论文笔记:基于遮挡掩模和边缘感知的自监督单目深度估计
基于遮挡掩模和边缘感知的自监督单目深度估计
关键词:单目深度估计,自然图像, 自监督任务
一、来源
Artificial Life and Robotics
Published: 26 May 2021
链接:https://link.springer.com/article/10.1007/s10015-021-00685-z
二、标题
Self‑supervised monocular depth estimation with occlusion mask and edge awareness
三、作者及单位
Shi Zhou, Miaomiao Zhu, Zhen Li, He Li, Mitsunori Mizumachi & Lifeng Zhang
日本九州理工学院,东北大学
四、方法简介
本文提出使用基于遮挡掩模和边缘感知的自监督单目深度估计算法。首先,同时使用DepthNet进行深度估计和使用PoseNet进行姿态传输的自监督训练方案。然后,根据相邻两帧之间的差值,提出了遮挡掩码算法来更好地指导网络的训练。引入传统拉普拉斯方法获得的边缘,增强了对不同光照条件的鲁棒性。最后,对最后的训练损失进行了解释。
网络结构
本文主要的网络结构如下图所示。

DepthNet和PoseNet的架构如图(a)所示。整个框架构成了自监督学习方式。其中, I t 、 I t ′ I_{t}、I_{t^{'}} It、It′分别代表当前帧和相邻帧, D t D_{t} Dt 代表深度估计结果, T t ′ − t T_{t^{'}-t} Tt′−t 代表位姿传输结果, I t ′ − t I_{t^{'}-t} It′−t 代表从相邻帧重建当前帧的结果。
通过编码器部分提取当前帧的特征。然后将四个不同比例的深度图结合相同比例的边缘图像(由传统拉普拉斯算法计算出),然后再上采样到相同的尺寸,最后一个卷积层后输出最终的深度估计图。在网络训练时,将当前帧和相邻帧同时输入到网络中,然后从PoseNet网络中估计当前帧和相邻帧之间的姿态传输。根据姿态传输和深度映射,可以将相邻帧变形为当前帧,公式如下所示。 K K K 代表相机的内在参数。
I t ′ − t = p r o j ( I t ′ , D , T t − t ′ , K ) I_{t^{'}-t}=proj(I_{t^{'}},D,T_{t-{t^{'}}},K) It′−t=proj(It′,D,Tt−t′,K)
在测试时,只需要使用当前帧图像和DepthNet网络,进行深度估计。
损失函数
光重投影损失 L p L_{p} Lp 是像素空间 L 1 L_{1} L1 距离和结构相似性(SSIM)的组合:

当摄像机向前移动时,每一帧的视场都在改变,当前帧中的所有信息都可以在前一帧中找到,而周围的信息在下一帧中会被抹去。因此,对于当前帧,前一帧和下一帧之间存在差异,然而,现有的自监督单目深度估计方法都采用相同的方法计算前帧和下帧的损失。这可能会对位于周围区域的像素造成问题,并干扰两个网络的训练。为了消除下一帧在边界区域的影响,遮挡掩模将图像中的像素分为两类:遮挡像素和非遮挡像素。对于位于前一帧 I t − 1 I_{t-1} It−1 的像素p,可以重新投影到当前帧。如果对应的像素q位于当前帧中,则为非遮挡像素,否则为遮挡像素。因为下一帧的所有对象都可以在当前帧中找到,所以这个操作只在前一帧中执行。对于不同的像素,计算不同的光度重投影损失,得到更好的深度图。
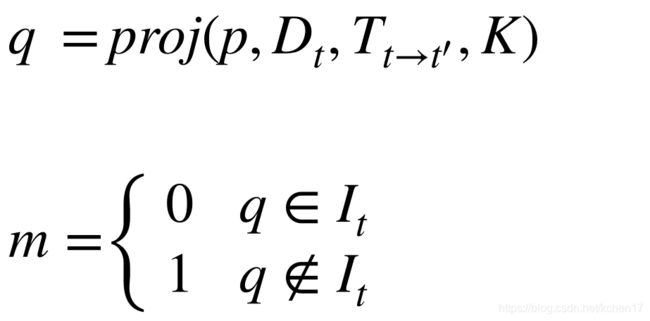
对于当前帧中的任何非遮挡像素,它可以在两个相邻帧中的至少一个中查看。我们在相邻两帧之间取最小的光度重投影损失,以提高遮挡周围区域的精度。对于当前帧中的任何遮挡像素,该方法只考虑当前帧和前一帧的信息,并考虑光度重投影损失。在不干扰下一帧遮挡像素的情况下,可以提高遮挡区域和非遮挡区域的精度。

对于无纹理区域的像素,它们的强度非常接近,甚至没有差异,所以这些像素的深度会被错误的估计。然而,一些传统的平滑方法虽然容易修正错误的深度,但也会平滑物体的边缘。因此,这是深度估计中的一个难题。传统方法和深度学习方法都不能很好地解决这一问题。为了惩罚平面区域的突然深度变化,鼓励物体边缘区域的深度不连续,以往的作品都是基于图像的梯度来惩罚平面区域的这种突然变化,不同的光照条件对梯度的影响很大。不同的是,我们采用了传统方法获得的基于边缘的边缘感知。其中 D t ∗ = D t D t ˉ D_{t}^{*}=\frac{D_{t}}{\bar{D_{t}}} Dt∗=DtˉDt

二进制掩码用于将所有像素划分为两个类。如果对应的像素在相邻帧之间是一致的,这将表明相机是静态的,或物体是以相同的速度移动的相机,一个静止的掩模被设计来忽略这些像素
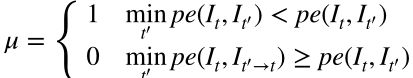
为了提高深度图的精度,最终的训练损失是边缘感知损失 L s L_{s} Ls 和光度重投影损失 L p L_{p} Lp 的结合。
L = μ L p + λ L s L=\mu L_{p}+\lambda L_{s} L=μLp+λLs
五、实验数据
KITTI数据集
最后使用39810帧进行训练,4424帧进行验证,697帧进行测试。当训练这些网络时,所有帧都使用相同的固有焦距和平均焦距。
六、主要结果

单目深度估计结果优于其他方法。
遮挡的好处用遮挡遮挡标注下一帧中将要被扭曲的区域,以消除周围遮挡区域的影响。本文提出的带遮挡掩模的方法只考虑周围区域的帧t和t−1的信息,而考虑其他区域的前中后所有三帧的信息,可以更好地预测周围区域的深度图。
鼓励平面区域的深度平滑,允许物体边界的深度不连续,从而使网络能够学习到更多有语义意义的边缘信息。利用边缘感知,可以在深度图中估计出更清晰的目标边缘。