干货!面向低精度量化的神经网络训练算法
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

对神经网络进行低精度量化,尤其是混合精度量化,是提升神经网络部署效率的重要方法之一。然而,如何让神经网络适应低精度的表示,如何选取最合适的量化精度,依然存在很多没有解决的问题。
本报告将从两方面探讨低精度神经网络的训练方法。为了获得最优的量化精度,我们提出了BSQ比特稀疏量化算法,使模型能在训练过程中自发得到合适的混合精度。
为了使模型更适应量化带来的性能影响,我们进一步提出了用权值鲁棒性描述模型泛化能力和低精度表现的理论模型,并依据此模型提出HERO训练算法以提升模型的权值鲁棒性,进而获得泛化能力强且对低精度量化鲁棒的模型。两种方法为获得更高效且性能更好得神经网络模型提供了可能性。
本期AI TIME PhD直播间,我们邀请到杜克大学电子与计算机工程系博士——杨幻睿,为我们带来报告分享《面向低精度量化的神经网络训练算法》。

杨幻睿:
本科毕业于清华大学电子工程系,博士毕业于杜克大学电子与计算机工程系,师从李海和陈怡然老师。博士毕业后,杨幻睿将加入加州大学伯克利分校从事博士后研究。杨幻睿的主要研究方向为提升深度学习模型的运行效率和鲁棒性。
今天要介绍的研究主要是关于高效深度学习的问题。我们发现随着深度学习的发展,学者们提出了越来越多神经网络的模型。在追求更高的模型性能的过程中,新提出的神经网络架构所占用的参数量需要的计算量都在逐渐提高。
Challenges of DNN from Efficiency Perspective
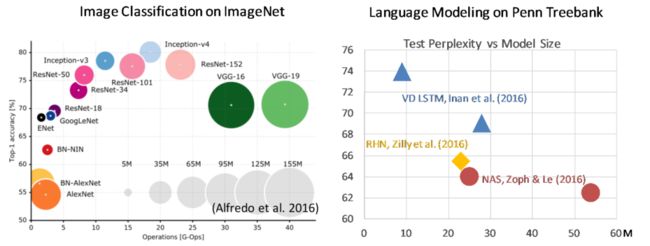
上图所示的还是一些相对较早的模型,我们现在用的transformer、Bert模型在取得更好性能的同时,都使用了更高的参数量与计算量。
尽管深度学习模型如今发展迅速,但如果我们想把模型用在实际场景之中,就要考虑在很多硬件设备上的计算能力是受限的。为了能够更好的将深度学习模型部署到现实世界当中,我们必须对这些高性能的模型进行压缩和加速。
Efficiency Improvement for DNN Models
• Pruning
• Set weight element to zero
• Save storage and computation (structural pruning)
• Low-rank factorization
• Decompose layer into low-rank matrix multiplications
• Keep input/output dimensions, suitable for complex architecture
• Quantization
• Represent weights/activations in fixed-point representation
• Reduce memory size, friendly to hardware deployment
目前主流的针对人工设计的模型的压缩加速方式大致分为3种。第一种是剪枝,既将一些权重设为0使其可以通过编码的方式减少一定程度的存储量。跟进一步可以通过结构化剪枝的方式直接减小模型参数的维度,实现计算量的减少。
第二种方法是对模型做低秩的分解,即把一个卷积层分解成两个或多个低秩的矩阵相乘。这样我们就可以在保留原始模型输入输出维度的基础上进一步缩小模型的计算量。
第三种方法是做模型的量化,把模型的权重用一种定点的低精度编码来表示。这样也在一定程度上更适应小型硬件,比如移动端或嵌入式处理器上的存储与运算。
Goal of My Research
对于压缩人工设计模型,我们的工作主要集中于使用一些正则项来诱导模型的压缩。我们选择使用可导的神经网络正则项是因为其能和神经网络的训练很好结合。

