目标检测论文阅读:VFNet算法笔记
标题:VarifocalNet: An IoU-aware Dense Object Detector
会议:CVPR2021
论文地址:https://ieeexplore.ieee.org/document/9578034/
这篇文章和GFL的工作有点相似,也是发现了NMS中用于排序的边界框分数并不合理这一问题。不过文章并不像GFL那样详细地叙述了为什么不合理,而是直截了当地提出了他们的方法,并且设计了一个新的anchor-free检测器。虽然出发点和GFL类似,但是提出的方法还是有很大区别的。所以,如何从一堆预测框出筛选出高质量的边界框对目标检测性能来说是十分关键的,值得深究。
文章目录
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Motivation
- 4. VarifocalNet
-
- 4.1. IACS – IoU-Aware Classification Score
- 4.2. Varifocal Loss
- 4.3. Star-Shaped Box Feature Representation
- 4.4. Bounding Box Refinement
- 4.5. VarifocalNet
- 4.6. Loss Function and Inference
- 5. Experiments
-
- 5.1. Ablation Study
- 5.2. Comparison with State-of-the-Art
- 5.3. VarifocalNet-X
- 5.4. Generality and Superiority of Varifocal Loss
- 6. Conclusion
Abstract
将大量候选检测准确地进行排序对于稠密目标检测器取得高性能来说是至关重要的。之前的工作使用分类分数,或者分类和预测的定位分数的组合来给候选框排序。然而,这二者都会导致不可靠的排序,使检测性能降低。本文提出学习一个IoU感知分类分数(IoU-Aware Classification Score,IACS)作为目标存在置信度和定位精度的联合表示。我们证明了稠密目标检测器可以基于IACS实现对候选检测更准确的排序。我们设计了一个新的损失函数训练稠密目标检测器来预测IACS,称为Varifocal Loss,并提出了一种新的星形边界框特征表示来进行IACS预测和边界框细化。结合这两个新组件和一个边界框细化分支,我们构建了一个基于FCOS+ATSS结构的IoU感知稠密目标检测器,称为VarifocalNet或者简称VFNet。COCO上的大量实验证明,VFNet使用不同的主干均可以一致地超过强大的baseline大约2.0%AP。我们最好的模型,以Res2Net-101-DCN为主干的VFNet-X-1200取得了单模型单尺度的SOTA,55.1%AP。
1. Introduction
