卷积网络二:几个典型的卷积神经网络
1 为什么要进行实例探究
上一篇讲了卷积神经网络中的基本组件,卷积层,池化层,全连接层,那么如何把这些基本构件组合起来形成有效的卷积神经网络,找感觉的最好方法之一就是去看一些案例,就像看别人的代码学习编程一样,比如有人已经训练出擅长识别猫狗人的神经网络或神经网络框架,而你的计算机视觉任务是构建一个自动驾驶汽车,你完全可以借鉴别人的神经网络框架来解决自己的问题。
几个经典的网络
了解这些网络,你会对如何构建有效的卷积神经网络更有感觉,即使你不打算构建计算机视觉应用你也能从中找到一些idea对你有用
2 经典网络

LeNet-5是针对灰度图像训练的,所以图片大小只有32×32×1.在那个年代人们喜欢用平均池化,而现在我们用最大池化更多一点。
这个模型中随着层数的加深,W,H都在不断减小,因为当时没有padding。最后用提取出的84个特征来得到最后的输出,比如现在用softmax输出10分类,在当时LeNet-5在输出层使用了另外一种现在已经很少用到的分类器。
这里神经网络的参数约6万个,比起现在的一些神经网络(一千万到一亿个参数)小很多。
第二个介绍的经典网络是AlexNet

same里有padding 第一个same(p=2,s=1)第二个same(p=1,s=1)这个网络大约有6000万个参数
在这片论文之前深度学习已经在语音识别和其他领域获得了一些关注,但是正是通过这篇论文计算机视觉群体开始重视深度学习并确信深度学习可以应用到计算机视觉领域
最后要介绍的是VGG-16
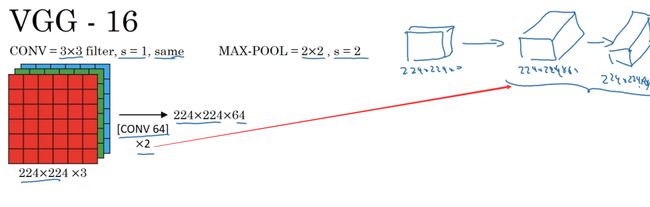
得到两个厚度为64的卷积层,意味着我们用64个卷积核进行了两次卷积
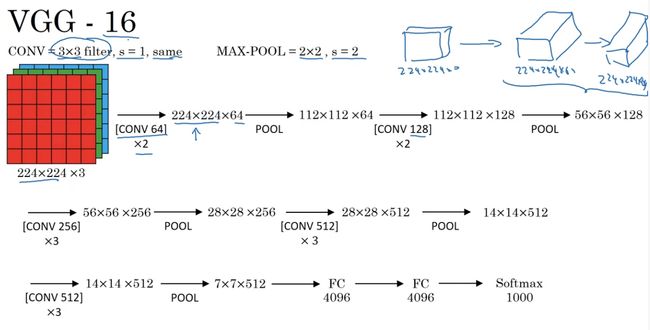
VGG-16 16就是指这个网络包含16个权重层,确实是一个很大的网络总共包含越1.38亿个参数。same卷积s=1,p根据需要填充。
整个结构就是几个卷积后跟着池化,并且卷积核的数量一直在翻倍(绿色部分)
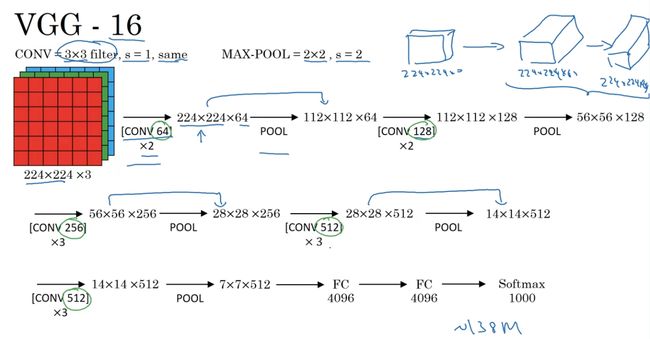
如果你对论文有兴趣,建议从AlexNet开始,然后VGG最后LeNet的论文,对于了解这些网络结构很有帮助
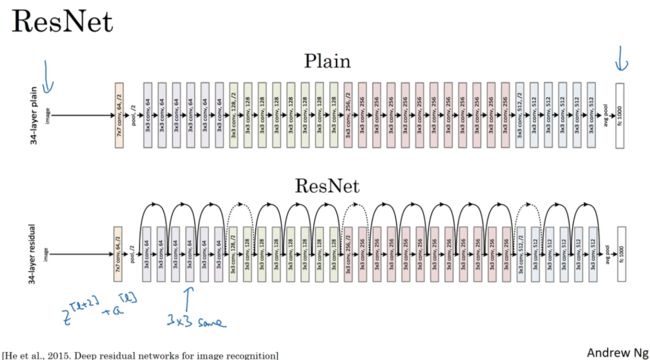
3 残差网络
非常非常深的网络是很难训练的,因为存在梯度消失和梯度爆炸问题,这里介绍skip connections它可以从某一网络层获取激活然后迅速反馈给另外一层,甚至是神经网络的更深层,我们可以利用这种方法构建能够训练深度网络的Resnets网络,有时深度超过100层
一个普通的网络计算如下

在残差网络中有一点变化,直接将 a [ l ] a^{[l]} a[l]传递到后面

残差网络就是这样一个个残差块构建而成的
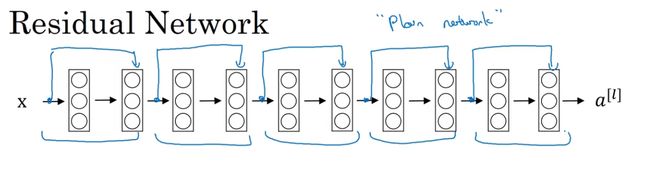
如图5个残差块连接在一起构成一个残差网络。
如果没有使用残差块,随着层数的增加,error逐渐减小然后会在某个点开始上升
对于一个普通的网络来说层数越深意味着用优化算法越难训练,实际上随着网络层数的增加训练误差会越来越大。但是有了resnets就不一样了,即使网络再深训练的效果也不会变差,有人甚至在1000多层的神经网络中做过实验,尽管目前还没有看到太多实际应用。但是对 x的激活,或者这些中间的激活能够到达网络的更深层。这种方式确实有助于解决梯度消失和梯度爆炸问题,让我们在训练更深网络的同时,又能保证良好的性能。也许从另外一个角度来看,随着网络越来深,网络连接会变得臃肿,但是ResNet确实在训练深度网络方面非常有效
4 残差网络为什么有用
我们来看一个例子,它解释了其中的原因,至少可以说明,如何构建更深层次的ResNets网络的同时还不降低它们在训练集上的效率。通常来讲,网络在训练集上表现好,才能在Hold-Out交叉验证集或dev集和测试集上有好的表现,所以至少在训练集上训练好ResNets是第一步。