在神经网络训练中我们使用梯度下降算法,通过优化器来优化可导的损失函数L。而如果我们有可导的正则化项,我们就能将其加在损失函数上使其可以正常的用优化器训练。
更进一步,我们可以通过控制 α 的大小来选择压缩的程度,实现对模型大小与性能之间的均衡。因此,我们研究的重点在于如何找到一个合适的正则项来诱使模型在训练中逐渐变得稀疏、低秩以及适应低精度表示。
在本次报告中我们重点来讨论如何通过正则项得到低精度的模型。
The Need of Fixed-point Quantization
我们为何需要低精度呢?低精度主要带来了两个好处。一个最直接的好处是可以减少模型的存储消耗。另一方面对于硬件部署来讲,低精度表示,尤其是定点低精度的表示大幅度的减少了计算所需要的能量和面积开销。如下图所示:
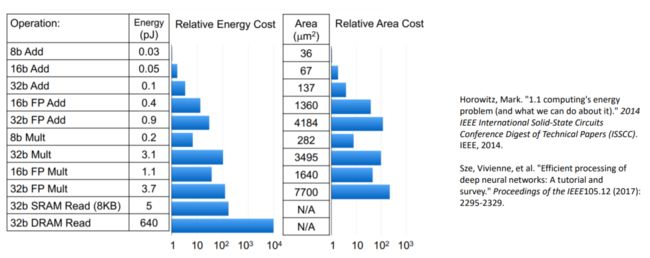
可见,低精度定点计算可以带来很大的优势。
Challenge of Quantization
对于低精度量化而言,和之前剪枝等方法相似的一点是,模型有些层是重要的,有些层没那么重要。我们希望给更重要的层赋予更高的精度,不重要的层赋予较低的精度,这也由此引入了混合精度量化的概念。
目前的问题是,如何找到一个量化的分布方式使得我们模型可以得到一个最优的、效率与性能之间的trade off。
量化与剪枝、分解主要的区别在于模型的精度并不能用一个模型权重值的可导函数来表示。在描述模型稀疏性时,我们可以用所有权重绝对值的和,也就是L1范数,或者叫LASSO,来作为稀疏性的度量。
我们之前的也就也提出了DeepHoyer之类的稀疏正则项。然而,对量化而言找到这样的正则项是困难的。模型的精度也并不是模型的权重值的一个函数,我们很难去直接设计一个可导的正则项。为了规避这一问题,前人的研究通过一些判据分析哪些层是重要的,然后根据重要性人工指定一个精度的分布。这样很难保证获得最好的效果。
此外也有人尝试通过神经网络结构搜索(NAS)的方式直接搜出最优的精度组合,但这样需要很大的运算量。
对于我们而言,既然我们希望可以通过一个可导的正则项来实现量化,而我们又对稀疏正则项比较熟悉,那么能否把量化的问题也转变成一个稀疏型的问题呢?另外鉴于量化精度不是权重值的函数,我们现在的思路就是不看权重值本身,而是看其在量化之后的比特表示。
A Bit-level View of Quantization
我们的目标是通过正则项诱导比特数的减少,那么我们什么时候可以减少表示的比特数呢?下面我们来从比特的层面观察一下:对于一个矩阵
• 所有元素的最高比特(MSB)为0:精度可直接降低
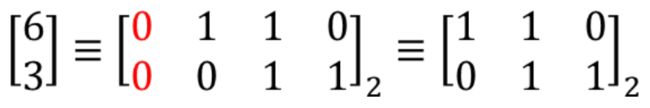
• 所有元素的最低比特(LSB)为0:精度可以通过右移降低,得到结果乘2即为原数值。