现在的目标检测器不管是两阶段方法还是单阶段方法,通常先生成一组冗余的带有分类分数的边界框,然后使用非极大抑制(NMS)来去掉同一目标上的重复边界框。分类分数一般用于NMS中对边界框排序。然而这损害了检测性能,因为分类分数并不总是边界框定位精度的良好估计,并且NMS中可能会把分类分数低的准确定位检测给错误地删除掉。
为了解决上述问题,现有的稠密目标检测器预测一个额外的IoU分数或者中心性分数作为定位精度的估计,然后将它们与分类分数相乘后在NMS中排序。这些方法可以缓解分类分数与目标定位精度之间的错位问题。然而,它们是次优的,因为将两个不完美的预测相乘可能会导致更差的排序基准,并且我们在第3节中证明了这类方法所达到的性能上界是有限的。此外,增加一个额外的网络分支来预测定位分数并不是一个优雅的解决方案,会带来额外的计算负担。
为了克服这些缺点,我们自然想问:代替预测一个额外的定位精度分数,我们能否把它合并到分类分数中?也就是预测一个定位感知或者IoU感知分类分数(IACS),它可以同时表示某个目标类别的存在性和生成的边界框的定位精度。
本文回答了上述问题并做出以下贡献。①我们表明,准确地给候选检测排序对于稠密目标检测器达到更高性能是至关重要的,并且IACS取得了比其它方法更好的排序(第3节)。②我们提出了一种新的用于训练稠密目标探测器的Varifocal Loss来回归IACS。③我们设计了一种新的星形边界框特征表示,用于计算IACS和细化边界框。④为了发挥IACS的优势,我们基于FCOS+ ATSS和所提出的组件,开发了一种新的稠密目标检测器,称为VarifocalNet或简称VFNet。图1是我们方法的示意图。
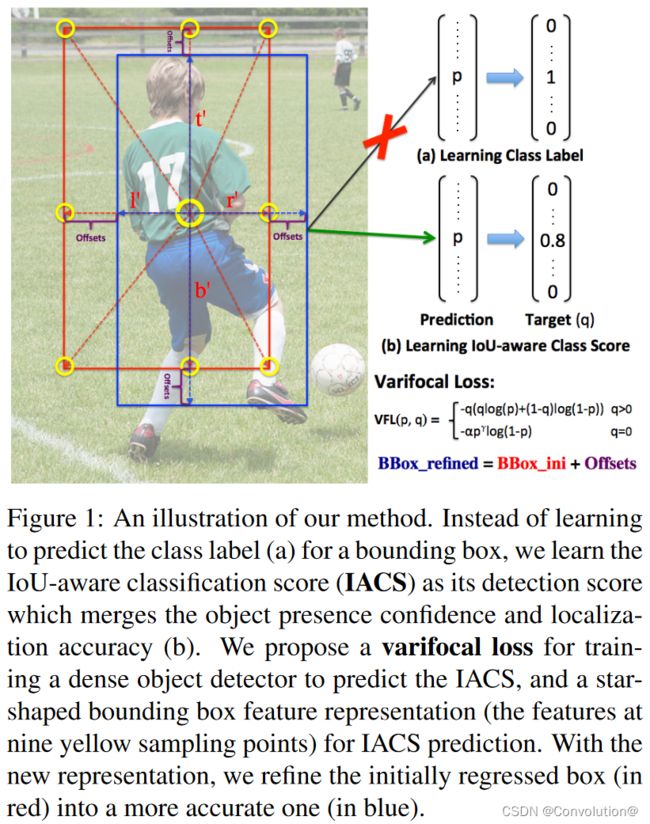
受Focal Loss的启发,Varifocal Loss是一种动态尺度的二分类交叉熵损失。不过,它是监督稠密目标检测器来回归连续型的IACS,更特别的是,它采用了一种非对称的训练样本加权方法。它在训练时只会降低负样本的权重来解决类不平衡的问题,而会增加高质量正样本的权重来生成主要的检测框。这就使得训练集中在高质量的正样本上,对于取得高检测性能非常重要。
星形边界框特征表示使用9个固定采样点(图1中的黄圈)的特征,基于可变形卷积来表示边界框。与大多数现有的稠密目标检测器中使用的点特征相比,这种特征表示可以捕获边界框的几何信息及其附近的上下文信息,对于预测准确的IACS十分重要。它还能够有效地细化初始生成的粗糙边界框而不会损失效率。
为了验证我们提出模块的有效性,我们基于FCOS+ATSS构建了VFNet,然后在COCO上进行了评估。实验表明我们提出的VFNet在使用不同主干的情况下始终超过强baseline大约2.0AP,并且最好的模型VFNet-X-1200使用Res2Net-101-DCN主干在COCO-test-dev上达到了单模型单尺度55.1AP,超过了此前发表的最好的单模型单尺度结果。
2. Related Work
