聚类(三)--DBSCAN
DBSCan算法
DBSCAN算法算法是基于密度得一类聚类算法,可以将具有足够高密度的区域划分成簇,并可以发现任何形状的聚类。
下面先介绍几组概念:
ϵ \epsilon ϵ邻域:给定对象半径 ϵ \epsilon ϵ内的区域称为该对象的 ϵ \epsilon ϵ邻域。
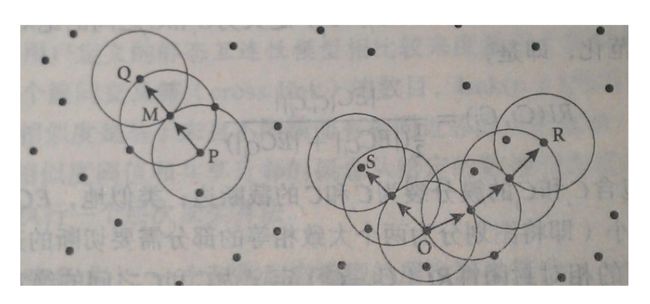
如下图所示,如果假设p点为中心点,以 ϵ \epsilon ϵ为半径的圆域就是p的 ϵ \epsilon ϵ邻域。
核心对象:如果给定 ϵ \epsilon ϵ邻域内的样本点数大于等于Minpoints,则该对象为核心对象。
如下图:假设Minpoints=3,以p为中心,他的 ϵ \epsilon ϵ邻域内有4个样本点,大于Minpoints,所以以p为中心的 ϵ \epsilon ϵ邻域是核心对象,而以Q为中心的 ϵ \epsilon ϵ邻域中只有2个样本点,所以不是核心对象。
直接密度可达:给定一个对象集合D,如果q在p的 ϵ \epsilon ϵ邻域内,且q是一个核心对象,则我们说对象p是从q出发是直接密度可达的。
如下图,如果p点是一个核心对象,M点是在P的 ϵ \epsilon ϵ邻域内,那么认为M从P出发是直接密度可达的。
密度可达:集合D,存在一个对象链p1,p2,……,pn,满足p1=q,pn=p,且pn+1由pn直接密度可达,则称p由q密度可达。也就是说密度可达具有传递性。
如下图,P到M是直接密度可达的,M到Q也是直接密度可达的,那么P到Q就是密度可达的。
密度相连:集合D中存在点o,使得点p,q是从o关于 ϵ \epsilon ϵ和Minpoints密度可达的,那么p,q是关于 ϵ \epsilon ϵ和minpoint是密度相连的。
如下图,O到R是密度可达的,O到S也是密度可达的,则成S和R是密度相连的。
算法思想
1.指定合适的 ϵ \epsilon ϵ和minpoints
2.计算所有的样本的,如果点p的 ϵ \epsilon ϵ邻域里由超过Minpoints个点,则创建一个以p为核心点的新簇。
3.反复寻找这些核心点直接密度可达的点,将其加入到相应的簇,对于核心点发生“密度相连”状况的簇,给与合并。
4,当没有新的点可以被添加到任何簇时,算法结束。
算法优缺点:
优点:
①可以对任意形状的数据集进行聚类。
②可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
③聚类结果较为稳定,相对的,k——Means算法初始值对聚类结果有很大的影响。
缺点:
①当数据量增大时,要求较大的内存支持和I/O消耗。
②当空间聚类的密度不均匀,聚类间差距差相差很大时,聚类质量较差。
DBSCAN与K-Means比较:
DBSCAN不需要输入聚类个数。
聚类的形状没有要求。
可以在需要时输入过滤噪声的参数( ϵ \epsilon ϵ和minpoints)
算法可视化网站,有兴趣可以去玩一玩。
程序:
from sklearn.cluster import DBSCAN
import numpy as np
import matplotlib.pyplot as plt
#载入数据
data=np.genfromtxt('kmeans.txt',delimiter=' ')
#训练模型
model=DBSCAN(eps=1.5,min_samples=4)
#eps时邻域的半径 min——samples是称为核心对象最小样本数
model.fit(data)
DBSCAN(eps=1.5, min_samples=4)
result=model.fit_predict(data)#先Fit后predict
result
#样本标签为-1表示不属于任何一个类别
array([ 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, -1, 2, 0,
1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1,
2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2,
3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3,
0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3], dtype=int64)
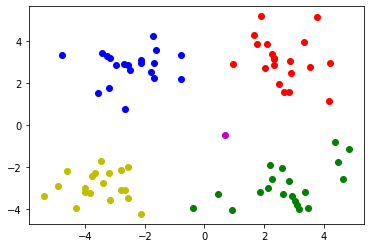
#画出各个数据点,用不同颜色分类表示
mark=['or','ob','og','oy','ok','om']
for i ,d in enumerate(data):
plt.plot(d[0],d[1],mark[result[i]])
plt.show()
#紫色点可以认为是噪音数据