视频理解论文精读系列目录【更新中】
目录
0、Introduction
1、ConvNet+LSTM
2、Two-Stream Convolutional Networks
2.1 双流网络泛读
3、3D ConvNets
3.1 C3D泛读
4、Temporal Segment Networks
4.1TSN泛读:
5、Two-Stream Inflated 3D ConvNets
5.1 I3D泛读
6、Temporal Shift Module
6.1TSM泛读
7、SlowFast Networks
7.1 SlowFast泛读
8、VTN(Video Transformer Network)
9、ViViT: A Video Vision Transformer
10、TimeSformer
10.1 TimeSformer泛读:
0、Introduction
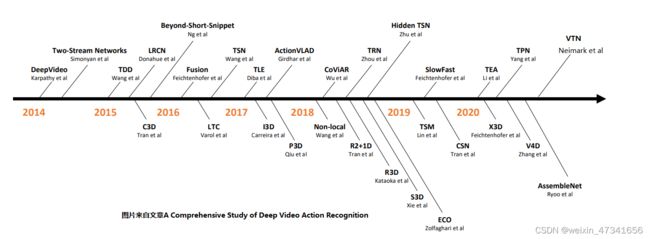
本文主要介绍基于深度学习的视频理解模型,传统手工特征模型会在涉及到时补充,手工特征方法一般出现在2014年之前的文章里(手工特征对深入学习这个领域很重要)。本系列主要介绍视频理解影响力较大的深度学习网络模型,每个模型的论文分为泛读、精读、总结和验证四个部分。有一篇2020年的综述文章可做参考( A Comprehensive Study of Deep Video Action Recognition-2020年12月),2021之后主要是将transformer引入到网络中,视频transformer可参考综述文章(Video Transformers: A Survey-2022年1月)。
A Comprehensive Study of Deep Video Action Recognition论文下载:
https://arxiv.org/pdf/2012.06567.pdf https://arxiv.org/pdf/2012.06567.pdf
https://arxiv.org/pdf/2012.06567.pdf
Video Transformers: A Survey论文下载:
https://arxiv.org/pdf/2201.05991.pdfhttps://arxiv.org/pdf/2201.05991.pdf
1、ConvNet+LSTM
ConvNet+LSTM论文下载:
Long-term Recurrent Convolutional Networks for Visual Recognition and Description https://openaccess.thecvf.com/content_cvpr_2015/papers/Donahue_Long-Term_Recurrent_Convolutional_2015_CVPR_paper.pdf
https://openaccess.thecvf.com/content_cvpr_2015/papers/Donahue_Long-Term_Recurrent_Convolutional_2015_CVPR_paper.pdf
待续...
2、Two-Stream Convolutional Networks
双流网络论文下载:Two-Stream Convolutional Networks for Action Recognition in Videoshttps://proceedings.neurips.cc/paper/2014/file/00ec53c4682d36f5c4359f4ae7bd7ba1-Paper.pdf
2.1 双流网络泛读
https://blog.csdn.net/weixin_47341656/article/details/124117023https://blog.csdn.net/weixin_47341656/article/details/124117023
待续...
3、3D ConvNets
C3D论文下载:https://openaccess.thecvf.com/content_iccv_2015/papers/Tran_Learning_Spatiotemporal_Features_ICCV_2015_paper.pdfhttps://openaccess.thecvf.com/content_iccv_2015/papers/Tran_Learning_Spatiotemporal_Features_ICCV_2015_paper.pdf
3.1 C3D泛读
https://blog.csdn.net/weixin_47341656/article/details/124152947https://blog.csdn.net/weixin_47341656/article/details/124152947待续...
4、Temporal Segment Networks
TSN论文下载:Temporal Segment Networks: Towards Good Practices for Deep Action Recognitionhttps://arxiv.org/pdf/1608.00859.pdf
4.1TSN泛读:
TSN泛读【Temporal Segment Networks: Towards GoodPractices for Deep Action Recognition】_weixin_47341656的博客-CSDN博客TSN泛读【Temporal Segment Networks: Towards GoodPractices for Deep Action Recognition】https://blog.csdn.net/weixin_47341656/article/details/124278722
5、Two-Stream Inflated 3D ConvNets
I3D论文下载:Quo Vadis, Action Recognition? A New Model and the Kinetics Datasethttps://openaccess.thecvf.com/content_cvpr_2017/papers/Carreira_Quo_Vadis_Action_CVPR_2017_paper.pdf
5.1 I3D泛读
https://blog.csdn.net/weixin_47341656/article/details/124152968https://blog.csdn.net/weixin_47341656/article/details/124152968
待续...
6、Temporal Shift Module
TSM论文下载:
TSM: Temporal Shift Module for Efficient Video Understandinghttps://openaccess.thecvf.com/content_ICCV_2019/papers/Lin_TSM_Temporal_Shift_Module_for_Efficient_Video_Understanding_ICCV_2019_paper.pdf
6.1TSM泛读
TSM泛读【TSM: Temporal Shift Module for Efficient Video Understanding】_weixin_47341656的博客-CSDN博客TSM泛读【TSM: Temporal Shift Module for Efficient Video Understanding】https://blog.csdn.net/weixin_47341656/article/details/124279298
7、SlowFast Networks
SlowFast论文下载:
SlowFast Networks for Video Recognitionhttps://openaccess.thecvf.com/content_ICCV_2019/papers/Feichtenhofer_SlowFast_Networks_for_Video_Recognition_ICCV_2019_paper.pdf
7.1 SlowFast泛读
SlowFast泛读【SlowFast Networks for Video Recognition】_weixin_47341656的博客-CSDN博客SlowFast泛读【SlowFast Networks for Video Recognition】https://blog.csdn.net/weixin_47341656/article/details/124286797
8、VTN(Video Transformer Network)
VTN(Video Transformer Network)论文下载:
https://arxiv.org/pdf/2102.00719.pdfhttps://arxiv.org/pdf/2102.00719.pdf
9、ViViT: A Video Vision Transformer
ViViT论文原文下载:
https://arxiv.org/pdf/2103.15691.pdfhttps://arxiv.org/pdf/2103.15691.pdf
10、TimeSformer
TimeSFormer论文下载:Is Space-Time Attention All You Need for Video Understanding?https://arxiv.org/pdf/2102.05095.pdf
10.1 TimeSformer泛读:
TimeSformer泛读【Is Space-Time Attention All You Need for Video Understanding?】_weixin_47341656的博客-CSDN博客泛读我们主要读文章标题,摘要、结论和图表数据四个部分。需要回答用什么方法,解决什么问题,达到什么效果这三个问题。需要了解更多视频理解相关文章可以关注视频理解系列目录了解当前更新情况。https://blog.csdn.net/weixin_47341656/article/details/124253776
待续...
Multiscale Vision Transformers
CoAtNet: Marrying Convolution and Attention for All Data Sizes
Multiview Transformers for Video Recognition
专题待续。。。