目标检测。 两阶段和多阶段方法通常使用锚框来为下游的分类和回归生成proposal,anchor-based的单阶段方法则直接分类和细化锚框而不生成proposal。然后回顾了最近的anchor-free检测器。我们基于ATSS版本的FCOS构建了一个简单高效且性能优异的VFNet。
检测排序措施。 介绍了一些除了分类分数之外还使用了其它方式进行检测排序的措施。相比之下,我们只预测IACS作为排序分数。这避免了额外网络带来的开销,也避免了不完美的定位和分类分数相乘可能导致更差的排序基准。
边界框编码。 两阶段和多阶段方法中的RoI Pooling和RoIAlign对于稠密目标检测器来说是费时的。单阶段方法中的点特征是局部特征,无法捕捉边界框的几何信息和重要的上下文信息。此外,学习语义点并在该处提取特征是缺乏强监督的,也会加重计算负担。相比之下,我们提出的星形边界框表示使用9个固定采样点的特征来描述边界框。它简单高效,且能捕捉边界框的几何信息和周围的空间上下文线索。
Generalized Focal Loss。 与我们最相似是一个同期的工作,Generalized Focal Loss(GFL)。GFL将Focal Loss扩展为连续版本,并训练检测器预测定位质量和分类的联合表示。首先要强调的是,我们的Varifocal Loss是一个不同于GFL的函数。它对正样本和负样本进行非对称加权,而GFL对正样本和负样本进行平等处理,实验结果表明我们的Varifocal Loss比GFL表现更好。此外,我们提出了一种星形边界框特征表示,以方便IACS的预测,并通过一个边界框细化步骤进一步提高了目标定位精度,而这在GFL中是没有考虑的。
3. Motivation
本节我们研究一种主流的anchor-free稠密目标检测器FCOS的性能上界,确定它的主要性能障碍,并表明生成IoU感知分类分数作为排序标准的重要性。
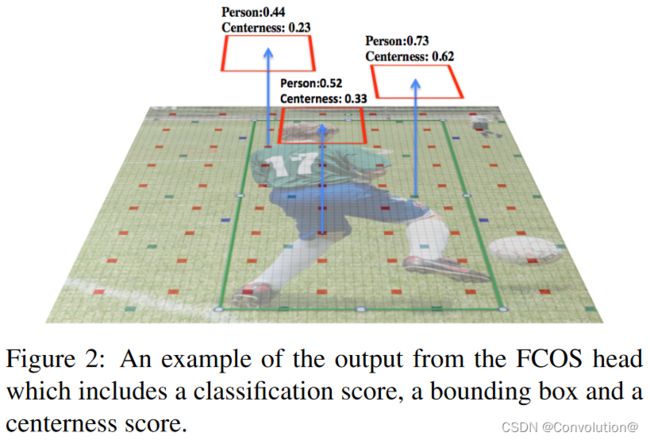
FCOS基于FPN构建,其检测头有三个分支。一个分支预测特征图上每个点的分类分数,一个分支回归该点到边界框四边的距离,另一个分支预测中心性分数并将其乘以分类分数来对NMS中的边界框进行排序。图2是FCOS头部输出的一个例子。本文研究的实际是ATSS版本的FCOS(FCOS+ATSS),它采用自适应训练样本选择(ATSS)机制在训练时定义特征金字塔上的前景和背景点。
为了研究FCOS+ATSS的性能上界,我们在NMS之前将预测的分类分数、距离偏移量和中心性分数相继替换为对应的前景点的真值,并在COCO上根据AP评估检测性能。对于分类分数向量,我们实现了两个选项,即将其在真实标签位置的元素替换为1.0或预测的边界框与真实标签之间的IoU(记为gt_IoU)。除了其真实值,我们还考虑用gt_IoU代替中心性分数。
结果如表1所示。可以看到,原来的FCOS+ATSS达到了39.2AP。当在推理阶段使用真值中心性分数(gt_ctr)时,出乎意料的是仅增加了约2.0AP。同样地,用gt_IoU(gt_ctr_iou)替换预测的中心性分数仅达到43.5AP。这表明,无论使用预测的中心性分数还是IoU分数与分类分数的乘积来给检测排序,都无法带来显著的性能增益。
