【EasyRL强化学习学习笔记】01_相关原理与概述
文章目录
-
- 本章笔记主要内容
- 关键词
- 相关参数定义
- 1 强化学习与监督学习
-
- 1.1 简单介绍
- 1.2 二者区别
- 1.3 强化学习特征
- 1.4 强化学习发展
- 2 强化学习基本原理
-
- 2.1 动作
- 2.2 奖励
- 2.3 状态与观测
- 2.4 策略、价值函数与模型
-
- 2.4.1 策略
- 2.4.2 价值函数
- 2.4.3 模型
- 2.5 智能体与环境
-
- 2.5.1 根据学习对象分类
- 2.5.2 根据是否有学习环境模型分类
- 2.7 探索与利用
- 3 一些实验例子
-
- 3.1 Gym库的安装
- 3.2 例1:CartPol_v0(平衡车)
- 3.3 例2:MountainCar_v0(小车上山)
本章笔记主要内容
这一章的内容,对应磨菇书《EasyRL》第一章的内容。首先对于关键词和相关参数进行了阐述,然后着重介绍了强化学习与监督学习的区别、强化学习的基本原理以及Gym库相关的两个小实验例子。这一章内容更多侧重于对原理的一些理解吧,关于具体算法的内容会在第三章往后展开,下一章讨论MDP过程。
关键词
- 强化学习(Reinforcement learning,RL):让智能体(agent)怎么在复杂、不确定的环境(environment)里面去最大化它能获得的奖励的一种工具方法。
- 深度强化学习(Deep Reinforcement Learning):不需要手动设计特征,仅需要输入状态就可以让系统直接输出动作的一个端到端(end-to-end)的强化学习方法。通常使用神经网络来拟合价值函数(value function)或者策略网络(policy network)。
- 状态(state):智能体观测到当前环境的部分或者全部特征。
- 动作(action):智能体在当前环境下基于当前状态做出的具体行为。
- 动作空间(action space):在当前的环境中,有效动作的集合被称为动作空间。依据智能体的动作数量是否有限可以分为离散动作空间和连续动作空间:智能体的动作数量有限的动作空间称为离散动作空间,反之则被称为连续动作空间。
- 奖励(reward):当智能体在某个状态下完成某一动作后,从环境中获取的反馈信号。
- 探索(exploration):在当前的状态下,智能体继续尝试新的动作。执行新的动作后可能得到更高的奖励,也有可能一无所有。
- 利用(exploitation):在当前的状态下,智能体继续重复尝试已经试验过可以获得最大奖励的过程。
- 基于策略(policy-based)的方法:智能体会制定一套动作策略,即确定在给定状态下需要采取何种动作,并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。
- 基于价值(valued-based)的方法:智能体不需要制定策略,它负责构建和更新一个价值表格或者价值函数,并通过这个价值表格或价值函数来执行使得价值最大化的动作。
- 有模型(model-based):智能体通过学习状态的转移来进行决策。
- 免模型(model-free):智能体没有直接估计状态的转移,没有得到环境的具体转移变量,它通过学习价值函数或者策略网络进行决策。
相关参数定义
| a a a | 动作 |
|---|---|
| s s s | 状态 |
| r r r | 奖励 |
| π π π | 策略 |
| π ( s ) π(s) π(s) | 确定性策略 π 在状态 s 选取的动作 |
| γ \gamma γ | 折扣因子 |
| G t G_t Gt | 时刻t 时的回报 |
| π θ π_θ πθ | 参数 θ 对应的策略 |
1 强化学习与监督学习
在本节中,主要会去讨论强化学习与机器学习中的监督学习的区别,以此来深化对强化学习的定义、特征等基本概念的理解。
