【图像修复】论文阅读笔记 ----- 《Image inpainting based on deep learning: A review》
文章目录
-
- 原文下载地址
- 概述
- **单阶段修复**
-
- **单结果修复**
- **多元修复方法**
- **渐进图像修复**
-
- 低分辨率图像修复
- 高分辨率图像修复
- 基于先验知识的修复
-
- 轮廓边缘引导图像修复
- 生成性先验引导图像修复
- 用于图像修复的数据集
-
- **不规则掩模数据集:**
- **图像修复数据集:**
- 分析
- **结论**
原文下载地址
原文下载链接1:https://www.sciencedirect.com/science/article/abs/pii/S0141938221000391
原文下载链接2:http://s.dic.cool/S/KSS4D4LC
概述
本篇论文综述发表于2021年。文章总结了基于深度学习的不同类型神经网络结构的修复方法,然后分析和研究了重要的技术改进机制;从模型网络结构和恢复方法等方面对各种算法进行了综合评述。并选择了一些有代表性的图像修复方法进行比较和分析。最后,总结了当前图像修复存在的问题,并展望了未来的发展趋势和研究方向。
当前的图像修复研究主要包括修复矩形块掩模、不规则掩模、目标移除、去噪、移除水印、移除文本、移除划痕和旧照片着色等任务。上述的八个图像修复的任务如下图所示:
传统的图像修复方法
基于补丁和基于扩散的方法,在2014年之前发展。
基于扩散的方法:将图像中受损孔洞周围的像素信息逐渐扩散,并合成新纹理来填充孔洞。
基于补丁的方法:寻找图像的可见区域中搜索最佳匹配的相似面片,然后复制信息以填充像素级的缺失区域。有时候可能在本图像中没有与缺失区域相似的内容,这就需要在现有图像库中搜索与目标受损图像语义相似的图像,然后选择合适的补丁信息进行移植和借用。
基于对抗生成网络的方法
论文将基于对抗生成网络的方法归纳为三类:单阶段修复、渐进图像修复和基于先验知识的修复。
单阶段修复
分为两类:单结果修复方法和多元修复。
单结果修复
(1) Context-encode
模型架构:
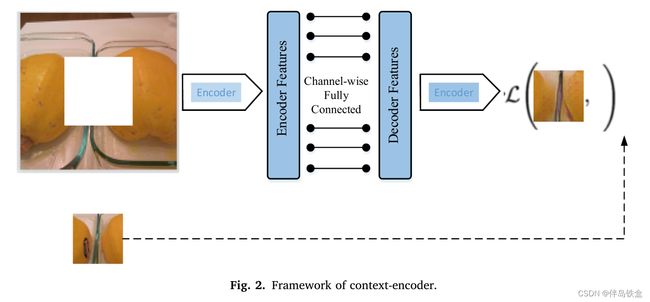
Pathak等人提出了一种名为上下文编码器的图像修复网络,该网络将基于上下文的像素预测驱动的无监督特征学习应用于大孔图像修复。总体架构是一个简单的编码器-解码器。编码器提取输入图像的特征表示,解码器逐步放大压缩的特征图,以恢复原始图像的大小。提出了一种基于步长1卷积的全连通层组跨信道传播信息方法,作为编码器和解码器之间的中间连接,以在每个特征映射的活动内传播信息。
上下文编码器采用重建丢失(L2)和对抗性丢失来处理上下文内的连续性和输出中的多个模式。重建损失负责捕获修复区域的整体结构以及与周围可见区域的一致性,对抗性损失使修复区域的预测看起来真实。
(2)Globally and Locally Consistent
模型架构:
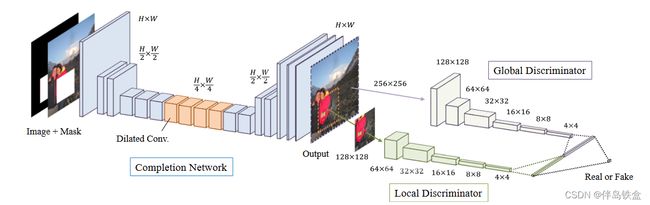
该方法解决了上下文编码器的缺陷(处理固定的低分辨率图像,遮罩区域必须位于图像中心,整个区域无法与周围区域保持局部一致性)。
该网络使用两个辅助上下文鉴别器进行训练,其中全局鉴别器网络将整个图像作为输入,而局部鉴别器仅将完成区域周围的小区域作为输入,以分别确保恢复图像的全局和局部语义。 扩展卷积用于完成网络的中间四层,以增加提取特征的感受野。
