深度学习——双向循环神经网络(笔记)

双向循环神经网络:
①对于序列来讲,假设的目标是:给定观测的情况下(在时间序列的上下文或语言模型的上下文),对于下一个输出进行建模
②对于序列模型来讲,可以从前往后看,也可以从后往前看
1.未来很重要

①取决于过去和未来的上下文,可以填不同的词
②RNN只看过去的
③填空的时候,可以看未来
2.隐马尔可夫模型的动态规划
假设有一个隐变量模型:在任意时间步t,假设存在某个隐变量 ht ,通过概率 P(xt | ht) 控制观测到的 xt。此外,任何 ht -> h(t+1) 转移都是由一些状态转移概率 P(h(t+1) | ht)给出,则这个概率图模型就是一个隐马尔可夫模型(hidden Markov model,HMM)
3.双向RNN
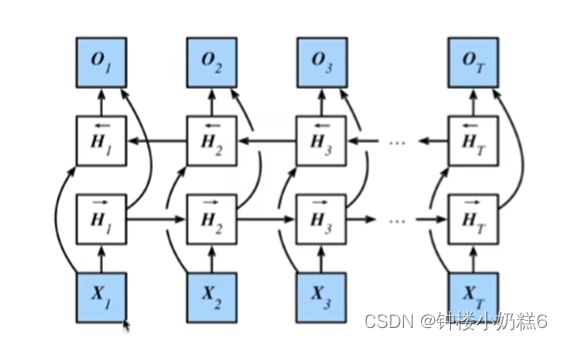
①一个前向RNN隐层
②一个反向RNN隐层
③合并两个隐状态得到输出
Ⅰ在循环神经网络中,只有一个前向模式下“从第一个次元开始运行”的循环神经网络。循环网络获得隐马尔可夫模型的前瞻能力,只需要增加一个“从最后一个词元开始从后向前运行”的循环神经网络
Ⅱ双向循环神经网络的隐藏层有两个隐状态(前向隐状态和反向隐状态,通过添加反向传递信息的隐藏层来处理反向传递的信息):输入X1为例,当输入X1进入模型后,当前的隐藏状态放入下一个时间步的状态中去。X2更新完隐藏状态之后,将更新后的隐藏状态传递给X1的隐藏状态。将两个隐藏状态合并在一起,得到了输出层的隐状态Ht。最后输出层计算得到Ot
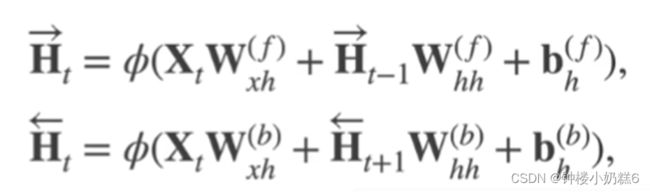
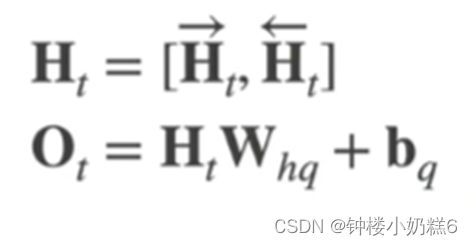
实现:
将输入复制一遍,一份用于做前向的时候,正常的隐藏层会得到一些输出。
另一份用于反向的时候,反向的隐藏层得到一些输出,然后进行前后顺序颠倒
将正向输出和颠倒顺序反向输出进行合并(concat),得到最终输出。
4.模型的计算代价及其应用
①双向循环神经网络的一个关键特性是:使用来自序列两端的信息来估计输出
Ⅰ使用过去和未来的观测信息来预测当前的观测,因此并不适用于预测下一个词元的场景,因为在预测下一个词元时,并不能得知下一个词元的下文,因为不会得到很好的精度
Ⅱ如果使用双向循环神经网络预测下一个词元,尽管在训练的时候能够利用所预测词元过去和未来的数据(也就是所预测词元的上下文)来估计所预测的词元,但是在测试的时候,模型的输入只有过去的数据(也就是所预测词所在位置之前的信息),所以会导致精度很差
②此外,双向循环神经网络的计算速度非常慢
Ⅰ主要原因是网络的前向传播需要在双向层中进行前向和后向递归,并且网络的反向传播也以依赖于前向传播的结果,因此梯度求解将有一个非常长的链
③双向层在实际中的时用的比较少,仅仅应用于部分场合:
Ⅰ填充缺失的单词
Ⅱ词元注释(如命名实体识别)
Ⅲ作为序列处理流水线中的一个步骤对序列进行编码(如机器翻译)
5.训练

- 双向 LSTM 不适合做推理,几乎不能用于预测下一个词,因为为了得到隐藏状态 H ,既要看到它之前的信息,又要看到之后的信息,因为在推理的时候没有之后的信息,所以是做不了推理的
- 双向循环神经网络主要的作用是对句子做特征提取,比如在做翻译的时候,给定一个句子去翻译下一个句子,那么可以用双向循环神经网络来做已给定句子的特征提取;或者是做改写等能够看到整个句子的应用场景下,做整个句子的特征提取
【总结】
1、双向循环神经网络通过反向更新的隐藏层来利用方向时间信息
2、在双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定
3、双向循环神经网络与概率图模型中的“前向-后向”算法具有相似性
4、双向循环神经网络主要用于序列编码和给定双向上下文的观测估计,通常用来对序列抽取特征、填空,而不是预测未来
5、由于梯度链更长,因此双向循环神经网络的训练代价非常高
【代码实现】
加载数据集
from mxnet import npx
from mxnet.gluon import rnn
from d2l import mxnet as d2l
npx.set_np()
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
通过设置bidirective=True定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
lstm_layer = rnn.LSTM(num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)