1.1 简单介绍
在监督学习中,过程大概如下:第一,输入的数据/标注的数据都应该是没有关联的。如果输入的数据有关联,学习器是不好学习的;第二,我们告诉学习器正确的标签是什么,这样它可以通过正确的标签来修正自己的预测,比如某个图片明明是个汽车,却误认为是飞机,那我们立马告诉它这是错误的;第三,我们根据错误写一个损失函数(loss function),通过反向传播(back propagation)来训练神经网络。
那么在强化学习中,上述的前两个假设基本都不成立。智能体观测到的状态不是独立同分布的,也就是说我们得到的数据很可能是有关联的,比如是相关的时间序列数据等。另外,强化学习中不会立刻得到反馈,比如你玩一个游戏,它并不会直接告诉你哪个动作、哪个策略是正确的。
这边存在一个**延迟奖励(delayed reward)**的过程。玩雅达利游戏的过程中,我们从第 1 步开始,采取一个动作,比如我们把木板往右移,接到球。第 2 步我们又做出动作,得到的训练数据是一个玩游戏的序列。比如现在是在第 3 步,我们把这个序列放进网络,希望网络可以输出一个动作,即在当前的状态应该输出往右移或者往左移。这里有个问题,我们没有标签来说明现在这个动作是正确还是错误的,必须等到游戏结束才可能知道,这个游戏可能 10s 后才结束。现在这个动作到底对最后游戏是否能赢有无帮助,我们其实是不清楚的。这里我们就面临延迟奖励的问题,延迟奖励使得训练网络非常困难。
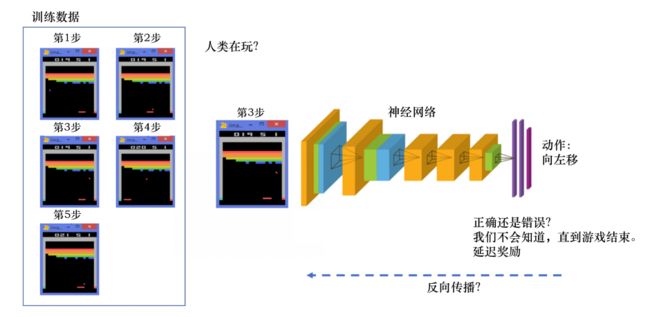
1.2 二者区别
-
强化学习输入的样本是序列数据,而不像监督学习里面样本都是独立的。
-
学习器并没有告诉我们每一步正确的动作应该是什么,学习器需要自己去发现哪些动作可以带来最多的奖励,只能通过不停地尝试来发现最有利的动作。
-
智能体获得自己能力的过程,其实是不断地试错探索的过程。探索(exploration)和利用(exploitation)是强化学习里面非常核心的问题。因此,我们需要在探索和利用之间进行权衡,这也是在监督学习里面没有的情况。
-
在强化学习过程中,没有非常强的监督者(supervisor),只有奖励信号,并且奖励信号是延迟的,即环境会在很久以后告诉我们之前我们采取的动作到底是不是有效的。或许正因为我们没有得到即时反馈,所以智能体使用强化学习来学习就非常困难。当我们采取一个动作后,如果我们使用监督学习,我们就可以立刻获得一个指导,比如,我们现在采取了一个错误的动作,正确的动作应该是什么。而在强化学习里面,环境可能会告诉我们这个动作是错误的,但是它并没有告诉我们正确的动作是什么。而且更困难的是,它可能是在一两分钟过后告诉我们这个动作是错误的。
1.3 强化学习特征
通过与监督学习的比较,我们可以总结出关于强化学习的一些特征:
- 强化学习会试错探索,它通过探索环境来获取对环境的理解。
- 强化学习智能体会从环境里面获得延迟的奖励。
- 在强化学习的训练过程中,时间非常重要。因为我们得到的是有时间关联的数据。而不是独立同分布的数据。
- 智能体的动作会影响它随后得到的数据,这一点是非常重要的。在训练智能体的过程中,很多时候我们也是通过正在学习的智能体与环境交互来得到数据的。所以如果在训练过程中,智能体不能保持稳定,就会使我们采集到的数据非常糟糕。我们通过数据来训练智能体,如果数据有问题,整个训练过程就会失败。所以在强化学习里面一个非常重要的问题就是,怎么让智能体获得奖励信一直稳定地提升并最终保持稳定。
1.4 强化学习发展
标准强化学习:设计特征,然后训练价值函数的过程。标准强化学习先设计很多特征,这些特征可以描述现在整个状态。得到这些特征后,我们就可以通过训练一个分类网络或者分别训练一个价值估计函数来采取动作。
深度强化学习:自从我们有了深度学习,有了神经网络,就可以把智能体玩游戏的过程改进成一个端到端训练的过程。我们不需要设计特征,直接输入状态就可以输出动作。我们可以用一个神经网络来拟合价值函数或策略网络,省去特征工程的过程。