(3) Partial Convolutions
在使用标准卷积网络修复受损图像时,通常使用有效像素和缺失部分的平均值作为填充,这容易使大孔修复区域缺乏纹理信息,产生色差和模糊等伪影,严重影响视觉感觉。
Liu等人提出了部分卷积来解决上述问题。在掩模更新过程中,卷积结果取决于每层的非受损区域和对应于受损区域的二进制掩模,通过连续更新足够的层, 最后只保留通过可见区域的像素卷积获得的特征。
(4) Pyramid-context Encoder
Zeng等人提出了金字塔上下文编码器网络(PEN网络),由金字塔上下文编码器、多尺度解码器和对抗性训练损失辅助训练,可以在图像级和特征级填充缺失区域,以提高图像修复能力。
主要的创新点:
-
引入注意力转移网络来学习受损区域和可见区域块之间的高级特征图中的相似性,然后根据块相似性权重将可见区域相关特征转换为低级别高分辨率特征图,以填充缺失内容,从而确保图像恢复的视觉和语义一致性。
-
提出了一种具有金字塔丢失和对抗性丢失深度监控的多尺度解码器。通过跳跃连接,将注意力转移网络学习到的相似特征和潜在特征一起解码以获得修复图像。
(5)PRVS (Progressive Reconstruction of Visual Structure)
PRVS(视觉结构的渐进重建)在部分卷积的基础上引入了视觉结构重建(VSR)层。 编码器和解码器中分别部署了两个VSR层,以生成不同尺度的结构信息。
通过将结构信息逐步合并为特征,基于生成对抗网络输出合理的结构图像,并将转置卷积引入解码器采样层的原始部分卷积层,以解决现有模块部分卷积的局限性。在恢复图像的过程中,使用部分卷积和瓶颈块来恢复缺失区域中的一些边缘,然后将重建的边缘与带孔的输入图像相结合,通过填充语义有意义的内容来逐渐减小孔的大小,最终获得精细的图像修复结果。
**(6)Recurrent Feature Reasoning **
该方法使用相邻像素之间的相关性,增强了估计深像素的约束,重复推断卷积特征图的孔边界,然后将其用作进一步推理的线索。该模块不仅显著提高了网络性能,还绕过了渐进方法的一些限制,即网络的输入和输出需要在同一空间中表示。
提出了知识一致注意(KCA)模块,该模块可以自适应地组合来自不同循环过程的分数,并确保循环中的补丁交换过程之间的一致性,从而获得具有精美细节的更好结果。
(7) Mutual Encoder-Decoder
提出了一种用于结构和纹理联合恢复的互编码器-解码器CNN。使用来自编码器的深和浅CNN特征分别表示输入图像的结构和纹理。编码器深层特征传递到结构分支包含结构语义,而浅层特征传递到纹理分支包含纹理细节。
每个分支将使用CNN特征的多个尺度来填充空洞,连接两个分支的CNN特征,然后首先重新加权信道关注,并使用双边传播激活函数来实现不同CNN特征级别的空间均衡,解码器通过跳过连接生成修复图像。
多元修复方法
(1) Pluralistic Image Completion
在训练阶段,重建路径之一通过使用用于对抗训练的掩模区域的真实原始图像部分来重建整个原始图像,以获得缺失区域的先验分布。另一个生成路径通过使用先验分布来正则化编码器潜在向量所服从的分布,这相当于向编码器潜在向量添加附加约束。正是这种耦合设计策略使得生成路径能够获得个性化的完整图像。
在测试阶段,重建路径被丢弃,生成的路径可以利用有限的条件先验分布修复输入掩模图像,以获得多样化的高质量图像。
(2) UCTGAN
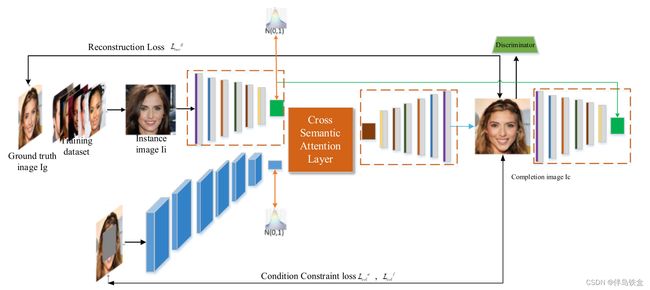
