【文献阅读笔记】之基于Deeplabv3+的图像语义分割优化方法
中文,包装工程,第 43 卷 第 1 期,2022 年 1 月
DOI:10.19554/j.cnki.1001-3563.2022.01.024
摘要
目的 为了实现良好的图像语义分割精度,同时尽可能降低网络的参数量,加快网络训练速度, 提出基于 DeepLabv3+ 的图像语义分割优化方法。方法 编码器主干网络增加注意力机制模块,并采用更 密集的特征池化模块有效聚合多尺度特征,同时使用深度可分离卷积降低网络计算复杂度。结果 基于 CamVid 数据集的对比实验显示,优化后网络的 MIoU 分数达到了 71.03%,在像素精度、平均像素精度 等其他方面的评价指标上较原网络有小幅提升,并且网络参数量降低了 12%。在 Cityscapes 的测试数据 集上的 MIoU 分数为 75.1%。结论 实验结果表明,优化后的网络能够有效提取图像特征信息,提高语 义分割精度,同时降低模型复杂度。文中网络使用城市道路场景数据集进行测试,可以为今后的无人驾 驶技术的应用提供参考,具有一定的实际意义。
引言
整体框架设计采用精度较高的 DeepLabv3+ 的网络结构,在主干网络进行特征提取的过程中增加基于通道和空间信息的注意力机制模块,引入密集空洞空间金字塔池化(Dense Atrous Spatial Pyramid Pooling, DASPP),该模块能充分利用不同卷积率得到特征图的语义信息,获得更大的 密集特征以及感受野,使得图像分割更加精细和平滑。使用深度可分离卷积替换原始的普通卷积,在减少计算量的同时加快了训练网络的收敛速度。
网络架构
1.1DeepLabv3+ 网络的基本原理
DeepLabv3+ 网络基于编码解码器架构,见图 1。(详情请参考这篇博客:deeplabv3+网络)
编码器部分,输入图像会经过骨干网络的下采样而生 成高级语义特征图,此后特征图像进入 ASPP 模块。ASPP 模块由 3 个空洞率分别为 6,12,18 的空洞卷 积、1 个 1×1 的卷积和 1 个全局平均池化层构成。然 后将获得的 5 个特征图在通道上直接进行级联完成 多尺度的采样过程,并经过 1 个 1×1 的卷积实现通道 数的降维( 详情请参考这篇博客:ASPP模块)
解码器部分将骨干网络中 4 倍下采样获得的低级语义特征图进行 1×1 卷积处理完成通道数的降维,之后与编码器通过 4 倍上采样得到的特征图像 进行连接,完成图像低级语义信息与高级语义信息之间的融合,增强网络分割图像的能力。再用 3×3 的卷 积提取融合图的特征,最后再次进行 4 倍上采样,输出预测的分割图像。

图1.Deeplabv3+网络模型
1.2 优化的网络
1.在骨干网络的下采样模块之间添加注意力机制模块
2.引入 DASPP 模块来替代图 1 中的 ASPP 模块
3.使用深度可分离卷积替换普通卷积,即原有的 1×1 卷积替换为 1×1 深度可分离卷积, 3×3 卷积换为 3×3 深度可分离卷积,并且对引入的 DASPP 模块的空洞卷积也进行替换
1.3 注意力机制模块
首先对输入的特征图分别进行基于高度与宽度上的全局平均池化和全局最大池化,之后再分别 通过多层感知器(Multi-Layer Perceptron, MLP)将获 得的输出特征进行基于元素的对位相加处理。接下来使用 sigmoid 函数激活,生成通道注意力特征。然后将输入的特征图与该通道注意 力特征作点乘处理,从而获得空间注意力模块所需的输入特征
Mc(F)=Sigmoid(MLP(AvgPool(F)+MLP(MaxPool(F))))
将通道注意力模块输出的特征图用作空间注意 力模块的输入特征图,随后分别进行全局最大池化和 全局平均池化处理,获得上述的 2 个结果后根据通道 信息做连接。之后使用一个 7×7 的卷积将连接的结果 降成 1 个通道。再使用 sigmoid 函数激活得到空间注 意力特征,最后将输入的特征图 与该空间注意力特征作点乘,获得最终的空间注意力 特征。
Ms(F)=Sigmoid( 7 7 f ([AvgPool(F); MaxPool(F)]))
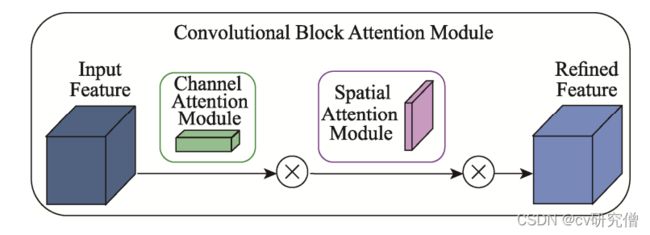
图3.注意力机制模块
1.4 密集空洞空间金字塔池化模块
充分地利用多尺度信息可以有效提高对不同目 标的分割能力。
DASPP 通过密集连接的方式将每个空洞卷积层的输出结果传递到在此之后的所有未被访问过的空洞卷积层,每个空洞卷积层只使用有合理膨胀率(d≤24)的空洞滤波器。通过一系列的空洞卷积组合,处于结构较后层的神经元会得到越来越大的感受野,同时不会出现卷积核退化的问题。经过前面的特征组合,每个提取特征的神经元都 能获得多个尺度的信息,不同的神经元编码来自不同尺度范围的多尺度信息,于是 DASPP 输出的最终特征图以非常密集的方式覆盖了大规模范围内的语义信息。
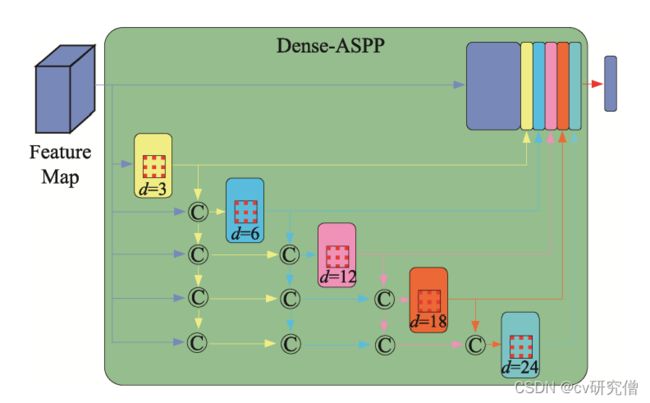
图4.Dense-ASPP 模块
1.5 深度可分离卷积模块
深度可分卷积分为两部分,首先使用给定的卷积核尺寸对每个通道分别卷积并将结果组合,该部分被称为depthwise convolution,随后深度可分卷积使用单位卷积核进行标准卷积并输出特征图,该部分被称为pointwise convolution。可以参考这篇博客:深度可分卷积