2 强化学习基本原理
在本节中,我们会去介绍强化学习中的智能体及其分类、环境 、奖励、动作、策略、价值函数、模型以及序列决策过程,这部分可以说是强化学习最根本的核心原理部分。
2.1 动作
不同的环境可能存在不同种类的动作。在给定的环境中,有效动作的集合经常被称为动作空间。
- 离散动作空间:智能体的动作数量是有限的。
- 连续动作空间:智能体的动作有无数可能,动作是实值的向量。
- 举例:机器人路径规划问题中,若机器人的移动方式只有前后左右四种方式的话那么为离散动作空间;若机器人可以向任意角度任意方向移动,则动作空间为连续空间。
2.2 奖励
- 奖励是由环境给的一种标量的反馈信号,这种信号可显示智能体在某一步采取某个策略的表现如何。
- 强化学习的目的就是最大化智能体可以获得的奖励,智能体在环境里面存在的目的就是最大化它的期望的累积奖励。
2.3 状态与观测
在与环境的交互过程中,智能体会获得很多观测。
状态是对当前环境的完整描述,不会隐藏环境的信息。观测是对状态的部分描述,可能会遗漏一些信息。
当智能体能够观察到环境的所有状态时,我们称这个环境是完全可测的,此时强化学习可以建模为马尔可夫决策过程的问题。(关于马尔科夫决策我们将在下一章学习)
但是智能体经常得到的观测不是所有状态,例如在玩雅达利游戏时,观测到的只是当前电视上面这一帧的信息,我们并没有得到游戏内部里面所有的运作状态。此时我们称环境是部分可测的。那么建模过程就转化为部分可观测马尔可夫决策过程。该过程依旧具有马尔可夫性质。部分可观测马尔可夫决策过程可以用一个七元组描述:(S, A, T, R, Ω, O, γ)。其中 S 表示状态空间,为隐变量,A 为动作空间,T(s′|s, a) 为状态转移概率,R 为奖励函数,Ω(o*|*s, a) 为观测概率,O 为观测空间,γ 为折扣因子。
2.4 策略、价值函数与模型
2.4.1 策略
智能体利用策略来选取下一步的动作。策略是一个函数,它能够把输入的状态变成动作。策略可分为两种:随机性策略和确定性策略。
-
随机性策略:
输入一个状态 s,输出一个概率。这个概率是智能体所有动作的概率,然后对这个概率分布进行采样,可得到智能体将采取的动作。比如可能是有 0.7 的概率往左,0.3 的概率往右,那么通过采样就可以得到智能体将采取的动作,即π 函数,公式表达为:
π ( a ∣ s ) = p ( a t = a ∣ s t = s ) π(a|s) = p (a_t = a|s_t = s) π(a∣s)=p(at=a∣st=s) -
确定性策略:
智能体直接采取最有可能的动作,即:
a ∗ = a r g a m a x π ( a ∣ s ) a^∗ = arg_a maxπ(a | s) a∗=argamaxπ(a∣s)
强化学习大多采用随机策略,这样可以更好地探索环境:随机性策略的动作具有多样性,这一点在多智能体强化学习中很重要。如果采用确定性策略的智能体总是对同样的状态采取相同的动作,这样就会显得太呆了一些,容易被对手预测到策略。
2.4.2 价值函数
价值函数的值是对未来奖励的预测,我们用它来评估状态的好坏。价值函数里面有一个**折扣因子γ **。
为什么要有折扣因子呢?因为我们希望能在短时间内获取更多的价值。比如我们现在获得1000元和20天后获得1000元,我们肯定希望现在就获得这笔钱,因为我们还可以存到一些稳定利息的理财产品里面(当然存基金的情况就另说了受市场波动太大)。
- 因此我们定义价值函数为:
V π ( s ) = E π [ G t ∣ s t = s ] = E π [ ∑ k = 0 ∞ γ k r t + k + 1 ∣ s t = s ] , 对 于 所 有 的 s ∈ S V_π(s) = E_π [G_t | s_t = s] = E_π[\sum^∞_{k=0}γ_kr_{t+k+1}| s_t = s] , 对于所有的s ∈ S Vπ(s)=Eπ[Gt∣st=s]=Eπ[k=0∑∞γkrt+k+1∣st=s],对于所有的s∈S