通过这一观察,我们发现比特层面的结构化稀疏可以带来精度的减少。因此我们提出了BSQ的训练方法——通过引入结构化的比特级稀疏性,可以诱导出混合精度量化的模型。
BSQ Training Pipeline
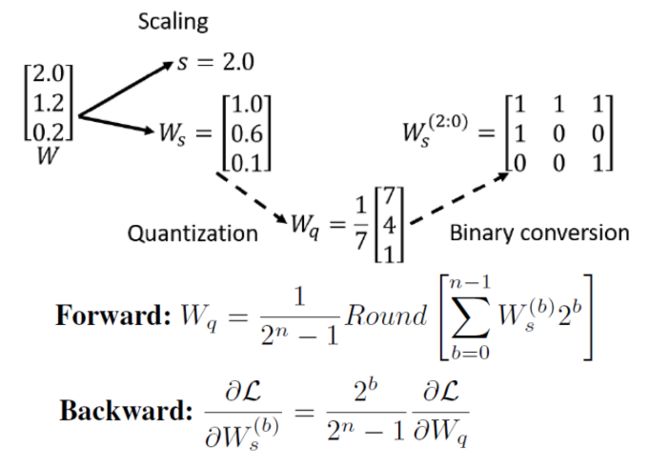
• 比特层面的神经网络表示
在这里我们提出比特层面神经网络的训练算法。在训练过程中,我们从8bit的量级开始,这样不太会影响模型的性能。在这里我们直接使用模型权重的每一位比特值作为可训练参数。为了实现梯度累计在训练过程中我们允许每一位比特值用浮点数表示。在正向传播时我们对比特值进行量化来模拟量化后网络的表现,反向传播的时候我们直接把权值的梯度传过了rounding function,并传到了每一位的bit表示上。
为了实现稀疏性,我们提出了以下方法:利用group LASSO使得某一层参数中所有权重的某一比特同时变为零。
• Bit-level group LASSO
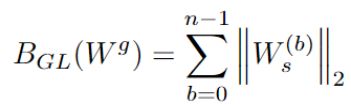
在整体的训练算法上,我们采用了如下的一个训练目标:

我们根据各层当前的总比特数调整其正则项的强度,使得占用空间更大的层能得到更大的压缩。
随着我们训练的进行,我们会周期性的量化所有比特值,去掉全零的比特,改变某些层的精度。通过这种循环往复的方式,我们就可以得到一个最终的混合精度表示,并通过fine-tuning得到最终的模型。
Accuracy-#Bits Tradeoff
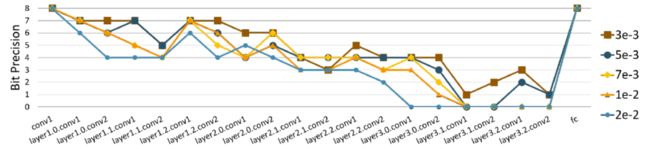
从效果上来说,我们这个BSQ方法很好的实现了模型性能与模型大小之间的trade off。可以看到随着我们使用不同regularization的强度,最后得到的模型各层精度分布符合一个稳定的趋势。当然随着regularization强度的不断增高,每一层被分配的bit数也不断减少。

另外我们发现,在同样的量化精度下,通过BSQ得到的模型准确率要高于直接从零训练的模型。这一点与之前工作对模型剪枝的观察:“从大模型剪枝出一个小模型,往往比将小模型从0开始训练能得到更好的效果”是一致的,这也进一步体现了我们BSQ方法的优势。
Comparing with SOTA Methods
下面列举了与之前方法的对比。
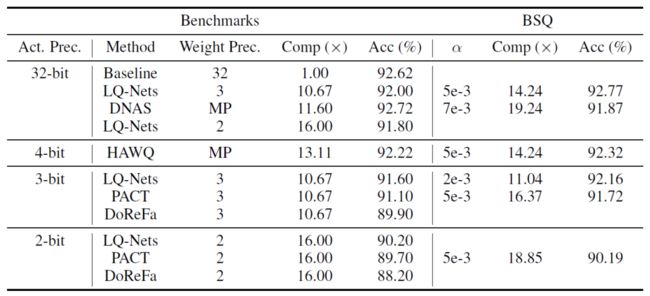
在相同性能下,压缩比更大。