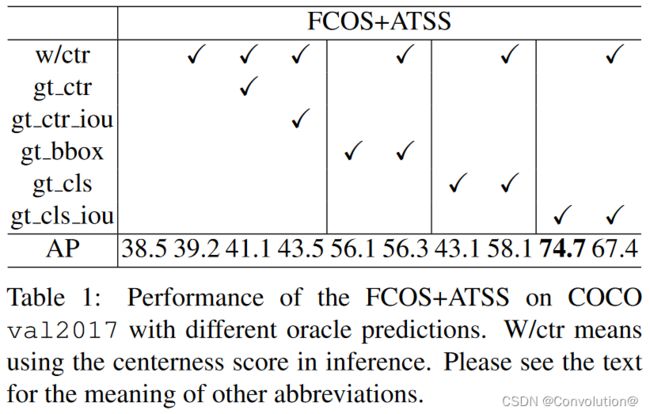
相比之下,FCOS+ATSS在推理阶段即使没有中心性得分(no w/ctr),也能达到56.1AP。但如果在真实标签位置(gt_cls)把分类分数设为1.0,是否使用中心性分数就变得十分重要了(43.1AP vs 58.1AP)。因为中心性分数可以在一定程度上区分准确和不准确的框。
最惊讶的结果是用gt_IoU(gt_cls_iou)代替真实类别的分类分数得到的结果。在没有中心性分数的情况下,其达到了惊人的74.7AP,明显高于其他情况。这实际上表明,对于大候选池中的大多数目标,已经有了准确定位的边界框。实现优秀检测性能的关键是准确地从池中选择那些高质量的检测,上述结果表明用gt_IoU代替真实类别的分类分数是最合适的选择措施。我们将这种分数向量的元素称为IoU感知分类分数(IACS)。
4. VarifocalNet
基于上述发现,我们提出学习IoU感知分类分数(IACS)来对检测进行排序。为此,我们在删除了中心性分支的FCOS+ATSS基础上构建了一个新的稠密目标检测器,称为VarifocalNet或VFNet。与FCOS+ATSS相比,它增加了三个新的组件:Varifocal Loss、星形边界框盒特征表示和边界框细化。
4.1. IACS – IoU-Aware Classification Score
我们将IACS定义为分类分数向量的一个标量元素,其在真实类别标签位置的值是预测的边界框与真值之间的IoU,而在其他位置则为0。
4.2. Varifocal Loss
我们设计了新的Varifocal Loss用于训练稠密目标检测器预测IACS。因为是受Focal Loss的启发,我们首先简单回顾Focal Loss。
Focal Loss的设计是为了解决稠密目标检测器训练过程中前景类和背景类之间极度的不平衡问题。其定义为:
FL ( p , y ) = { − α ( 1 − p ) γ log ( p ) if y = 1 − ( 1 − α ) p γ log ( 1 − p ) otherwise \textrm{FL}(p,y)=\left\{\begin{matrix} -\alpha(1-p)^\gamma\textrm{log}(p)~~~~~~~~~~\textrm{if}~~~~y=1 \\-(1-\alpha)p^\gamma\textrm{log}(1-p)~~~\textrm{otherwise} \end{matrix}\right. FL(p,y)={−α(1−p)γlog(p) if y=1−(1−α)pγlog(1−p) otherwise其中, y ∈ { ± 1 } y\in\{±1\} y∈{±1}表示真实类别, p ∈ [ 0 , 1 ] p\in[0,1] p∈[0,1]表示前景类别的预测概率。