价值函数也可以称为V函数。期望 E π E_π Eπ 的下标是 π 函数,π 函数的值可反映在我们使用策略 π 的时候,到底可以得到多少奖励。即从某个状态,按照策略,走到最终状态很多很多次;最终获得奖励总和的平均值。
- 另一种价值函数:Q函数。Q函数中包含两个变量:状态和动作。其定义为:
Q π ( s , a ) = E π [ G t ∣ s t = s , a t = a ] = E π [ ∑ k = 0 ∞ γ k r t + k + 1 ∣ s t = s , a t = a ] Q_π(s,a) = E_π [G_t | s_t = s,a_t = a] = E_π[\sum^∞_{k=0}γ_kr_{t+k+1}| s_t = s,a_t = a] Qπ(s,a)=Eπ[Gt∣st=s,at=a]=Eπ[k=0∑∞γkrt+k+1∣st=s,at=a]
在Q函数中,我们未来可以获得奖励的期望取决于当前的状态和当前的动作。Q 函数是强化学习算法里面要学习的一个函数。与V值不同,Q值和策略并没有直接相关,而与环境的状态转移概率相关,而环境的状态转移概率是不变的。
2.4.3 模型
模型决定的是下一步的状态,下一步状态取决于当前的状态以及当前采取的动作。它由状态转移概率和奖励函数两个部分组成。状态转移概率即:
p s s ′ a = p ( s t + 1 = s ′ ∣ s t = s , a t = a ) p_{s s^{\prime}}^{a}=p\left(s_{t+1}=s^{\prime} \mid s_{t}=s, a_{t}=a\right) pss′a=p(st+1=s′∣st=s,at=a)
奖励函数是指我们在当前状态采取了某个动作可以得到多少的奖励,即:
R ( s , a ) = E [ r t + 1 ∣ s t = s , a t = a ] R(s, a)=\mathbb{E}\left[r_{t+1} \mid s_{t}=s, a_{t}=a\right] R(s,a)=E[rt+1∣st=s,at=a]
当我们有了策略、价值函数和模型 3 个组成部分后,就形成了一个马尔可夫决策过程。
2.5 智能体与环境
智能体一直在与所处的环境进行交互。智能体把它的动作输出给环境,环境取得这个动作后会进行下一步,把下一步的观测与这个动作带来的奖励返还给智能体。这样的交互会产生很多观测,智能体的目的是从这些观测之中学到能最大化奖励的策略。
2.5.1 根据学习对象分类
-
基于价值的智能体
基于价值的强化学习方法中,智能体不需要制定策略,它维护一个价值表格或价值函数,并通过这个价值表格或价值函数来择选价值最大的动作。
应用范围:只能应用在离散环境下(如下棋)
主要算法:Q-Learning算法、Sarsa算法
-
基于策略的智能体
在基于策略的强化学习方法中,智能体会制定一套动作策略(确定在给定状态下需要采取何种动作),并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。
应用范围:无限制
主要算法:策略梯度算法、蒙特卡洛算法
-
二者结合:演员-评判家(Actor-Critic)
同时使用策略和价值评估来做出决策。其中,智能体会根据策略做出动作,而价值函数会对做出的动作给出价值,这样可以在原有的策略梯度算法的基础上加速学习过程,取得更好的效果。
2.5.2 根据是否有学习环境模型分类
-
有模型:通过学习状态的转移来采取动作。
当智能体知道状态转移函数 P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t, a_t) P(st+1∣st,at) 和奖励函数后 R ( s t , a t ) R(s_t, a_t) R(st,at),它就能知道在某一状态下执行某一动作后能带来的奖励和环境的下一状态,这样智能体就不需要在真实环境中采取动作,直接在虚拟世界中学习和规划策略即可。具体流程如下图:
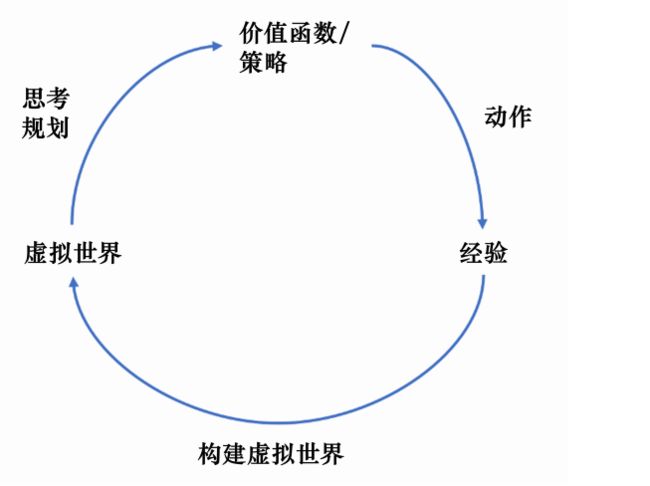
-
免模型:通过学习价值函数和策略函数进行决策。
在大多数实际过程中,智能体并不是那么容易就能知晓马尔可夫决策过程中的所有元素的。通常情况下,状态转移函数和奖励函数很难估计,甚至连环境中的状态都可能是未知的。
免模型强化学习没有对真实环境进行建模,智能体只能在真实环境中通过一定的策略来执行动作,等待奖励和状态迁移,然后根据这些反馈信息来更新动作策略,这样反复迭代直到学习到最优策略。
-
总结
-
有模型强化学习相比免模型强化学习仅仅多出一个步骤,即对真实环境进行建模。
-
在实际应用中,如果不清楚该用有模型强化学习还是免模型强化学习,可以先思考在智能体执行动作前,是否能对下一步的状态和奖励进行预测,如果能,就能够对环境进行建模,从而采用有模型学习。
-
目前,大部分深度强化学习方法都采用了免模型强化学习。
在目前的强化学习研究中,大部分情况下环境都是静态的、可描述的,智能体的状态是离散的、可观察的(如雅达利游戏平台),这种相对简单、确定的问题并不需要评估状态转移函数和奖励函数,可直接采用免模型强化学习,使用大量的样本进行训练就能获得较好的效果。
-
2.7 探索与利用
在强化学习中,探索和利用是两个很核心的问题。
探索就是通过试错来理解采取的动作到底可不可以带来好的奖励。利用是指我们直接采取已知的可以带来很好奖励的动作。所以这里就面临一个权衡问题,即怎么通过牺牲一些短期的奖励来理解动作,从而学习到更好的策略。
以玩游戏为例,利用是指我们总是采取某一种策略。比如,我们玩《拳皇》游戏的时候,采取的策略可能是蹲在角落,然后一直出脚。这个策略很可能可以奏效,但可能遇到特定的对手就会失效。探索是指我们可能尝试一些新的招式,有可能我们会放出“大招”来,这样就可能“一招毙命”。
3 一些实验例子
在这一节中,我将会使用 python 3.7 + pytorch 1.7 来实现书中的一些例子,使用工具为pycharm。
3.1 Gym库的安装
打开pycharm后在编辑器下方点击Terminal,输入 pip install gym ,如下图所示。
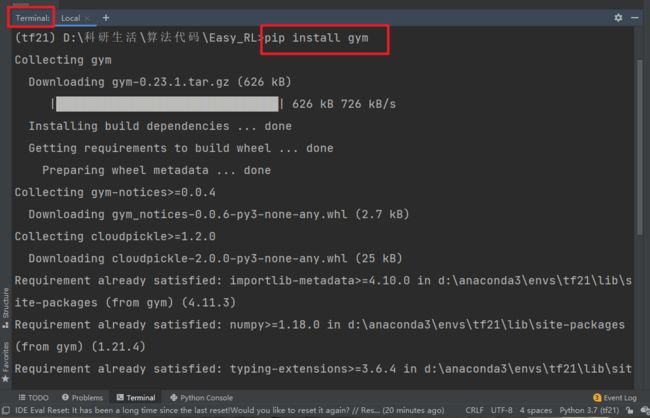
安装完成后,输入一段测试代码测试是否安装成功,具体代码如下:
import gym
env = gym.make('MountainCar-v0')
for i_episode in range(10):
observation = env.reset()
for t in range(50):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()
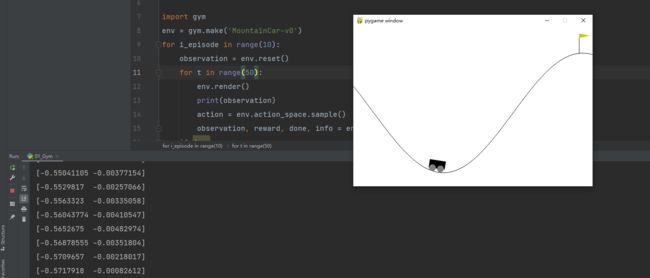
如下图所示,当发现得到一个一直在动的小车,即为安装成功:
3.2 例1:CartPol_v0(平衡车)
如下图所示,我们先去定义相关的动作、观测(状态)以及奖励函数:
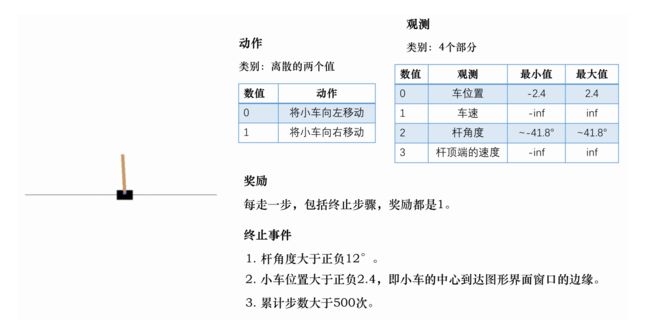
Gym库中的相关参数含义:
-
env.reset():初始化回合
-
env.render():显示环境中的物体图像
-
env.action_space.sample():在该游戏的所有动作空间里随机选择一个作为输出。在这个例子中,动作只有两个:一左一右,输出值即为0或者1。
-
env.step() 方法有 4 个返回值:observation、reward、done、info
observation(object)是状态信息,是在游戏中观测到的屏幕像素值或者盘面状态描述信息。
