)
test_loader = DataLoader(test_db, batch_size=batch_size, num_workers=0)
# 三、实例化ResNet18神经网络模型
model = ResNet18(5).to(device)
total_params = sum(p.numel() for p in model.parameters()) # 模型参数总数量
print("模型参数总数量 = {0}".format(total_params ))
total_trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad) # 模型可训练参数总数量
print("模型可训练参数总数量 = {0}".format(total_trainable_params )) # print(f'{total_trainable_params:,} training parameters.')
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
def train_epoch(epoch_no):
global global_step
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(train_loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch_no, batch_index, loss.item()))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
def evalute(epoch_no, loader):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.eval()
with torch.no_grad():
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
val_acc = total_correct / total_num
viz.line([val_acc], [global_step], win='val_acc', update='append')
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, val_acc = {2}'.format(epoch_no, batch_index, val_acc))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
return val_acc
def main():
epoch_count = 4 # epoch_count为整体数据集迭代梯度下降次数
best_acc, best_epoch = 0, 0
viz.line([0], [-1], win='loss', opts=dict(title='loss'))
viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc'))
for epoch_no in range(1, epoch_count + 1):
print('\n\n利用整体数据集进行模型的第{0}轮Epoch迭代开始:**********************************************************************************************************************************'.format(epoch_no))
train_epoch(epoch_no) # 训练
val_acc = evalute(epoch_no, val_loader) # 验证
if val_acc > best_acc:
best_epoch = epoch_no
best_acc = val_acc
torch.save(model.state_dict(), 'best.mdl')
print('epoch = {0}, best_epoch = {1}, best_acc = {2}'.format(epoch_no, best_epoch, best_acc))
print('**************************验证模式:结束**************************')
print('利用整体数据集进行模型的第{0}轮Epoch迭代结束:**********************************************************************************************************************************'.format(epoch_no))
print('best acc:', best_acc, 'best epoch:', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evalute(best_epoch, test_loader) # 测试
print('test acc:', test_acc)
if __name__ == '__main__':
main()
# =============================================================================训练主体:结束=============================================================================

打印结果:
Setting up a new session...
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
15,823,749 total parameters.
15,823,749 training parameters.
model = ResNet18(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(residualBlock1): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock2): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock3): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(residualBlock4): Sequential(
(basic_block_stride_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
(basic_block_stride_not_eq): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(identity): Sequential()
)
)
(outlayer): Linear(in_features=512, out_features=5, bias=True)
)
利用整体数据集进行模型的第1轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, loss.item() = 1.939097285270691
epoch_no = 1, batch_index = 5, loss.item() = 1.332801342010498
epoch_no = 1, batch_index = 10, loss.item() = 1.3339236974716187
epoch_no = 1, batch_index = 15, loss.item() = 0.44973278045654297
epoch_no = 1, batch_index = 20, loss.item() = 0.4216762185096741
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, val_acc = 0.6875
epoch_no = 1, batch_index = 5, val_acc = 0.7395833333333334
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 1, best_epoch = 1, best_acc = 0.7478632478632479
**************************验证模式:结束**************************
利用整体数据集进行模型的第1轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第2轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, loss.item() = 0.5493289232254028
epoch_no = 2, batch_index = 5, loss.item() = 0.6154159307479858
epoch_no = 2, batch_index = 10, loss.item() = 0.6554363965988159
epoch_no = 2, batch_index = 15, loss.item() = 0.4766008257865906
epoch_no = 2, batch_index = 20, loss.item() = 0.45220986008644104
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, val_acc = 0.71875
epoch_no = 2, batch_index = 5, val_acc = 0.8020833333333334
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 2, best_epoch = 2, best_acc = 0.8076923076923077
**************************验证模式:结束**************************
利用整体数据集进行模型的第2轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第3轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, loss.item() = 0.6022523641586304
epoch_no = 3, batch_index = 5, loss.item() = 0.5406889319419861
epoch_no = 3, batch_index = 10, loss.item() = 0.22856442630290985
epoch_no = 3, batch_index = 15, loss.item() = 0.5484329462051392
epoch_no = 3, batch_index = 20, loss.item() = 0.36236143112182617
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, val_acc = 0.84375
epoch_no = 3, batch_index = 5, val_acc = 0.859375
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 3, best_epoch = 3, best_acc = 0.8589743589743589
**************************验证模式:结束**************************
利用整体数据集进行模型的第3轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第4轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, loss.item() = 0.47427237033843994
epoch_no = 4, batch_index = 5, loss.item() = 0.30755600333213806
epoch_no = 4, batch_index = 10, loss.item() = 0.7977475523948669
epoch_no = 4, batch_index = 15, loss.item() = 0.3868430554866791
epoch_no = 4, batch_index = 20, loss.item() = 0.46423253417015076
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, val_acc = 0.90625
epoch_no = 4, batch_index = 5, val_acc = 0.8958333333333334
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 4, best_epoch = 4, best_acc = 0.8931623931623932
**************************验证模式:结束**************************
利用整体数据集进行模型的第4轮Epoch迭代结束:**********************************************************************************************************************************
best acc: 0.8931623931623932 best epoch: 4
loaded from ckpt!