公式中的调节因子(前景类的 ( 1 − p ) γ (1-p)^\gamma (1−p)γ和背景类的 p γ p^\gamma pγ)可以减少简单样本的损失贡献,相对增加错误分类样本的重要性。这样,Focal Loss避免了训练过程中大量简单负样本主导检测器,使检测器聚焦于稀疏的困难样本上。在训练稠密目标检测器回归连续型的IACS时,我们借鉴Focal Loss的样本加权思想来解决类不平衡问题。然而,不同于Focal Loss平等对待正负样本,我们对它们进行非对称处理。我们的Varifocal Loss也是基于二分类交叉熵损失,定义为:
VFL ( p , q ) = { − q ( q log ( p ) + ( 1 − q ) log ( 1 − p ) ) q > 0 − α p γ log ( 1 − p ) q = 0 \textrm{VFL}(p,q)=\left\{\begin{matrix} -q(q\textrm{log}(p)+(1-q)\textrm{log}(1-p))&q>0 \\-\alpha p^\gamma\textrm{log}(1-p)&q=0 \end{matrix}\right. VFL(p,q)={−q(qlog(p)+(1−q)log(1−p))−αpγlog(1−p)q>0q=0其中 p p p是预测的IACS, q q q是目标分数。对于前景点,其真实类别的 q q q设置为生成的边界框与其真值(gt_IoU)之间的IoU,否则为0。对于背景点,所有类别的目标 q q q均为0。如图1所示。
Varifocal Loss只减少负样本( q = 0 q=0 q=0)的损失贡献,通过用因子 p γ p^\gamma pγ来缩放损失,并没有以同样的方式对正样本( q > 0 q>0 q>0)进行降权。这是因为正样本相对负样本而言非常少,我们应该保留其宝贵的学习信息。另一方面,我们用训练目标 q q q对正样本进行加权。如果一个正样本具有较高的gt_IoU,那么它对损失的贡献也会比较大。这就把训练聚焦于那些高质量的正样本,它们对取得高AP要比那些低质量的正样本更加重要。为了平衡正样本和负样本之间的损失,我们在负样本损失项中加入了一个可调节的缩放因子 α α α。
4.3. Star-Shaped Box Feature Representation
我们设计了一种星形边界框特征表示用于IACS预测。它基于可变形卷积,用9个固定采样点(图1中的黄色圆圈)处的特征来表示边界框。这种新的表示方式可以获取边界框的几何信息及其附近的上下文信息,对于预测边界框与真值边界框之间的错位编码十分重要。