reward(float)是奖励值,即动作提交以后能够获得的奖励值。
done(boolean)表示游戏是否已经完成。如果完成了,就需要重置并开始一个新的回合。
info(dict)是一些比较原始的用于诊断和调试的信息,或许对训练有帮助。不过,OpenAI 团队在评价你提交的机器人时,是不允许使用这些信息的。 -
env.observation_space:表示环境env的观测空间
-
env.action_space:表示动作空间
在每个训练中都要使用的返回值有 observation、reward、done。特别是observation会由于模型的结构不同而发生变化。下面是CartPol_v0的完整代码:
import gym
env = gym.make('CartPole-v0') # 引入gym库中例子构建实验环境
env.reset() # 重置一个回合
# 训练1000个回合
for _ in range(1000):
env.render() # 显示图形界面
action = env.action_space.sample() # 从动作空间中随机选择一个工作
observation, reward, done, info = env.step(action) # 用于提交具体的动作并获得反馈
print(observation) # 输出观测值
env.close() # 关闭环境
运行结果:
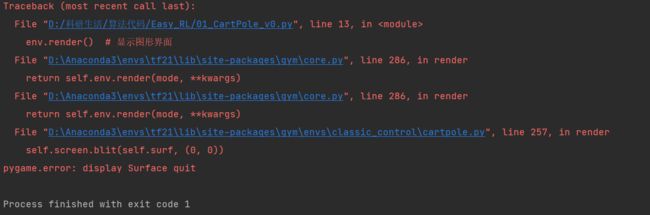
是的,你没看错!我按照书里的代码运行之后报错了,然后我就求助百度,但我搜这个问题并没有搜到很直观的解决方案,于是我去翻了翻OpenAI的源码是可以运行,OpenAI的源码如下:
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample()) # take a random action
env.close()
对比之后我发现可能问题出在观测值上,于是我又翻了翻相关的源码,找到了有观测值的源码:
import gym
env = gym.make('CartPole-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()
所以我的错误应该是在每次回合开始前没有对观测信息初始化。我的理解是:在 Gym仿真中,每一次回合开始,需要先执行 reset() 函数,返回初始观测信息,然后根据done的状态,来决定是否进行下一次回合。所以更恰当的方法是遵守done的标志。这里特别感谢这位老师的讲解,对该例子进行了详实的介绍:OpenAI Gym 经典控制环境介绍——CartPole(倒立摆)_思绪无限的博客-CSDN博客_cartpole-v0
以下是调试成功后的输出界面:
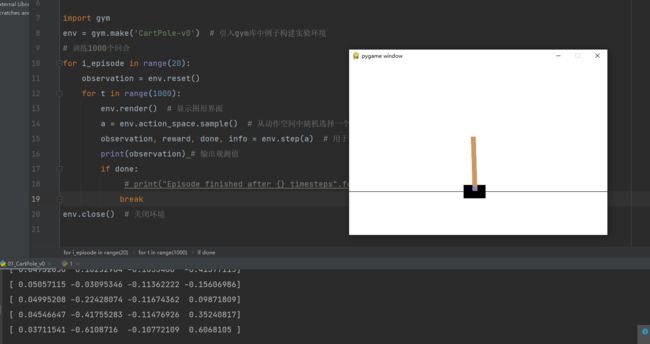
3.3 例2:MountainCar_v0(小车上山)
在本节中,我们学习一下如何自己去定义一个智能体和Gym库进行交互。我们选取MountainCar_v0作为例子。
首先我们来看看这个例子的观测空间和动作空间,如下图所示:
# 查看该任务的观测空间和动作空间
import gym
env = gym.make('MountainCar-v0')
print('观测空间 = {}'. format(env.observation_space))
print('动作空间 = {}'. format(env.action_space))
print('观测范围 = {} ~ {}'. format(env.observation_space.low, env.observation_space.high))
print('动作数 = {}'. format(env.action_space.n))
输出结果为:
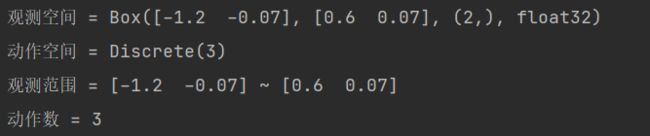