之前我们了解到,一个网络深度越深,它在训练集上训练的效率就会有所减弱,这也是有时候我们不希望加深网络的原因。但是在resnet上并非如此
为了方便说明,假设我们在整个网络中使用ReLU激活函数,所以激活值都大于等于0。
如果使用L2正则化或权重衰减,它会压缩 W [ l + 2 ] W ^{[l +2]} W[l+2] 的值
结果表明,残差块学习这个恒等式函数并不难,跳跃连接使我们很容易得出 a[l+2]=a[l] 。这意味着,即使给神经网络增加了这两层,它的效率也并不逊色于更简单的神经网络,因为学习恒等函数对它来说很简单。尽管它多了两层,也只把 a [l] 的值赋值给 a [l+2]
不论是把残差块添加到神经网络的中间还是末端位置都不会影响网络的表现。如果这些隐藏单元(残差块)学到一些有用信息那么它可能表现的比恒等函数更好。也就是说性能至少比不加残差的好,也就说不会变得更坏
残差网络的起作用的主要原因就是这些残差学习恒等函数非常容易,你能确定网络性能不会收到影响,很多时候甚至可以提升性能
残差网络另一个值得探讨的细节是,假设 z [ l + 2 ] z^{[l+2]} z[l+2]和 a [ l ] a^{[l]} a[l]有相同的维度,所以resnet使用了许多相同卷积,所以 a [ l ] a^{[l]} a[l]的维度等于输出层( a [ l + 2 ] a^{[l+2]} a[l+2])的维度。
如果输入和输出维度不同,比如输入是128,输出是256,再增加一个矩阵,标记为 W s W_s Ws,维度为256×128的矩阵
最后看看resnets的图片识别
这里有很多3×3的same卷积,解释了 a [ l + 2 ] a^{[l+2]} a[l+2]和 a [ l ] a^{[l]} a[l]的维度问题
esNets类似于其它很多网络,也会有很多卷积层,其中偶尔会有池化层或类池化层的层。不论这些层是什么类型,正如我们在上一张幻灯片看到的,你都需要调整矩阵 W s W_s Ws 的维度。普通网络和ResNets网络常用的结构是:卷积层-卷积层-卷积层-池化层-卷积层-卷积层-卷积层-池化层……依此重复。直到最后,有一个通过softmax进行预测的全连接层。
5 网络中的网络以及1×1的卷积
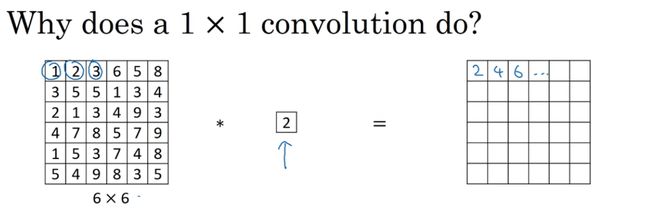
用1×1的过滤器进行卷积,似乎用处不大,只是对输入矩阵乘以某个数字。但这仅仅是对于6×6×1的一个通道图片来说,1×1卷积效果不佳。
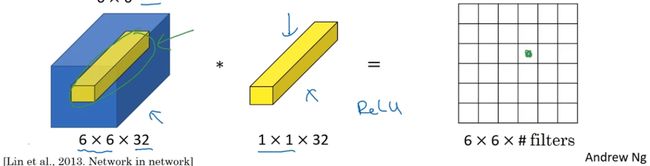
如果是一张6×6×32的图片,那么使用1×1过滤器进行卷积效果更好。1×1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLU非线性函数。
我们以其中一个单元为例,它是这个输入层上的某个切片,用这36个数字乘以这个输入层上1×1切片,得到一个实数(上面右图中的绿色原点表示)。
这个1×1×32过滤器中的32个数字可以这样理解,一个神经元的输入是32个数字(输入图片中左下角位置32个通道中的数字),即相同高度和宽度上某一切片上的32个数字,这32个数字具有不同通道,乘以32个权重(将过滤器中的32个数理解为权重),然后应用ReLU非线性函数,在这里(下图右边黄色点)输出相应的结果。
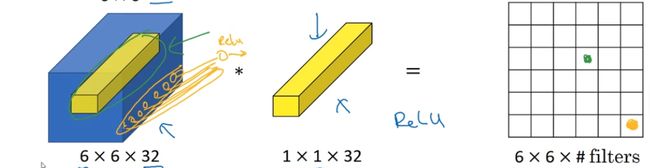
一般来说过滤器不止一个而是多个,就好像有多个输入单元,其输入内容为一个切片上所有数字,输出结果是6×6×filters。所以1×1的卷积可以从本质上理解为这32个单元都应用了一个全连接神经网络。
举个例子这是一个28×28×192的输入层,