具体来说,给定图像平面上的一个采样位置 ( x , y ) (x,y) (x,y)(或者特征图上的一个投影点),我们首先用3×3卷积从其回归一个初始边界框。根据FCOS,这个边界框用一个4D向量 ( l ′ , t ′ , r ′ , b ′ ) (l',t',r',b') (l′,t′,r′,b′)来编码,分别表示位置 ( x , y ) (x,y) (x,y)到边界框左、上、右、下四边的距离。利用这个距离向量,我们启发式地在 ( x , y ) (x, y) (x,y)、 ( x − l ′ , y ) (x-l', y) (x−l′,y)、 ( x , y − t ′ ) (x, y-t') (x,y−t′)、 ( x + r ′ , y ) (x+r', y) (x+r′,y)、 ( x , y + b ′ ) (x, y+b') (x,y+b′)、 ( x − l ′ , y − t ′ ) (x-l', y-t') (x−l′,y−t′)、 ( x + l ′ , y − t ′ ) (x+l', y-t') (x+l′,y−t′)、 ( x − l ′ , y + b ′ ) (x-l', y+b') (x−l′,y+b′)和 ( x + r ′ , y + b ′ ) (x+r', y+b') (x+r′,y+b′)选择了9个采样点,并将它们映射到特征图上。它们与 ( x , y ) (x,y) (x,y)的投影点的相对偏移量作为可变形卷积的偏移量,然后这9个投影点处的特征经过可变形卷积来表示一个边界框。由于这些点是手动选择的,没有额外的预测负担,因此我们的新表示是计算高效的。
4.4. Bounding Box Refinement
我们通过一个边界框细化步骤来进一步提高目标定位精度。边界框细化是目标检测中常用的技术,但由于缺乏高效且具有辨识性的目标描述符号,因此并没有广泛用于稠密目标检测器。通过我们的星形表示,我们现在可以无损地将其用于稠密目标检测器。
我们将边界框细化建模为一个残差学习问题。对于一个初始回归的边界框 ( l ′ , t ′ , r ′ , b ′ ) (l',t',r',b') (l′,t′,r′,b′),我们首先提取星形表示来对其编码。然后,基于上述表示,学习4个距离缩放因子 ( ∆ l , ∆ t , ∆ r , ∆ b ) (∆l ,∆t ,∆r ,∆b) (∆l,∆t,∆r,∆b),对初始的距离向量进行缩放,使通过 ( l , t , r , b ) = ( ∆ l × l ′ , ∆ t × t ′ , ∆ r × r ′ , ∆ b × b ′ ) (l,t,r,b)=(∆l×l',∆t×t',∆r×r',∆b×b') (l,t,r,b)=(∆l×l′,∆t×t′,∆r×r′,∆b×b′)表示的优化后的边界框更接近真值。
4.5. VarifocalNet
将以上三个组件附加到FCOS网络结构中,并去掉原有的中心性分支,就得到了VarifocalNet。
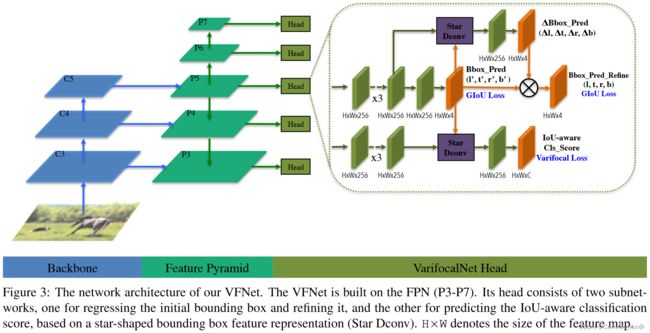