Takeaways
• BSQ (ICLR 2021)
• 通过bit层面的结构化稀疏来进行权值精度的降低
• 实现了bit层面的Group Lasso
• 在训练过程中引导模型进行精度降低并最终得到一个混合精度的量化模型
我们最终也得到了一个超越之前方法的accuracy-efficiency tradeoff。
The Need of Real-World Application
现实环境的变化也给我们的神经网络部署提供了一定的需求。我们希望模型能具有更高的灵活性。
• 量化方案的灵活性
■ 运行时环境可能会发生变化
■ 低电量模式,内存不足等。
■ 最好让模型灵活到可以从一系列量化方案中选择
■ 量化感知训练不直接支持
• 推广到看不见的数据
■ 真实世界的输入不存在于训练集中
■ 需要模型泛化到新的输入
Unifying the Pursuit of Generalization and Quantization
我们希望找到一种方式,同时实现模型泛化能力和对不同量化精度鲁棒性的提升。
• Model generalizability (SAM, ICLR21’)
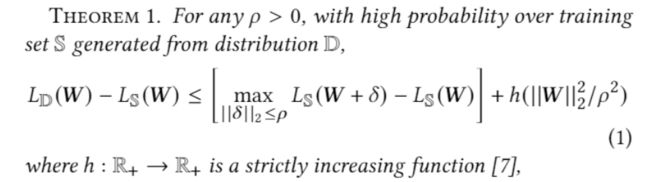
模型对L2的权重噪声越鲁棒,也就说明其泛化能力越强。
• Performance under quantization

综上,我们可以说模型在量化之下带来的性能损失是以最差情况下的L无穷权重噪声所带来的性能损失为上限的。
综合上面这两个观察,如果我们能够得到一个理论体系可以使得模型对任意的lp权重噪声去鲁棒的话,就能够同时提升模型的泛化能力和鲁棒性。
那么如何做到同时提升呢?
Improving Weight Perturbation Robustness
• Modeling perturbation strength lower-bound

为了方便后文的分析,这里我们先定义一个最小噪声强度的概念。我们希望可以找到一个最小的噪声强度使得模型损失函数增大超出我们容忍的范围。在这样的定义下,一个模型的最小噪声强度越大说明模型可以容忍强度越大的噪声,这就是我们优化的目标。
• Derive with Taylor expansion
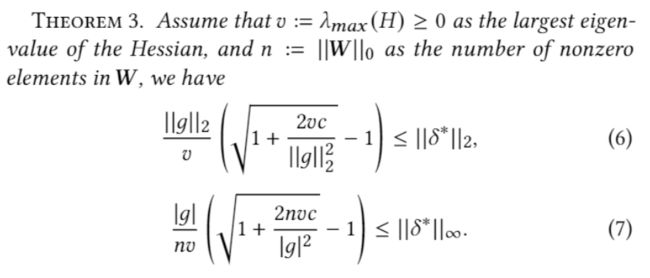
我们计划使用泰勒展开对最小噪声强度进行分析。我们发现,无论对于哪种权重噪声,其最小值均和海森矩阵的最大特征值v有关,且随着v的增大单调递减。这就说明更小的海森矩阵特征值能够带来更高的模型对权重噪声的鲁棒性。
Hessian-Enhanced Robust Optimization (HERO)
• Hessian eigenvalue regularization
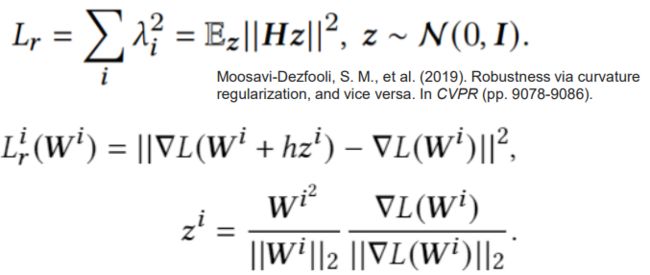
为了减小海森矩阵特征值,我们提出了一个新的正则项。鉴于神经网络海森矩阵的求解难度,我们通过对海森矩阵进行了差分近似,得到沿着特征值最大方向的海森矩阵特征值的估计。
• Gradient of regularization