该网络由上下分支组成。主分支由分集映射模块和生成模块组成。主分支负责将实例图像空间映射到条件完成图像空间。次级分支在网络模型中充当条件标签,主要由条件编码器模块组成。在该模型中,通过输入不同的实例图像可以获得不同的修复图像,并且通过鉴别器评估和多个损失的综合评分排序可以返回具有最佳恢复效果的多个图像。
渐进图像修复
分为两类:低分辨率图像修复和高分辨率图像修复
低分辨率图像修复
**(1) Contextual Attention **
Yu等人提出了空间折扣重建损失,以提高大孔修复的视觉质量。它设计了一个从粗到细的两级网络架构,是一种前馈全卷积神经网络,没有批量归一化层。
网络分为两个阶段:
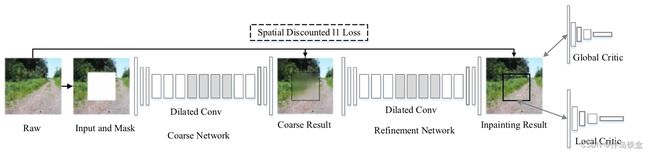
第一级中填充有白色像素的空穴及其相应大小的二进制掩模被用作第一级中的粗网络的输入对。在粗网络中还使用了扩展卷积,以有效地增加感受野大小,并使用重建损耗来稳定训练。
第二阶段中的细网络使用第一阶段中的粗预测作为输入,在精细网络阶段中对全局和局部输出使用改进的WGAN-GP损耗,以增强全局和局部一致性,并结合空间衰减重建损耗共同指导模型训练,从而学习比粗网络更精细的图像细节特征。细网络结构具有两个并行编码器。
上部编码器引入上下文注意层,并使用 可见区域块作为卷积滤波器来处理生成的块,重点是提取感兴趣的背景区域。下部编码器通过扩展卷积来想象缺失区域的内容。在两个编码器的输出被聚合之后,它们被输入到解码器中以重构恢复的图像。

(2) Gated Convolution
门控卷积取代了网络中的传统卷积,更好地解决了将香草卷积中的所有输入视为合法像素的问题,为每个空间位置的每个信道提供了可学习的动态特征选择机制。组合的SN-patchGAN加速了模型训练,并且添加了用户引导,使得新方法能够产生比上下文注意更好的质量和更灵活的修复结果。
(3) Coherent Semantic Attention
Liu等人在粗略和精细阶段都使用了U-Net架构,并提出了一个一致语义注意(CSA)层,重点关注精细网络编码器第四层的空穴区域的语义相关性和特征连续性。
针对感知损失在图像修复中优化卷积层的能力有限的问题,这可能会误导CSA层的训练,引入一致性损失来解决编码和解码阶段相应层特征映射之间的一致性。并引入了与70×70面片鉴别器相结合的特征面片鉴识器,以加速和稳定模型对抗训练,从而使细化网络合成更多的平均高频细节。
**(4) PEPSI **

PEPSI采用了由共享编码网络和具有粗路径和修复路径的并行解码网络组成的结构,可以减少卷积运算的数量,并在很大程度上解决了粗和细网络图像修复占用计算机资源高的问题。 改进了传统的上下文注意模块(CAM)。使用欧几里得距离代替余弦相似度来计算前景块和背景块的相似度分数。引入区域集成鉴别器(RED)分别处理多个特征区域,以解决实际场景中可以处理任意位置、形状和大小的不规则孔洞。
高分辨率图像修复
(1) Contextual Residual Aggregation
Yi 等人所提出的上下文残差聚合机制和在多个抽象级别上使用注意力转移通过融合薄型和深层配置、轻量级门控卷积(LWC)和低层卷积来提高修复质量,注意分数共享等技术设计了一种用于不规则孔洞填充的轻量级模型,可以在不占用大量计算能力的情况下对高分辨率图像进行推理和修复。
(2) Iterative Confidence Feedback and Guided Upsampling