由输出可知,观测空间形状为(2,)的浮点型,动作空间是取0,1,2的int型数值。
在下面的代码中,定义了一个智能体类,其中的decision方法实现了决策功能,learn()方法实现了学习功能。之后让智能体与环境进行交互,并进行图形的界面显示,并得到20回合的平均回合奖励。在下面的代码中进行比较详细的注释,具体代码如下:
import gym
env = gym.make('MountainCar-v0')
# 定义一个智能体与环境进行交互
class Agent:
def __init__(self, env):
pass # 占位作用,让代码完整
# 简单定义智能体的决策,用于演示智能体与环境的交互
def decision(self, observation):
# 定义传入观测值的参数
position, speed = observation
# 用两个算式用来决定动作的选择
lb = min(-0.09 * (position + 0.25) ** 2 + 0.03, 0.3 * (position + 0.9) ** 4 - 0.008)
ub = -0.07 * (position + 0.38) ** 2 + 0.07
if lb < speed < ub:
action = 2
else:
action = 0
return action # 返回动作
# 定义智能体的学习功能
def learn(self, *args):
pass
# 将Agent函数传给agent参数
agent = Agent(env)
# 定义函数让智能体和环境进行交互
def play_car(env, agent, render=False, train=False):
Reward = 0 # 定义回合总奖励,初始化为0
observation = env.reset()
while True:
if render: # 判断图形显示
env.render()
action = agent.decision(observation) # 传入智能体的动作
next_observation, reward, done, _ = env.step(action) # 执行动作
Reward += reward # 收集回合奖励
if train: # 判断是否训练智能体
agent.learn(observation, action, reward, done)
if done: # 回合结束,调出循环
break
observation = next_observation
return Reward
env.close()
# 计算20回合的平均回合奖励
sum_Reward = 0 # 收集回合总奖励
for i in range(20):
Reward = play_car(env,agent, render = True) # 调用play_car函数
sum_Reward += Reward
print('每回合奖励 = {}'.format(Reward))
# print('回合奖励加和 = {}'.format(sum_Reward))
avg_Reward = sum_Reward/20
print('平均回合奖励 = {}'.format(avg_Reward))
输出结果:
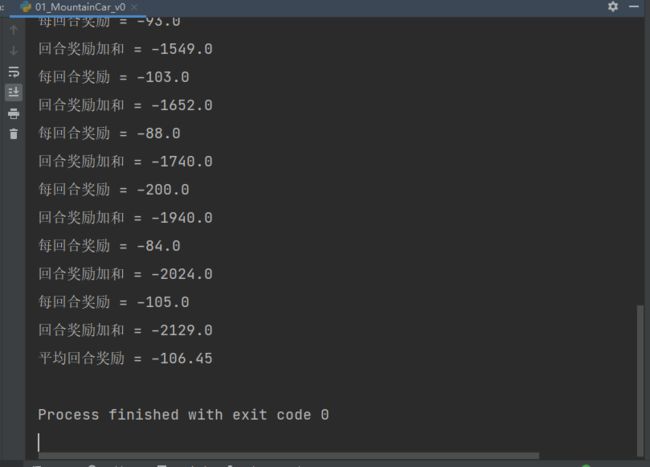
EasyRL编者对 Gym 库的用法进行总结:使用 env=gym.make(环境名) 取出环境,使用 env.reset() 初始化环境,使用 env.step(动作) 执行一步环境,使用 env.render() 显示环境,使用 env.close() 关闭环境。Gym库有对应的官方文档(https://gym.openai.com/docs/),读者可以阅读文档来学习 Gym 库。