在对这一正则项进行优化的过程中,我们进一步对其梯度求解进行了简化,以提升训练的效率。最终我们得到了下面梯度更新算法,也就是我们提出的Hessian Enhanced Robust Optimization (HERO)
• Overall optimization step
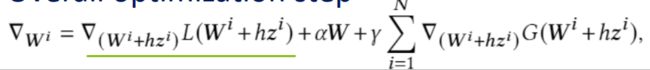
Theoretical Insight Verification

从实验结果而言,从训练效果上,随着训练的进行,尽管模型的海森特征值与泛化损失都在增大(神经网络一定程度的过拟合是不可避免的),HERO训练出来的网络与其他方法相比有着最小的Hessian norm和generalization gap,这也带来了最优的测试集上的表现,并印证了我们更小的海森特征值可以增强模型泛化能力的理论分析。
从最终得到的模型来看,HERO得到的模型收敛于更加平缓的极小值点,使得模型对权重噪声有更强的鲁棒性。
与之前提出的一阶正则项SAM相比,HERO进一步提升模型泛化能力,降低模型在量化过程中的损失,体现出HERO提出的二阶泰勒分析与正则项的不可或缺性。
Trained Model Performance

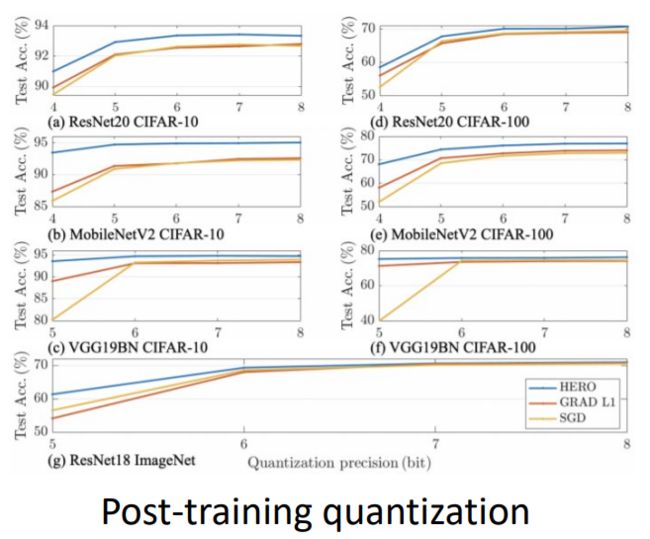
我们可以看到,HERO方法在测试集准确性与不同精度量化下的表现均优于之前的算法。
Takeaways
• HERO (DAC 2022)
■ 模型的generalization gap可以被ℓ2 权值噪声下的性能所限制
■ Uniform quantization等价于ℓ∞权值噪声下的表现
■ 在两种情况下,较小的Hessian特征值提高了权值扰动的鲁棒性
■ HERO既能提高测试精度,又对训练后量化具有更高的鲁棒性
对权重扰动鲁棒性的研究有助于获得精确的、硬件友好的DNN。
提
醒
论文题目:
BSQ: Exploring Bit-Level Sparsity for Mixed-Precision Neural Network Quantization (ICLR 2021)
HERO: Hessian-Enhanced Robust Optimization for Unifying and Improving Generalization and Quantization Performance (DAC 2022)
论文链接:
https://arxiv.org/abs/2102.10462
https://arxiv.org/abs/2111.11986
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:杨幻睿
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了700多位海内外讲者,举办了逾300场活动,超260万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 查看回放!