你可以使用池化层压缩它的高度和宽度,这个过程我们很清楚。但如果通道数量很大,该如何把它压缩为28×28×32维度的层呢?你可以用32个大小为1×1的过滤器,严格来讲每个过滤器大小都是1×1×192维,因为过滤器中通道数量必须与输入层中通道的数量保持一致。
当然如果你想保持通道数192不变,这也是可行的,1×1卷积只是添加了非线性函数,当然也可以让网络学习更复杂的函数,比如,我们再添加一层,其输入为28×28×192,输出为28×28×192。
1×1卷积层就是这样实现了一些重要功能的,它给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,当然如果你愿意,也可以增加通道数量。
6 谷歌Inception网络简介
构建卷积层时,你要决定过滤器的大小究竟是1×3 ,3×3还是5×5,或者要不要添加池化层。而Inception网络的作用就是代替你来决定,虽然网络架构因此变得更加复杂,但网络表现却非常好,我们来了解一下其中的原理。
这是你28×28×192维度的输入层
Inception网络或Inception层的作用就是代替人工来确定卷积层中的过滤器类型,或者确定是否需要创建卷积层或池化层
注意3×3和5×5的卷积使用same卷积,保持维度不变
或许你不想要卷积层,那就用池化操作,得到一些不同的输出结果,我们把它也堆积起来,这里的池化输出是28×28×32。为了匹配所有维度,我们需要对最大池化使用padding,它是一种特殊的池化形式,因为输入的高度和宽度为28×28,输出的相应维度也是28×28。然后再进行池化,padding不变,步幅为1。这个操作非常有意思,但我们要继续学习后面的内容,一会再实现这个池化过程
有了这样的Inception模块,你就可以输入某个量,因为它累加了所有数字,这里的最终输出为32+32+128+64=256。Inception模块的输入为28×28×192,输出为28×28×256。基本思想是Inception网络不需要人为决定使用哪个过滤器或者是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。
不难发现,所描述的Inception层有一个问题,就是计算成本
我们把重点集中在上面图片中的5×5的过滤器
我们来计算这个28×28×32输出的计算成本问题。它有32个过滤器,因为输出有32个通道,每个过滤器大小为5×5×192,输出大小为28×28×32,
所以你要计算28×28×32个数字。对于输出中的每个数字来说,你都需要执行5×5×192次乘法运算,所以乘法运算的总次数为每个输出值所需要执行的乘法运算次数(5×5×192)乘以输出值个数(28×28×32),把这些数相乘结果等于1.2亿。即使在现在,用计算机执行1.2亿次乘法运算,成本也是相当高的。
这里还有另外一种架构,其输入为28×28×192,输出为28×28×32。其结果是这样的
对于输入层,使用1×1卷积把输入值从192个通道减少到16个通道。然后对这个较小层运行5×5卷积,得到最终输出。请注意,输入和输出的维度依然相同,输入是28×28×192,输出是28×28×32,和上一页的相同。但我们要做的就是把左边这个大的输入层压缩成这个较小的的中间层,它只有16个通道,而不是192个。
中间的这个28×28×16的特征图有时候被称为瓶颈层(瓶颈层是网络中最小的部分)我们先缩小网络表示,然后再扩大它。
接下来我们看看这个计算成本,应用1×1卷积,过滤器个数为16,每个过滤器大小为1×1×192,28×28×16这个层的计算成本是,输出28×28×192中每个元素都做192次乘法,用1×1×192来表示,相乘结果约等于240万。240万只是第一个卷积层的计算成本,第二个卷积层输出是28×28×32,对每个输出值应用一个5×5×16维度的过滤器,计算结果为1000万,所以所需要乘法运算的总次数是这两层的计算成本之和,也就是1240万.