修复过程分为两个阶段。在第一阶段,通过使用从粗到细的级联网络结构获得低分辨率图像的粗修复结果。然后,在细修复阶段,引入修复结果的置信图,以辅助对不满意区域的迭代校正,从而获得细修复结果。第二阶段使用引导修复上采样网络,以在给定第一阶段LR修复结果的情况下生成HR修复图像。引导上采样网络由两个浅层网络组成,一个用于通过patchGAN鉴别器学习块相似性,另一个用于图像重建。
基于先验知识的修复
分为两类:轮廓边缘引导图像修复和生成性先验引导图像修复
轮廓边缘引导图像修复
(1) FAII

FAII(前景感知图像修复)是一种前景感知图像修补模型。如图8所示,该模型首先采用DeepCut检测图像中的前景对象,然后使用边缘检测器提取前景轮廓,然后应用粗和细网络来完成轮廓,最后将完成的轮廓和不完整的图像一起发送到另一个粗和细的网络,最终获得优异的修复结果。
该方法的创新之处在于将图像结构推理和内容完成过程解耦,获得目标物体的自然轮廓,然后将完成的轮廓作为不完整图像的先验引导。提出并验证了使用结构先验来明确指导图像修复任务是一个非常有意义的研究方向。
**(2) EdgeConnect **
该方法分为图像边缘检测和图像完成两个阶段。掩模、带掩模原始图像的灰度图像和边缘图像是边缘生成器的输入,用于预测完整的边缘图。将边缘映射作为先验知识,将带掩模的原始图像作为图像完成网络的输入,得到修复后的图像。
EdgeConnect方法的修复结果:
EdgeConnect使用边缘生成器在丢失区域中生成粗略轮廓,并为第二阶段图像完成网络提供图像结构的先验信息。图像完成网络只需要结合先验模糊结构来填充和修复细节,从而获得结构和纹理良好的互补图像,这是网络的创新。如何在第一阶段生成丢失区域的合理边缘将是该方法未来需要解决的问题。
生成性先验引导图像修复
(1) PGG
在PGG(先验引导GAN)中,从训练的离线参数模型中提取与预测噪声相对应的最佳匹配受损图像作为噪声先验,发送到生成模型以重建自然图像。通过添加目标图像结构的先验来正则化网络。然后提出了一种递归网络来帮助序列化重建,并将该模型进一步扩展到高像素图像修复和视频恢复。
其中,图像修复被视为感知目标图像的最佳匹配潜代码的先验,并从新的角度进行深度学习图像修复,这不同于直接在受损图像上训练深度编码器-解码器驱动器的修复方法。
(2) DGP
DGP(深度生成先验)利用预先在大规模自然图像上训练的生成性对抗网络,捕获丰富的图像语义信息作为先验,其可以获得比单个图像更丰富的先验,包括颜色、空间一致性、纹理、高级语义等。 通过使用鉴别器获得的特征距离进行正则化测量和生成器的渐进微调策略,DGP更好地保留了GAN学习的图像统计信息,从而提供更丰富的恢复和处理效果
在许多图像处理任务中,如图像着色、图像完成和超分辨率重建,都可以获得出色且令人信服的修复结果。
用于图像修复的数据集
目前,由于很难收集大量成对的真实受损图像,所以科研人员在进行图像修复实验时往往选择合适的图像数据集,然后在原始数据中添加相应的掩模。最广泛使用的掩模主要包括矩形孔和不规则掩模。
不规则掩模数据集:
论文 -:
Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, Bryan Catanzaro, Image inpainting for irregular holes using partial convolutions, in: Proc. ECCV, 2018. 3, 4, 6, 7, 85–100.