图3展示了VFNet的网络结构。VFNet的backbone和FPN网络部分与FCOS相同。不同之处在于head结构。VFNet的head由两个子网络组成。定位子网络进行边界回归和后续的优化。它将FPN的每一层特征图作为输入,首先用三个3×3卷积层和ReLU激活。这产生了一个256通道的特征图。定位子网络的一个分支对特征图再次进行卷积,然后每个空间位置都输出一个表示初始边界框的4D距离向量 ( l ′ , t ′ , r ′ , b ′ ) (l',t',r',b') (l′,t′,r′,b′)。给定初始边界框和特征图,另一个分支对9个特征采样点使用星形可变形卷积,生成距离缩放因子 ( ∆ l , ∆ t , ∆ r , ∆ b ) (∆l ,∆t ,∆r ,∆b) (∆l,∆t,∆r,∆b),该距离缩放因子与初始距离向量相乘,就得到了优化后的边界框 ( l , t , r , b ) (l,t,r,b) (l,t,r,b)。
另一个子网络旨在预测IACS。它与定位子网络(中的优化分支)具有相似的结构,除了在每个空间位置输出一个由C(类别数)个元素组成的向量,其中的每个元素联合表示目标存在置信度和定位精度。
4.6. Loss Function and Inference
损失函数。 VFNet的训练由下面的损失函数监督:
Loss = 1 N p o s ∑ i ∑ c VFL ( p c , i , q c , i ) + λ 0 N p o s ∑ i q c ∗ , i L b b o x ( b b o x i ′ , b b o x i ∗ ) + λ 1 N p o s ∑ i q c ∗ , i L b b o x ( b b o x i , b b o x i ∗ ) \textrm{Loss}=\frac{1}{N_{pos}}\sum_i\sum_c\textrm{VFL}(p_{c,i},q_{c,i}) +\frac{\lambda_0}{N_{pos}}\sum_iq_{c^*,i}\mathrm{L_{bbox}}(\mathrm{bbox_i'},\mathrm{bbox_i^*}) +\frac{\lambda_1}{N_{pos}}\sum_iq_{c^*,i}\mathrm{L_{bbox}}(\mathrm{bbox_i},\mathrm{bbox_i^*}) Loss=Npos1i∑c∑VFL(pc,i,qc,i)+Nposλ0i∑qc∗,iLbbox(bboxi′,bboxi∗)+Nposλ1i∑qc∗,iLbbox(bboxi,bboxi∗)其中 p c , i p_{c,i} pc,i和 q c , i q_{c,i} qc,i分别表示FPN每一层特征图上位置 i i i处类别 c c c的预测和目标IACS。 L b b o x \mathrm{L_{bbox}} Lbbox是GIoU Loss, b b o x i ′ \mathrm{bbox_i'} bboxi′、 b b o x i \mathrm{bbox_i} bboxi和 b b o x i ∗ \mathrm{bbox_i^*} bboxi∗分别表示初始边界框、优化后的边界框和真值边界框。