与之前的第一种方法相比(1.2亿)变成了十分之一(1240万)所需要的加法运算与乘法运算的次数近似相等,所以这里只统计了乘法运算的次数。
总结一下,如果你在构建神经网络层的时候,不想决定池化层是使用1×1,3×3还是5×5的过滤器,那么Inception模块就是最好的选择。我们可以应用各种类型的过滤器,只需要把输出连接起来。之后我们讲到计算成本问题,我们学习了如何通过使用1×1卷积来构建瓶颈层,从而大大降低计算成本。你可能会问,仅仅大幅缩小表示层规模会不会影响神经网络的性能?事实证明,只要合理构建瓶颈层,你既可以显著缩小表示层规模,又不会降低网络性能,从而节省了计算。这就是Inception模块的主要思想
7 Inception网络
你已经见到了所有的Inception网络基础模块。在本节中,我们将学习如何将这些模块组合起来,构筑你自己的Inception网络。
Inception模块会将之前层的激活或者输出作为它的输入,作为前提,这是一个28×28×192的输入和之前一样,我们详细分析过的例子是,先通过一个1×1的层,再通过一个5×5的层,1×1的层可能有16个通道,而5×5的层输出为28×28×32,共32个通道,这就是上节最后讲到的我们处理的例子。
为了减少计算量也可以用一个3×3的卷积核做相同操作,这样输出值为28×28×128
或许你想直接一个1×1的卷积或者是3×3池化
为了能在最后将这些输出都连接起来,我们会使用same类型的padding来池化使得输出的高和宽依然是28×28,这样才能将它与其他输出连接起来 。但注意,如果你进行了最大池化,即便用了same padding,3×3的过滤器,stride为1,其输出将会是28×28×192,其通道数或者说深度与输入通道数相同。所以看起来它会有很多通道,我们实际要做的就是再加上一个1×1的卷积层,去进行我们在1×1卷积层的章节里所介绍的操作,将通道的数量缩小,缩小到28×28×32。也就是使用32个维度为1×1×192的过滤器,所以输出的维度其通道数缩小为32。这样就避免了最后输出时,池化层占据所有的通道。
最后,将这些方块全都连接起来。在这过程中,把得到的各个层的通道都加起来,最后得到一个28×28×256的输出。通道连接实际就是之前视频中看到过的,把所有方块连接在一起的操作。这就是一个Inception模块,而Inception网络所做的就是将这些模块都组合到一起。
这是一张取自Szegety et al的论文中关于Inception网络的图片,你会发现图中有许多重复的模块,可能整张图看上去很复杂,但如果你只截取其中一个环节(红框),就会发现这是在前面所见的Inception模块。
所以Inception网络只是很多这些你学过的模块在不同的位置重复组成的网络,所以如果你理解了之前所学的Inception模块,你就也能理解Inception网络。这其中有一些额外的最大池化层(红色向上小箭头)来修改高和宽的维度。
事实上,如果你读过论文的原文,你就会发现,这里其实还有一些分支。这些分支有什么用呢?在网络的最后几层,通常称为全连接层,在它之后是一个softmax层来做出预测。
而这些分支(绿圈)所做的就是通过隐藏层来做出预测。
你应该把它看做Inception网络的一个细节,它确保了即便是隐藏单元和中间层也参与了特征计算,它们也能预测图片的分类。它在Inception网络中,起到一种调整的效果,并且能防止网络发生过拟合。
还有这个特别的Inception网络是由Google公司的作者所研发的,它被叫做GoogleLeNet,这个名字是为了向LeNet网络致敬。
Inception网络这个名字又是缘何而来呢?Inception的论文特地提到了这个梗“We need to go deeper”,论文还引用了这个网址(http://knowyourmeme.com/memes/we-need-to-go-deeper)链接到这幅图片上,如果你看过Inception(盗梦空间)这个电影,你应该能看懂这个由来。作者其实是通过它来表明了建立更深的神经网络的决心,他们正是这样构建了Inception。我想一般研究论文,通常不会引用网络流行模因(梗),但这里显然很合适。
最后总结一下,如果你理解了Inception模块,你就能理解Inception网络,无非是很多个Inception模块一环接一环,最后组成了网络。自从Inception模块诞生以来,经过研究者们的不断发展,衍生了许多新的版本。所以在你们看一些比较新的Inception算法的论文时,会发现人们使用这些新版本的算法效果也一样很好,比如Inception V2、V3以及V4,还有一个版本引入了跳跃连接的方法,有时也会有特别好的效果。但所有的这些变体都建立在同一种基础的思想上,在之前的章节中你就已经学到过,就是把许多Inception模块通过某种方式连接到一起。通过这节,我想你应该能去阅读和理解这些Inception的论文,甚至是一些新版本的论文。