中使用的是当前最常用的掩膜数据集。包含12000个掩模和总共六个不同的孔图面积比,每个类别包含1000个具有边界约束的掩模(孔确保距离边界至少50个像素)和1000个不具有边界约束。
部分掩膜样本如下图所示:

其中,左边的两个是带有边界限制的,右边两个是没有边界限制的,针对这两类也有相关的研究,没有边界限制的图像修复起来更为困难。
图像修复数据集:

还有之前看过的一篇图像修复的综述里总结的数据集,更为全面:
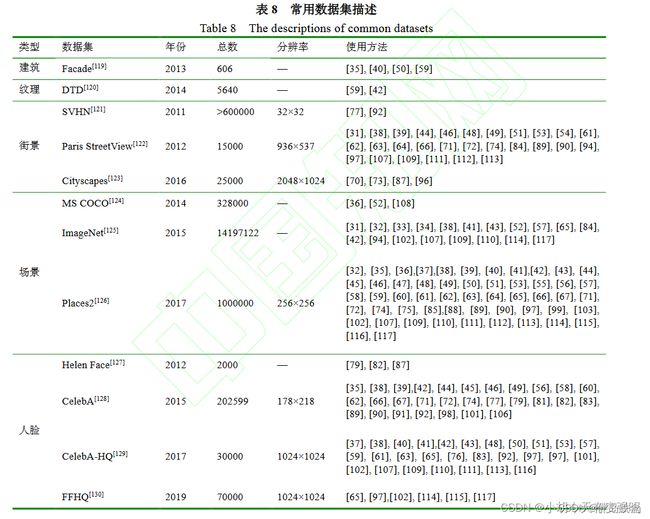
对于这些数据的下载可以到:https://paperswithcode.com/ 去下载
分析
从最近几年的图像修复的研究成果看:
(1)在网络选择方面,基于卷积神经网络的图像修复方法仍然是深度学习图像修复应用研究的主流方法。
(2)生成网络主要包括VAE和GAN,两者各有优缺点。基于VAE的图像修复方法的训练通常更稳定,生成结果容易模糊。基于GAN的图像修复方法可以提高图像修复生成的质量,但难以训练。因此,基于VAE和GAN结合的图像修复方法可以更好地平衡这两种方法的缺点。
(3)目前,虽然通过增加网络的宽度和深度可以更好地拟合数据特征。然而,盲目扩大网络的深度和宽度将导致模型参数爆炸和训练困难。因此,当前的图像修复网络模型一方面采用薄而深的网络结构来减少和控制参数的数量,另一方面将辅助多尺度特征层或跳跃连接残差结构来帮助解决梯度消失问题。
(4)在图像修复任务中,传统卷积通常将所有输入像素视为有效像素,这容易导致颜色差异和模糊等伪影。因此,引入部分卷积或门控卷积可以在一定程度上缓解这一问题,因此基于卷积的改进也是图像修复领域可行的突破方向。
(5)当使用粗到细的网络模型进行渐进图像修复时,容易遇到网络模型过于复杂的问题。因此,研究如何有效地重用编码器和解码器的特定网络层来控制模型参数的数量,从而提高模型的训练效率是一个有意义的尝试。例如,粗路径和细路径共享它们的权重以相互改进,并且它们在PEPSI中使用相同的编码器。
(6)在修复严重受损的非结构化复杂纹理对象时,多元修复可以提供多种合理的修复结果。生成多种合理的结果可满足不同情况下的需求选择。