我们用训练目标 q c ∗ , i q_{c^*,i} qc∗,i对 L b b o x \mathrm{L_{bbox}} Lbbox加权,沿用FCOS,前景点的 q c ∗ , i q_{c^*,i} qc∗,i是gt_IoU否则是0。 λ 0 \lambda_0 λ0和 λ 1 \lambda_1 λ1是 L b b o x \mathrm{L_{bbox}} Lbbox的平衡权重,本文根据经验分别设置为1.5和2.0。 N p o s N_{pos} Npos是前景点的数量,用于归一化总损失。如第3节所述,我们在训练时使用ATSS来定义前景点和背景点。
推理阶段。 VFNet的推理阶段就是直接把输入图像前向传播然后NMS后处理去除冗余检测。
5. Experiments
介绍了数据集、评价指标、实现和训练细节和推理细节。具体的内容可以参照原文。
5.1. Ablation Study
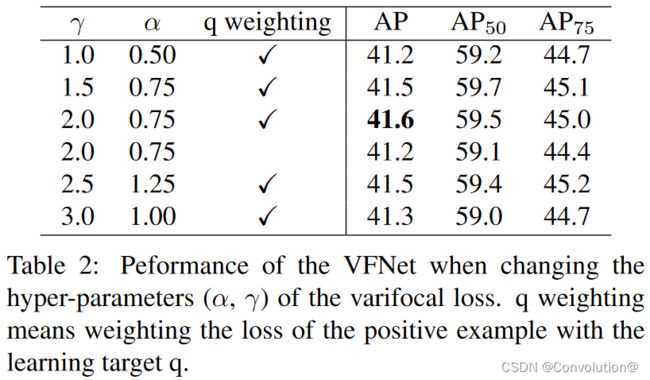
首先Varifocal Loss中两个超参数 α \alpha α和 γ \gamma γ的取值影响,前者是用于平衡正负样本的损失,后者是用于给简单负样本的损失降权。实验表明Varifocal Loss相当鲁棒,最好的取值是 α = 0.75 \alpha=0.75 α=0.75和 γ = 2.0 \gamma=2.0 γ=2.0,后续实验也使用这个取值。此外,对正样本损失使用训练目标 q q q加权也能带来积极作用,如第4行所示。具体的实验结论可以参照原文。
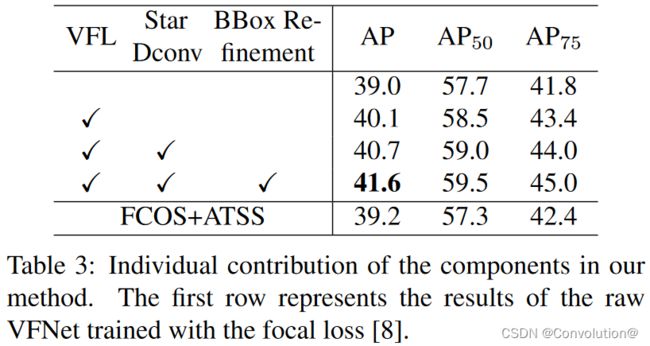
然后验证了VFNet中新加入的各个组件都是有效的,具体的实验结论可以参照原文。
5.2. Comparison with State-of-the-Art
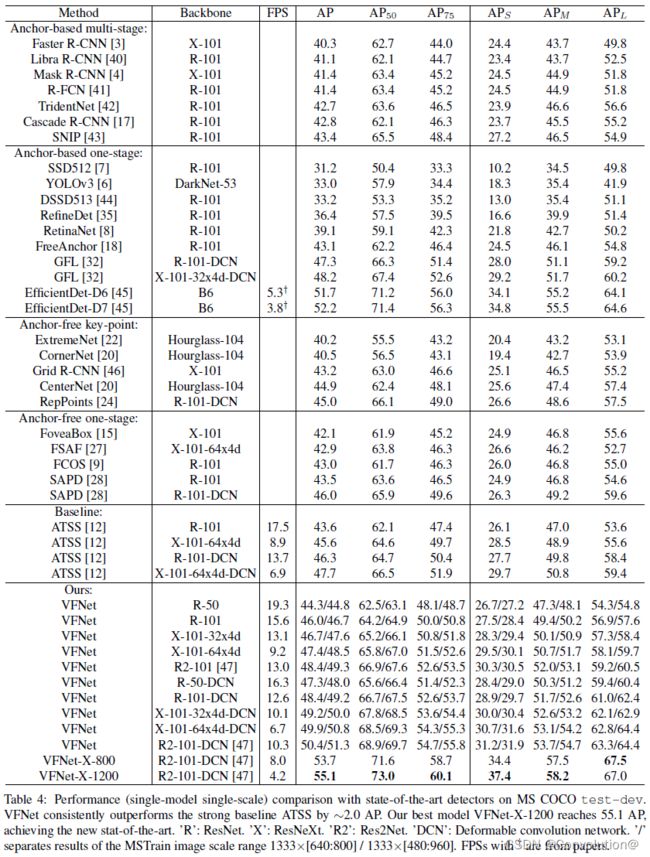
和SOTA相比,VFNet在精度和速度上都有优势,具体的实验结论可以参照原文。
5.3. VarifocalNet-X
VFNet加入一些trick后得到VFNet-X,效果更甚,如表4最后一行所示。具体使用的trick和相应的实验结论可以参照原文。
5.4. Generality and Superiority of Varifocal Loss
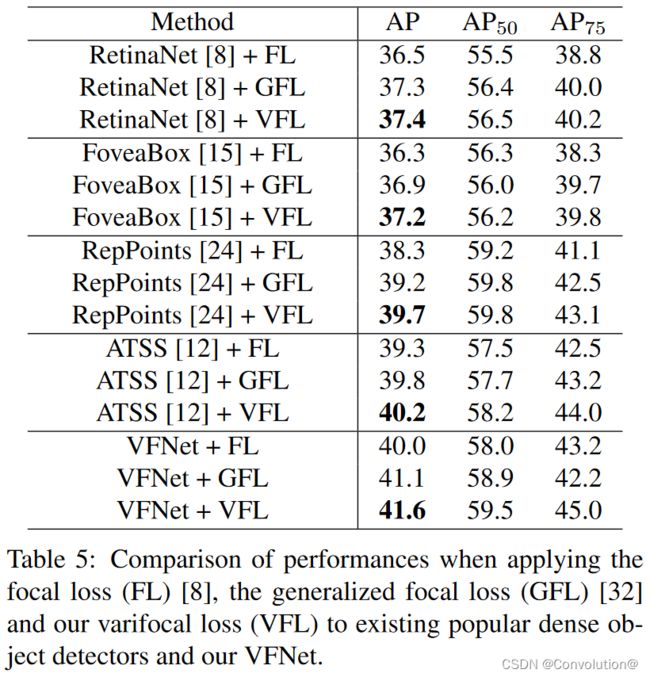
Varifocal Loss在不同模型上的泛化能力很好,并且比GFL要更好,具体的实验结论可以参照原文。
6. Conclusion
在本文中,我们提出学习IACS进行检测排序。我们首先说明了生成IACS对边界框进行排序的重要性,然后开发了一个稠密目标检测器VarifocalNet,以利用IACS的优势。特别地,我们设计了用于训练检测器预测IACS的Varifocal Loss,以及用于IACS预测和边界框优化的星形边界框特征表示。在MS COCO基准测试集上的实验验证了我们方法的有效性,并表明我们的VarifocalNet在各种目标检测器中取得了SOTA的性能。