直到现在,你已经了解了许多专用的神经网络结构。在下节,我将会告诉你们如何真正去使用这些算法来构建自己的计算机视觉系统。
8 使用开源的实现方案
你现在已经学过几个非常有效的神经网络和ConvNet架构,在接下来我想与你分享几条如何使用它们的实用性建议,首先从使用开放源码的实现开始。
事实证明很多神经网络复杂细致,因而难以复制,因为一些参数调整的细节问题,例如学习率衰减等等,会影响性能。所以我发现有些时候,甚至在顶尖大学学习AI或者深度学习的博士生也很难通过阅读别人的研究论文来复制他人的成果。幸运的是有很多深度学习的研究者都习惯把自己的成果作为开发资源,放在像GitHub之类的网站上。当你自己编写代码时,我鼓励你考虑一下将你的代码贡献给开源社区。如果你看到一篇研究论文想应用它的成果,你应该考虑做一件事,我经常做的就是在网络上寻找一个开源的实现。因为你如果能得到作者的实现,通常要比你从头开始实现要快得多,虽然从零开始实现肯定可以是一个很好的锻炼。
如果你已经熟悉如何使用GitHub,这段视频对你来说可能没什么必要或者没那么重要。但是如果你不习惯从GitHub下载开源代码,让我来演示一下。

你可以看见很多不同的Resnet的实现,这里打开第一个网址
这是一个ResNets实现的GitHub资源库。在很多GitHub的网页上往下翻,你会看到一些描述,这个实现的文字说明。这个GitHub资源库,实际上是由ResNet论文原作者上传的。
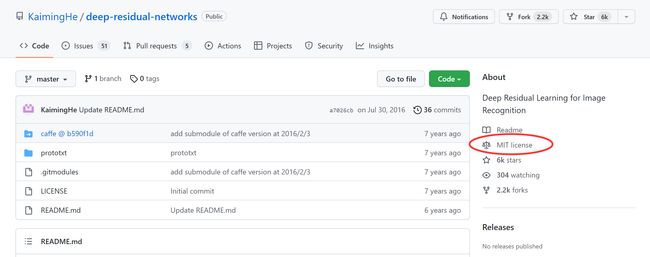
这些代码,这里有麻省理工学院的许可,你可以点击查看此许可的含义,MIT许可是比较开放的开源许可之一。我将下载代码,点击这里的链接,它会给你一个URL,通过这个你可以下载这个代码。
比如
如果你在开发一个计算机视觉应用,一个常见的工作流程是,先选择一个你喜欢的架构,或许是你在这门课中学习到的,或者是你从朋友那听说的,或者是从文献中看到的,接着寻找一个开源实现,从GitHub下载下来,以此基础开始构建。这样做的优点在于,这些网络通常都需要很长的时间来训练,而或许有人已经使用多个GPU,通过庞大的数据集预先训练了这些网络,这样一来你就可以使用这些网络进行迁移学习,我们将在下一节课讨论这些内容。
当然,如果你是一名计算机视觉研究员,从零来实现这些,那么你的工作流程将会不同,如果你自己构建,那么希望你将工作成果贡献出来,放到开源社区。因为已经有如此多计算机视觉研究者为了实现这些架构做了如此之多的工作,我发现从开源项目上开始是一个更好的方法,它也确实是一个更快开展新项目的方法。
9 迁移学习
如果你要做一个计算机视觉的应用,相比于从头训练权重,或者说从随机初始化权重开始,如果你下载别人已经训练好网络结构的权重,你通常能够进展的相当快,用这个作为预训练,然后转换到你感兴趣的任务上。计算机视觉的研究社区非常喜欢把许多数据集上传到网上,如果你听说过,比如ImageNet,或者MS COCO,或者Pascal类型的数据集,这些都是不同数据集的名字,它们都是由大家上传到网络的,并且有大量的计算机视觉研究者已经用这些数据集训练过他们的算法了。有时候这些训练过程需要花费好几周,并且需要很多的GPU,其它人已经做过了,并且经历了非常痛苦的寻最优过程,这就意味着你可以下载花费了别人好几周甚至几个月而做出来的开源的权重参数,把它当作一个很好的初始化用在你自己的神经网络上。用迁移学习把公共的数据集的知识迁移到你自己的问题上,让我们看一下怎么做。
举个例子,假如说你要建立一个猫咪检测器,用来检测你自己的宠物猫。比如网络上的Tigger,是一个常见的猫的名字,Misty也是比较常见的猫名字。假如你的两只猫叫Tigger和Misty,还有一种情况是,两者都不是(neither)。所以你现在有一个三分类问题,图片里是Tigger还是Misty,或者都不是,我们忽略两只猫同时出现在一张图片里的情况。现在你可能没有Tigger或者Misty的大量的图片,所以你的训练集会很小,你该怎么办呢?
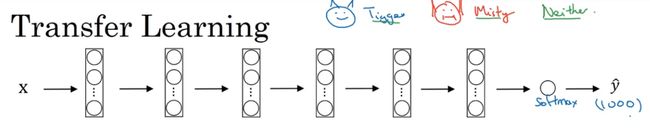
我建议你从网上下载一些神经网络开源的实现,不仅把代码下载下来,也把权重下载下来。有许多训练好的网络,你都可以下载。举个例子,ImageNet数据集,它有1000个不同的类别,因此这个网络会有一个Softmax单元,它可以输出1000个可能类别之一。

你可以去掉这个Softmax层,创建你自己的Softmax单元,用来输出Tigger、Misty和neither三个类别。就网络而言,我建议你把所有的层看作是冻结的,你冻结网络中所有层的参数,你只需要训练和你的Softmax层有关的参数。这个Softmax层有三种可能的输出,Tigger、Misty或者都不是。