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, val_acc = 0.84375
epoch_no = 4, batch_index = 5, val_acc = 0.828125
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
test acc: 0.8290598290598291
Process finished with exit code 0
三、迁移学习 & 预训练ResNet18 & 自定义数据集-Pytorch
import torch
from torch.utils.data import DataLoader
from torch import nn, optim
from torch.nn import functional as F
import visdom
import csv
import glob
import os
import random
from PIL import Image
from torch.utils.data import Dataset # 自定义数据集的父类
from torchvision import transforms
from torchvision.models import resnet18
torch.manual_seed(1234) # 随机种子
device = torch.device('cuda') # 设置GPU
# =============================================================================Pokemon自定义数据集:开始=============================================================================
class Pokemon(Dataset):
# root表示数据位置;resize表示数据输出的size;mode表示训练模式/测试模式
def __init__(self, root, resize, mode):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
# 给各个类型进行编号
self.name2label = {} # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)): # 过滤掉不是文件夹的文件
continue
self.name2label[name] = len(self.name2label.keys())
print('self.name2label = {0}'.format(self.name2label)) # {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
# 读取已保存的图片+标签数据集
self.img_paths, self.labels = self.load_csv('img_paths.csv') # 数据对(img_path + image_label):img_paths, labels
# 对数据集根据当前模式进行裁剪
if mode == 'train': # 60%
self.img_paths = self.img_paths[:int(0.6 * len(self.img_paths))]
self.labels = self.labels[:int(0.6 * len(self.labels))]
elif mode == 'val': # 20% = 60%->80%
self.img_paths = self.img_paths[int(0.6 * len(self.img_paths)):int(0.8 * len(self.img_paths))]
self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
else: # 20% = 80%->100%
self.img_paths = self.img_paths[int(0.8 * len(self.img_paths)):]
self.labels = self.labels[int(0.8 * len(self.labels)):]
def load_csv(self, filename):
# 1、如果没有csv文件,则创建该csv文件
if not os.path.exists(os.path.join(self.root, filename)):
img_paths = [] # 把所有图片的path都保存在该list中,各个图片的label可以从path推断出来,所有没有单独保存。
for name in self.name2label.keys():
img_paths += glob.glob(os.path.join(self.root, name, '*.png')) # 'pokemon\\mewtwo\\00001.png
img_paths += glob.glob(os.path.join(self.root, name, '*.jpg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.jpeg'))
img_paths += glob.glob(os.path.join(self.root, name, '*.gif'))
print('len(img_paths) = {0}, img_paths = {1}'.format(len(img_paths), img_paths)) # len(img_paths) = 1168, img_paths = ['pokemon\\bulbasaur\\00000000.png','pokemon\\bulbasaur\\00000001.png',...]