(7)对于高分辨率图像的修复:由于在直接修复高分辨率图像时会占用更多资源的限制。因此,当前主流的高分辨率图像修复方法将首先修复通过对原始图像进行下采样获得的低分辨率图像。然后,对修复区域进行上采样或使用超分辨率重建的清晰度技术获得原始图像尺寸级别的修复区域,最后替换相应的受损区域,从而间接完成高分辨率图像修复任务。
(8)与纯数据驱动的深度学习图像修复方法相比,通过添加推理图像轮廓模块或结构先验的修复方法可以充分利用可见区域的先验知识进行更精确的纹理推理。因此,基于先验知识的复杂纹理图像修复在应用于特定场景时将是一项非常有意义的研究工作。
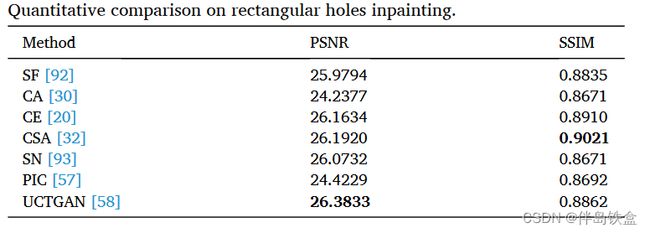
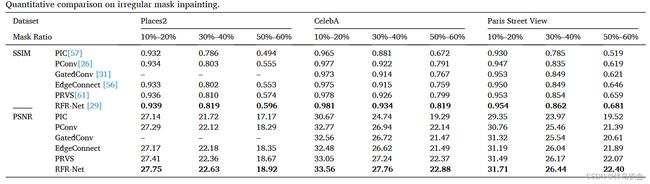
对于相关数据集的一些定量比较:
CelebA HQ人脸数据集上最先进方法的定量比较,是基于中心的矩形区域进行的修复:
结论
虽然图像修复近几年取得了重大的进展,但是仍有部分工作未解决,主要如下:
(1)当前的图像修复方法在处理规则结构数据、小孔修复和低分辨率图像修复时可以获得更好的修复效果。如何提高复杂纹理、大孔洞和高分辨率图像的修复效果?
(2)网络选择和设计、基于GAN网络的图像修复、自动编码器以及两者的结合是目前主要的基本框架。如何将其他深度学习模型应用于图像修复是值得探索的。
一般来说,网络结构越深,重建和修复效果越好,但也会导致训练和收敛困难等问题。如何平衡网络的复杂性与恢复图像的质量之间的矛盾是需要进一步研究的问题。
(3)如何在具体应用中更有效地结合领域知识、先验知识和深度学习框架,提高现有基于深度学习的图像恢复性能是一个值得探索的方向。如果能够充分利用领域和先验知识来指导深度学习模型,不仅可以提取丰富上下文信息的高级语义特征,进而学习受损图像和修复图像之间更复杂的映射关系,而且可以确保这种映射关系的合理性,从而进一步提高基于深度学习的图像修复模型的重建性能和可解释性。
(4)在视频流图像修复中,目前基于深度学习的图像修复方法得益于卷积神经网络良好的空间特征提取能力,大多采用深度卷积神经网构建网络层。递归神经网络能够在数据的时间序列特征层挖掘语义信息,在语音和自然语言处理领域有着良好的应用。如何有效地结合两种神经网络(卷积神经网络(CNN)和递归神经网络(RNN))来处理视频流图像修复将是一个非常有意义的研究方向。