通过使用其他人预训练的权重,你很可能得到很好的性能,即使只有一个小的数据集。幸运的是,大多数深度学习框架都支持这种操作,事实上,取决于用的框架,它也许会有trainableParameter=0这样的参数,对于这些前面的层,你可能会设置这个参数。为了不训练这些权重,有时也会有freeze=1这样的参数。不同的深度学习编程框架有不同的方式,允许你指定是否训练特定层的权重。在这个例子中,你只需要训练softmax层的权重,把前面这些层的权重都冻结。
另一个技巧,也许对一些情况有用,由于前面的层都冻结了,相当于一个固定的函数,不需要改变。因为你不需要改变它,也不训练它,取输入图像X ,然后把它映射到这层
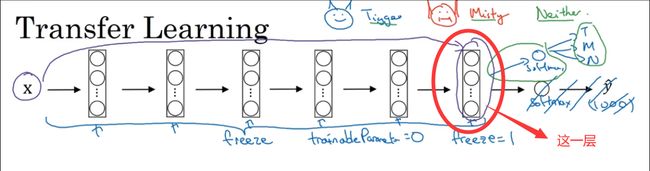
的激活函数。所以这个能加速训练的技巧就是,如果我们先计算这一层(紫色箭头标记),计算特征或者激活值,然后把它们存到硬盘里。你所做的就是用这个固定的函数,在这个神经网络的前半部分,取任意输入图像X,然后计算它的某个特征向量,

这样你训练的就是一个很浅的softmax模型,用这个特征向量来做预测。对你的计算有用的一步就是提前计算你的训练集中所有样本的这一层的激活值,然后存储到硬盘里,然后在此之上训练softmax分类器。所以,存储到硬盘或者说预计算方法的优点就是,你不需要每次遍历训练集再重新计算这个激活值了。
因此如果你的任务只有一个很小的数据集,你可以这样做。要有一个更大的训练集怎么办呢?根据经验,如果你有一个更大的标定的数据集,也许你有大量的Tigger和Misty的照片,还有两者都不是的,这种情况,你应该冻结更少的层,比如只把这些层冻结,然后训练后面的层。
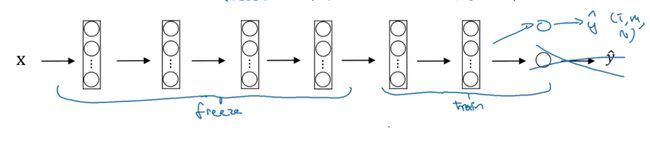
如果你的输出层的类别不同,那么你需要构建自己的输出单元,Tigger、Misty或者两者都不是三个类别。有很多方式可以实现,你可以取后面几层的权重,用作初始化,然后从这里开始梯度下降
或者你可以直接去掉这几层,换成你自己的隐藏单元和你自己的softmax输出层,这些方法值得一试。
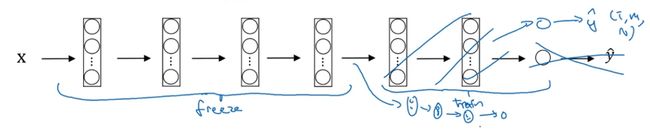
但是有一个规律,如果你有越来越多的数据,你需要冻结的层数越少,你能够训练的层数就越多。这个理念就是,如果你有一个更大的数据集,也许有足够多的数据,那么不要单单训练一个softmax单元,而是考虑训练中等大小的网络,包含你最终要用的网络的后面几层。
最后,如果你有大量数据,你应该做的就是用开源的网络和它的权重,把这、所有的权重当作初始化,然后训练整个网络。

再次注意,如果这是一个1000节点的softmax,而你只有三个输出,你需要你自己的softmax输出层来输出你要的标签。
如果你有越多的标定的数据,或者越多的Tigger、Misty或者两者都不是的图片,你可以训练越多的层。极端情况下,你可以用下载的权重只作为初始化,用它们来代替随机初始化,接着你可以用梯度下降训练,更新网络所有层的所有权重。
这就是卷积网络训练中的迁移学习,事实上,网上的公开数据集非常庞大,并且你下载的其他人已经训练好几周的权重,已经从数据中学习了很多了,你会发现,对于很多计算机视觉的应用,如果你下载其他人的开源的权重,并用作你问题的初始化,你会做的更好。在所有不同学科中,在所有深度学习不同的应用中,我认为计算机视觉是一个你经常用到迁移学习的领域,除非你有非常非常大的数据集,你可以从头开始训练所有的东西。总之,迁移学习是非常值得你考虑的,除非你有一个极其大的数据集和非常大的计算量预算来从头训练你的网络。
10 数据扩充/数据增强
大部分的计算机视觉任务使用很多的数据,所以数据增强是经常使用的一种技巧来提高计算机视觉系统的表现。我认为计算机视觉是一个相当复杂的工作,你需要输入图像的像素值,然后弄清楚图片中有什么,似乎你需要学习一个复杂方程来做这件事。在实践中,更多的数据对大多数计算机视觉任务都有所帮助,不像其他领域,有时候得到充足的数据,但是效果并不怎么样。但是,当下在计算机视觉方面,计算机视觉的主要问题是没有办法得到充足的数据。对大多数机器学习应用,这不是问题,但是对计算机视觉,数据就远远不够。所以这就意味着当你训练计算机视觉模型的时候,数据增强会有所帮助,这是可行的,无论你是使用迁移学习,使用别人的预训练模型开始,或者从源代码开始训练模型。让我们来看一下计算机视觉中常见的数据扩充的方法。

或许最简单的数据扩充方法就是垂直镜像对称,另一种是随机裁剪

随机裁剪并不是一个完美的数据增强方法,不能保证你裁剪的那一部分哪个像猫,但是在实践中还是很实用的。
除了这两种比较常见的还有下面几种
Rotation(旋转)Shearing(对图像进行扭曲变换)Local warping(局部弯曲)当然可以一起使用这些方法,并没有坏处,但是在实践中太复杂了,所以使用的很少
