PyTorch实现基于ResNet18迁移学习的宝可梦数据集分类
一、实现过程
1、数据集描述
数据集分为5类,分别如下:
- 皮卡丘:234
- 超梦:239
- 杰尼龟:223
- 小火龙:238
- 妙蛙种子:234
自取链接:https://pan.baidu.com/s/1bsppVXDRsweVKAxSoLy4sw
提取码:9fqo
图片文件扩展名有jpg,jepg,png和gif4种类型,并且图片的大小不尽相同,因此需要对所有(训练、验证和测试)的图片做Resize等操作,本文将图像尺寸Resize为224×224大小。
2、数据预处理
本文采用Dataset框架对数据集进行预处理,将图像数据集转换为{images,labels}这样的映射关系。
def __init__(self, root, resize, mode):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
self.name2label = {} # "sq...": 0
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root,name)):
continue
self.name2label[name] = len(self.name2label.keys())
# print(self.name2label)
# image,label
self.images, self.labels = self.load_csv('images.csv')
# 数据集裁剪:训练集、验证集、测试集
if mode == 'train': # 60%
self.images = self.images[0:int(0.6*len(self.images))]
self.labels = self.labels[0:int(0.6*len(self.labels))]
elif mode == 'val': # 20% = 60% -> 80%
self.images = self.images[int(0.6*len(self.images)):int(0.8*len(self.images))]
self.labels = self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))]
else: # 20% = 80% -> 100%
self.images = self.images[int(0.8*len(self.images)):]
self.labels = self.labels[int(0.8*len(self.labels)):]
其中,root表示数据集存放的文件根目录;resize表示数据集输出的统一大小;mode表示读取数据集时的模式(train、val和test);name2label是为了构建图像类别名和标签的字典结构,便于获取图像类别的标签;load_csv方法是创建{images,labels}的映射关系,其中images表示图像所在的文件路径,其代码如下:
def load_csv(self, filename):
if not os.path.exists(os.path.join(self.root, filename)):
# 文件不存在,则需要创建该文件
images = []
for name in self.name2label.keys():
# pokemon\\mewtwo\\00001.png
images += glob.glob(os.path.join(self.root,name,'*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
images += glob.glob(os.path.join(self.root, name, '*.gif'))
# 1168, 'pokemon\\bulbasaur\\00000000.png'
print(len(images),images)
# 保存成image,label的csv文件
random.shuffle(images)
with open(os.path.join(self.root, filename),mode='w',newline='') as f:
writer = csv.writer(f)
for img in images: # 'pokemon\\bulbasaur\\00000000.png'
name = img.split(os.sep)[-2]
label = self.name2label[name]
# 'pokemon\\bulbasaur\\00000000.png', 0
writer.writerow([img, label])
# print('writen into csv file:',filename)
# 加载已保存的csv文件
images, labels = [],[]
with open(os.path.join(self.root,filename)) as f:
reader = csv.reader(f)
for row in reader:
img, label = row
label = int(label)
images.append(img)
labels.append(label)
assert len(images) == len(labels)
return images, labels
获取数据集大小和索引元素位置的代码为:
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
# idx:[0, len(self.images)]
# self.images, self.labels
# img:'G:/datasets/pokemon\\charmander\\00000182.png'
# label: 0,1,2,3,4
img, label = self.images[idx], self.labels[idx]
transform = transforms.Compose([
lambda x: Image.open(x).convert('RGB'), # string path => image data
transforms.Resize((int(self.resize*1.25),int(self.resize*1.25))),
transforms.RandomRotation(15), # 随机旋转
transforms.CenterCrop(self.resize), # 中心裁剪
transforms.ToTensor(),
# transforms.Normalize(mean=[0.485,0.456,0.406],
# std=[0.229,0.224,0.225])
transforms.Normalize(mean=[0.6096, 0.7286, 0.5103],
std=[1.5543, 1.4887, 1.5958])
])
img = transform(img)
label = torch.tensor(label)
return img, label
其中,transforms.Normalize中的mean和std的计算请参考这里,或者直接使用经验值mean=[0.485,0.456,0.406]和std=[0.229,0.224,0.225]。
利用Visdom可视化工具显示的batch_size=32的图像如下图所示:
2、设计模型
本文采用迁移学习的思想,直接使用resnet18分类器,保留其前17层网络结构,对最后一层进行相应修改,代码如下:
trained_model = resnet18(pretrained=True)
model = nn.Sequential(*list(trained_model.children())[:-1], # [b,512,1,1]
Flatten(), # [b,512,1,1] => [b,512]
nn.Linear(512, 5)
).to(device)
其中,Flatten()为数据拉平方法,代码如下:
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, x):
shape = torch.prod(torch.tensor(x.shape[1:])).item()
return x.view(-1, shape)
3、构造损失函数和优化器
损失函数采用交叉熵,优化器采用Adam,学习率设置为0.001,代码如下:
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
4、训练、验证和测试
best_acc, best_epoch = 0, 0
global_step = 0
viz.line([0], [-1], win='loss', opts=dict(title='loss'))
viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc'))
for epoch in range(epochs):
for step, (x,y) in enumerate(train_loader):
# x: [b,3,224,224] y: [b]
x, y = x.to(device), y.to(device)
output = model(x)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
# 验证集
if epoch % 1 == 0:
val_acc = evaluate(model, val_loader)
if val_acc > best_acc:
best_acc = val_acc
best_epoch = epoch
torch.save(model.state_dict(), 'best.mdl')
viz.line([val_acc], [global_step], win='val_acc', update='append')
print('best acc:', best_acc, 'best epoch:', best_epoch+1)
# 加载最好的模型
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evaluate(model, test_loader)
print('test acc:', test_acc)
def evaluate(model, loader):
correct = 0
total = len(loader.dataset)
for (x, y) in loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
output = model(x)
pred = output.argmax(dim=1)
correct += torch.eq(pred, y).sum().item()
return correct/total
5、测试结果
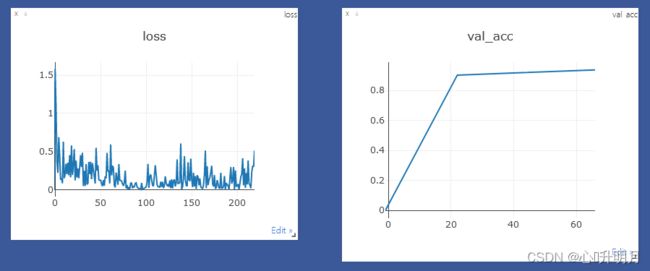
训练集损失值的变化曲线与测试集准确率的变化曲线如下图所示:
 控制台输出结果为:
控制台输出结果为:
best acc: 0.9358974358974359 best epoch: 3
loaded from ckpt!
test acc: 0.9401709401709402
这说明:在epoch=3时,验证集准确率达到最高,此时的模型可认为是最好的模型,将其用于测试集的测试,达到了94.02%的准确率。
二、参考文献
[1] https://www.bilibili.com/video/BV1f34y1k7fi?p=106
[2] https://blog.csdn.net/Weary_PJ/article/details/122765199