random.shuffle(img_paths) # 打乱list中的图片顺序
# 向csv文件保存图片的path+label
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img_path in img_paths: # 'pokemon\\bulbasaur\\00000000.png'
name = img_path.split(os.sep)[-2]
label = self.name2label[name]
writer.writerow([img_path, label]) # 'pokemon\\bulbasaur\\00000000.png', 0
print('writen into csv file:', filename)
# 2、如果已经有csv文件,则读取该csv文件
img_paths, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
img_path, label = row # 'pokemon\\bulbasaur\\00000000.png', 0
label = int(label)
img_paths.append(img_path)
labels.append(label)
assert len(img_paths) == len(labels)
return img_paths, labels
def __len__(self):
return len(self.img_paths)
def denormalize(self, x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x-mean)/std
# x = x_hat*std = mean
# x: [c, h, w]
# mean: [3] => [3, 1, 1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print('denormalize-->mean.shape = {0}, std.shape = {1}'.format(mean.shape, std.shape))
x = x_hat * std + mean
return x
def __getitem__(self, img_idx): # img_idx~[0~len(img_paths)]
img_path, label = self.img_paths[img_idx], self.labels[img_idx] # img_path: 'pokemon\\bulbasaur\\00000000.png';label: 0
transform = transforms.Compose([
lambda x: Image.open(x).convert('RGB'), # string path --> image data
transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
transforms.RandomRotation(15), # rotate如果比较大的话,可能会造成网络不收敛
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 该数值是实践中统计的效果比较好的值
])
img = transform(img_path)
label = torch.tensor(label)
return img, label
# =============================================================================Pokemon自定义数据集:结束=============================================================================
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, x):
shape = torch.prod(torch.tensor(x.shape[1:])).item()
return x.view(-1, shape)
# =============================================================================训练主体:开始=============================================================================
batch_size = 32
viz = visdom.Visdom() # 在控制台开启Visdom:python -m visdom.server
global_step = 0
# 一、获取Pokemon训练数据集
train_db = Pokemon('pokemon', 224, mode='train')
val_db = Pokemon('pokemon', 224, mode='val')
test_db = Pokemon('pokemon', 224, mode='test')
train_loader = DataLoader(train_db, batch_size=batch_size, shuffle=True, num_workers=0) # num_workers表示开启的线程数量
val_loader = DataLoader(val_db, batch_size=batch_size, num_workers=0)
test_loader = DataLoader(test_db, batch_size=batch_size, num_workers=0)
# 三、实例化预训练ResNet18神经网络模型
trained_model = resnet18(pretrained=True)
model = nn.Sequential(*list(trained_model.children())[:-1], # 提取已经训练好的resnet18模型的前17层,打散。[b, 512, 1, 1]
Flatten(), # [b, 512, 1, 1] => [b, 512]
nn.Linear(512, 5)
).to(device)
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
print('model = {0}\n'.format(model))
# 四、实例化损失函数
criteon = nn.CrossEntropyLoss().to(device)
# 五、梯度下降优化器设置
optimizer = optim.Adam(model.parameters(), lr=1e-3)
def train_epoch(epoch_no):
global global_step
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.train() # 切换至训练模式
for batch_index, (X_batch, Y_batch) in enumerate(train_loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
loss = criteon(out_logits, Y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, loss.item() = {2}'.format(epoch_no, batch_index, loss.item()))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
def evalute(epoch_no, loader):
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
model.eval()
with torch.no_grad():
total_correct = 0
total_num = 0
for batch_index, (X_batch, Y_batch) in enumerate(loader):
X_batch, Y_batch = X_batch.to(device), Y_batch.to(device)
out_logits = model(X_batch)
out_pred = out_logits.argmax(dim=1)
correct = torch.eq(out_pred, Y_batch).float().sum().item()
total_correct += correct
total_num += X_batch.size(0)
val_acc = total_correct / total_num
viz.line([val_acc], [global_step], win='val_acc', update='append')
if batch_index % 5 == 0:
print('epoch_no = {0}, batch_index = {1}, val_acc = {2}'.format(epoch_no, batch_index, val_acc))
print('++++++++++++++++++++++++++++++++++++++++++++第{0}轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++'.format(epoch_no))
return val_acc
def main():
epoch_count = 4 # epoch_count为整体数据集迭代梯度下降次数
best_acc, best_epoch = 0, 0
viz.line([0], [-1], win='loss', opts=dict(title='loss'))
viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc'))
for epoch_no in range(1, epoch_count + 1):
print('\n\n利用整体数据集进行模型的第{0}轮Epoch迭代开始:**********************************************************************************************************************************'.format(epoch_no))
train_epoch(epoch_no) # 训练
val_acc = evalute(epoch_no, val_loader) # 验证
if val_acc > best_acc:
best_epoch = epoch_no
best_acc = val_acc
torch.save(model.state_dict(), 'best.mdl')
print('epoch = {0}, best_epoch = {1}, best_acc = {2}'.format(epoch_no, best_epoch, best_acc))
print('**************************验证模式:结束**************************')
print('利用整体数据集进行模型的第{0}轮Epoch迭代结束:**********************************************************************************************************************************'.format(epoch_no))
print('best acc:', best_acc, 'best epoch:', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evalute(best_epoch, test_loader) # 测试
print('test acc:', test_acc)
if __name__ == '__main__':
main()
# =============================================================================训练主体:结束=============================================================================
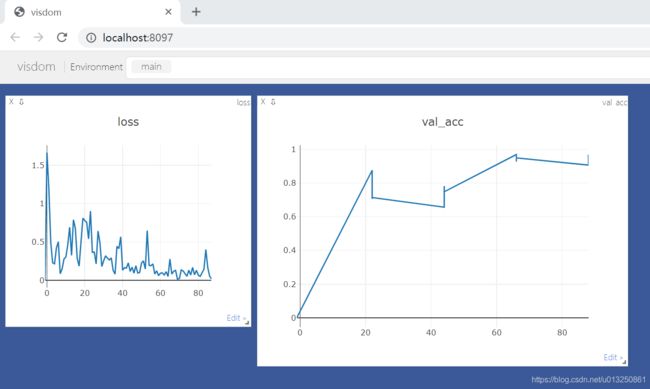
打印结果:
Setting up a new session...