第二种常用的方法是色彩转换,有这样一张图片,然后给R,G,B三通道加上不同的失真值
红色和蓝色会产生紫色,使整张图片看起来偏紫,这样训练集中就有失真的图片。为了演示效果,我对图片的颜色进行改变比较夸张。在实践中,对R、G和B的变化是基于某些分布的,这样的改变也可能很小。
这么做的目的就是使用不同的R、G和B的值,使用这些值来改变颜色。在第二个例子中,
我们少用了一点红色,更多的绿色和蓝色色调,这就使得图片偏黄一点
在这
使用了更多的蓝色,仅仅多了一点红色,在实践中R,G,B的值是根据某种概率分布来决定的。
这么做的理由是,可能阳光会有一点偏黄,或者是灯光照明有一点偏黄,这些可以轻易的改变图像的颜色,但是对猫的识别,或者是内容的识别,以及标签y ,还是保持不变的。所以介绍这些,颜色失真或者是颜色变换方法,这样会使得你的学习算法对照片的颜色更改更具鲁棒性。
下面是一些扩展内容,你可以不掌握
对R、G和B有不同的采样方式,其中一种影响颜色失真的算法是PCA,即主成分分析,我在机器学习的mooc中讲过,在Coursera ml-class.Org机器学习这门课中。但具体颜色改变的细节在AlexNet的论文中有时候被称作PCA颜色增强,PCA颜色增强的大概含义是,比如说,如果你的图片呈现紫色,即主要含有红色和蓝色,绿色很少,然后PCA颜色增强算法就会对红色和蓝色增减很多,绿色变化相对少一点,所以使总体的颜色保持一致。如果这些你都不懂,不需要担心,可以在网上搜索你想要了解的东西,如果你愿意的话可以阅读AlexNet论文中的细节,你也能找到PCA颜色增强的开源实现方法,然后直接使用它。
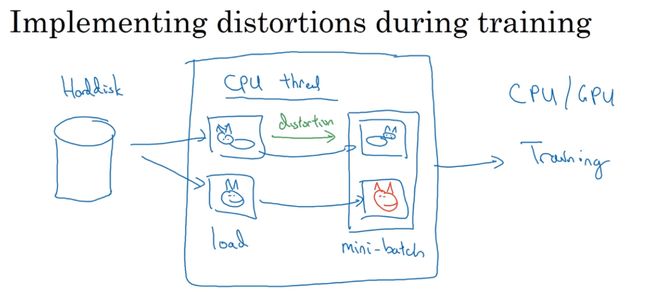
你可能有存储好的数据,你的训练数据存在硬盘上,然后使用符号,这个圆桶来表示你的硬盘。如果你有一个小的训练数据,你可以做任何事情,这些数据集就够了。但是你有特别大的训练数据,接下来这些就是人么经常使用的方法。你可能会使用CPU线程,然后它不停的从硬盘中读取数据,所以你有一个从硬盘过来的图片数据流。你可以用CPU线程来实现这些失真变形,可以是随机裁剪、颜色变化,或者是镜像
与此同时,CPU线程持续加载数据,然后实现任意失真变形,从而构成批数据或者最小批数据,这些数据持续的传输给其他线程或者其他的进程,然后开始训练,可以在CPU或者GPU上实现训一个大型网络的训练。
常用的实现数据扩充的方法是使用一个线程或者是多线程,这些可以用来加载数据,实现变形失真,然后传给其他的线程或者其他进程,读数据和训练,可以并行实现
这就是数据扩充,与训练深度神经网络的其他部分类似,在数据扩充过程中也有一些超参数,比如说颜色变化了多少,以及随机裁剪的时候使用的参数。与计算机视觉其他部分类似,一个好的开始可能是使用别人的开源实现,了解他们如何实现数据扩充。当然如果你想获得更多的不变特性,而其他人的开源实现并没有实现这个,你也可以去调整这些参数。因此,我希望你们可以使用数据扩充使你的计算机视觉应用效果更好。
11 计算机视觉现状
今天我们有相当数量的语音识别数据,至少相对于这个问题的复杂性而言。虽然现在图像识别或图像分类方面有相当大的数据集,因为图像识别是一个复杂的问题,通过分析像素并识别出它是什么,感觉即使在线数据集非常大,如超过一百万张图片,我们仍然希望我们能有更多的数据。还有一些问题,比如物体检测,我们拥有的数据更少。提醒一下,图像识别其实是如何看图片的问题,并且告诉你这张图是不是猫,而对象检测则是看一幅图,你画一个框,告诉你图片里的物体,比如汽车等等。因为获取边框的成本比标记对象的成本更高,所以我们进行对象检测的数据往往比图像识别数据要少。
所以如果你能从机器学习的问题中发散思维,你会发现当你有很多数据的时候,人们倾向于使用更简单的算法和更少的手工工程,因为我们不需要为这个问题精心设计特征。只要有一个大型的神经网络,甚至一个更简单的架构,可以是一个神经网络,只要你有大量数据就可以去学习它想学习的东西。相反当你没有那么多的数据时,那时你会看到人们从事更多的是手工工程(机器学习不期望过多的人工参与)但你没有太多数据时,手工工程实际上是获得良好表现的最佳方式。

所以当我看机器学习应用时,我们认为通常我们的学习算法有两种知识来源,一个来源是被标记的数据,就像( x , y )应用在监督学习。第二个知识来源是手工工程,有很多方法去建立一个手工工程系统,它可以是源于精心设计的特征,手工精心设计的网络体系结构或者是系统的其他组件。所以当你没有太多标签数据时,你只需要更多地考虑手工工程。
所以我认为计算机视觉是在试图学习一个非常复杂的功能,我们经常感觉我们没有足够的数据,即使获得了更多数据,我们还是经常觉得还是没有足够的数据来满足需求。这就是为什么计算机视觉,从过去甚至到现在都更多地依赖于手工工程。我认为这也是计算机视觉领域发展相当复杂网络架构地原因,因为在缺乏更多数据的情况下,获得良好表现的方式还是花更多时间进行架构设计,或者说在网络架构设计上浪费更多时间。
如果你认为我是在贬低手工工程,那并不是我的意思,当你没有足够的数据时,手工工程是一项非常困难,非常需要技巧的任务,它需要很好的洞察力,那些对手工工程有深刻见解的人将会得到更好的表现。当你没有足够的数据时,手工工程对一个项目来说贡献就很大。当你有很多数据的时候我就不会花时间去做手工工程,我会花时间去建立学习系统。但我认为从历史而言,计算机视觉领域还只是使用了非常小的数据集,因此从历史上来看计算机视觉还是依赖于大量的手工工程。甚至在过去的几年里,计算机视觉任务的数据量急剧增加,我认为这导致了手工工程量大幅减少,但是在计算机视觉上仍然有很多的网络架构使用手工工程,这就是为什么你会在计算机视觉中看到非常复杂的超参数选择,比你在其他领域中要复杂的多。实际上,因为你通常有比图像识别数据集更小的对象检测数据集,当我们谈论对象检测时,你会看到算法变得更加复杂,而且有更多特殊的组件。
幸运的是,当你有少量的数据时,有一件事对你很有帮助,那就是迁移学习。我想说的是,在之前的幻灯片中,Tigger、Misty或者二者都不是的检测问题中,我们有这么少的数据,迁移学习会有很大帮助。这是另一套技术,当你有相对较少的数据时就可以用很多相似的数据。
如果你看一下计算机视觉方面的作品,看看那里的创意,你会发现人们真的是踌躇满志,他们在基准测试中和竞赛中表现出色。对计算机视觉研究者来说,如果你在基准上做得很好了,那就更容易发表论文了,所以有许多人致力于这些基准上,把它做得很好。积极的一面是,它有助于整个社区找出最有效得算法。但是你在论文上也看到,人们所做的事情让你在数据基准上表现出色,但你不会真正部署在一个实际得应用程序用在生产或一个系统上
下面是一些有助于在基准测试中表现出色的小技巧
其中一个是集成,这就意味着在你想好了你想要的神经网络之后,可以独立训练几个神经网络,并平均它们的输出。比如说随机初始化三个、五个或者七个神经网络,然后训练所有这些网络,然后平均它们的输出。另外对他们的输出 y ^ \hat{y} y^ 进行平均计算是很重要的,不要平均他们的权重,这是行不通的。看看你的7个神经网络,它们有7个不同的预测,然后平均他们,这可能会让你在基准上提高1%,2%或者更好。这会让你做得更好,也许有时会达到1%或2%,这真的能帮助你赢得比赛。但因为集成意味着要对每张图片进行测试,你可能需要在从3到15个不同的网络中运行一个图像,这是很典型的,因为这3到15个网络可能会让你的运行时间变慢,甚至更多时间,所以技巧之一的集成是人们在基准测试中表现出色和赢得比赛的利器,但我认为这几乎不用于生产服务于客户的,我想除非你有一个巨大的计算预算而且不介意在每个用户图像数据上花费大量的计算。
你在论文中可以看到在测试时,对进准测试有帮助的另一个技巧就是Multi-crop at test time,我的意思是你已经看到了如何进行数据扩充,Multi-crop是一种将数据扩充应用到你的测试图像中的一种形式。

举个例子,让我们看看猫的图片,然后把它复制四遍,包括它的两个镜像版本。有一种叫作10-crop的技术,它基本上说,假设你取这个中心区域,裁剪,然后通过你的分类器去运行它,然后取左上角区域,运行你的分类器,右上角用绿色表示,左下方用黄色表示,右下方用橙色表示,通过你的分类器来运行它,然后对镜像图像做同样的事情对吧?所以取中心的crop,然后取四个角落的crop。如果把这些加起来,就会有10种不同的图像的crop,因此命名为10-crop。所以你要做的就是,通过你的分类器来运行这十张图片,然后对结果进行平均。如果你有足够的计算预算,你可以这么做,也许他们需要10个crops,你可以使用更多,这可能会让你在生产系统中获得更好的性能。
集成的一个大问题是你需要保持所有这些不同的神经网络,这就占用了更多的计算机内存。对于multi-crop,我想你只保留一个网络,所以它不会占用太多的内存,但它仍然会让你的运行时间变慢。
这些是你看到的小技巧,研究论文也可以参考这些,但我个人并不倾向于在构建生产系统时使用这些方法,尽管它们在基准测试和竞赛上做得很好。
由于计算机视觉问题建立在小数据集之上,其他人已经完成了大量的网络架构的手工工程。一个神经网络在某个计算机视觉问题上很有效,但令人惊讶的是它通常也会解决其他计算机视觉问题。
所以,要想建立一个实用的系统,你最好先从其他人的神经网络架构入手。如果可能的话,你可以使用开源的一些应用,因为开放的源码实现可能已经找到了所有繁琐的细节,比如学习率衰减方式或者超参数。
最后,其他人可能已经在几路GPU上花了几个星期的时间来训练一个模型,训练超过一百万张图片,所以通过使用其他人的预先训练得模型,然后在数据集上进行微调,你可以在应用程序上运行得更快。当然如果你有电脑资源并且有意愿,我不会阻止你从头开始训练你自己的网络。事实上,如果你想发明你自己的计算机视觉算法,这可能是你必须要做的。