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
self.name2label = {'bulbasaur': 0, 'charmander': 1, 'mewtwo': 2, 'pikachu': 3, 'squirtle': 4}
11,179,077 total parameters.
11,179,077 training parameters.
model = Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(6): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(7): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(8): AdaptiveAvgPool2d(output_size=(1, 1))
(9): Flatten()
(10): Linear(in_features=512, out_features=5, bias=True)
)
利用整体数据集进行模型的第1轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, loss.item() = 1.664962887763977
epoch_no = 1, batch_index = 5, loss.item() = 0.4224851131439209
epoch_no = 1, batch_index = 10, loss.item() = 0.3056411147117615
epoch_no = 1, batch_index = 15, loss.item() = 0.6770390868186951
epoch_no = 1, batch_index = 20, loss.item() = 0.778434157371521
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 1, batch_index = 0, val_acc = 0.875
epoch_no = 1, batch_index = 5, val_acc = 0.7239583333333334
++++++++++++++++++++++++++++++++++++++++++++第1轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 1, best_epoch = 1, best_acc = 0.7136752136752137
**************************验证模式:结束**************************
利用整体数据集进行模型的第1轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第2轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, loss.item() = 0.5391928553581238
epoch_no = 2, batch_index = 5, loss.item() = 0.641627848148346
epoch_no = 2, batch_index = 10, loss.item() = 0.28850072622299194
epoch_no = 2, batch_index = 15, loss.item() = 0.44357800483703613
epoch_no = 2, batch_index = 20, loss.item() = 0.15881212055683136
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 2, batch_index = 0, val_acc = 0.65625
epoch_no = 2, batch_index = 5, val_acc = 0.7447916666666666
++++++++++++++++++++++++++++++++++++++++++++第2轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 2, best_epoch = 2, best_acc = 0.7478632478632479
**************************验证模式:结束**************************
利用整体数据集进行模型的第2轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第3轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, loss.item() = 0.11576351523399353
epoch_no = 3, batch_index = 5, loss.item() = 0.10171618312597275
epoch_no = 3, batch_index = 10, loss.item() = 0.19451947510242462
epoch_no = 3, batch_index = 15, loss.item() = 0.06140638515353203
epoch_no = 3, batch_index = 20, loss.item() = 0.049921028316020966
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, val_acc = 0.96875
epoch_no = 3, batch_index = 5, val_acc = 0.953125
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 3, best_epoch = 3, best_acc = 0.9487179487179487
**************************验证模式:结束**************************
利用整体数据集进行模型的第3轮Epoch迭代结束:**********************************************************************************************************************************
利用整体数据集进行模型的第4轮Epoch迭代开始:**********************************************************************************************************************************
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Training 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, loss.item() = 0.08163614571094513
epoch_no = 4, batch_index = 5, loss.item() = 0.1351318359375
epoch_no = 4, batch_index = 10, loss.item() = 0.06922706216573715
epoch_no = 4, batch_index = 15, loss.item() = 0.051600512117147446
epoch_no = 4, batch_index = 20, loss.item() = 0.05538956820964813
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Training 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 4, batch_index = 0, val_acc = 0.90625
epoch_no = 4, batch_index = 5, val_acc = 0.9479166666666666
++++++++++++++++++++++++++++++++++++++++++++第4轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
epoch = 4, best_epoch = 3, best_acc = 0.9487179487179487
**************************验证模式:结束**************************
利用整体数据集进行模型的第4轮Epoch迭代结束:**********************************************************************************************************************************
best acc: 0.9487179487179487 best epoch: 3
loaded from ckpt!
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:开始++++++++++++++++++++++++++++++++++++++++++++
epoch_no = 3, batch_index = 0, val_acc = 0.96875
epoch_no = 3, batch_index = 5, val_acc = 0.921875
++++++++++++++++++++++++++++++++++++++++++++第3轮Epoch-->Evluation 阶段:结束++++++++++++++++++++++++++++++++++++++++++++
test acc: 0.9230769230769231
Process finished with exit code 0