Read summary of 《Security Vulnerability Detection Using Deep Learning Natural Language Processing 》
Read summary of 《Security Vulnerability Detection Using Deep Learning Natural Language Processing 》
- Ⅰ:The core content of this paper
- Ⅱ:proper noun
-
-
- 1.Attention Mechanism:
- 2.Transformer Model:
- 3.BERT Model(Bidirectional Encoder Representation from Transformers):
- 4.Long Short-Term Memory(LSTM) Model
- 5.BILSTM Model(Bi-directional LSTM)
- 6.Transfer learning:
- 7.Transformer-xl:
-
- Ⅲ:PERFORMANCE EVALUATION
-
-
- Accuracy:
- FLOPs:
- Unique Tokens:
-
- Ⅳ:Reading Experience
Ⅰ:The core content of this paper
There are various traditional ways to detect Security Vulnerability. In most cases,they can be divied into tow categories:
1:Static Code Analysis:
It can analyze the source code of the program and looking for code that violates the coding rules. but, such analysis tools are error-prone,and wich give more false positives than ture positives when assessing code for security vulnerabilities.
2:Dynamic Code Analysis
This approach tries to find problems in the code by running it on the processor with various extreme values as input, and then looks for inconsistencies or bugs in the output. However, these tests typically require programmers to write in the form of unit and integration tests, are cumbersome to use, and often test inputs beyond the scope of reasonably expected code. Furthermore, dynamic code analysis can only test for problems that the programmer has anticipated, which is usually not the case for security vulnerabilities.
For the above reasons, the author proposes the concept of using transformer for software vulnerability detection.
The traditional transformer model is mainly used in the fields of natural language processing (NLP) and computer vision (CV). In this paper, software vulnerability detection is modeled as a natural language processing (NLP) problem, combined with transfer learning, and high-performance transformer models are designed so that it can use the original code as an input sequence. At the same time, a data set of software vulnerabilities is created for testing. This demonstrates the feasibility of transformers in detecting software vulnerabilities.
Ⅱ:proper noun
1.Attention Mechanism:
Attention Mechanism is a technique that mimics cognitive attention in artificial neural networks. This mechanism can strengthen the weight of some parts of the input data of the neural network, while weakening the weight of other parts, so as to focus the attention of the network on the most important small part of the data. Which parts of the data are more important than others depends on the context.
2.Transformer Model:
Transformer model is a deep learning model using a self-attention mechanism, which can assign different weights according to the importance of each part of the input data. The Transformer model is designed to process sequential input data such as natural language, and can be applied to tasks such as translation and text summarization.
For a natural language processing task, people often choose the RNN model that is good at capturing sequence relationships, but for translation tasks, the number of words between sentences is not one-to-one.

Restricted by the structure, RNN can only realize N to N, N to 1, and 1 to N problems, but cannot solve such as N to M problem well.
Therefore, people proposed the SEQ2SEQ model. The SEQ2SEQ model has an Encoder and a Decoder, and the Encoder and Decoder are still RNN networks. In the translation task, the encoder first extracts the meaning of the original sentence, and then the decoder converts the meaning into the corresponding language. By using “meaning” as the middleware, SEQ2SEQ can solve the situation that the words at both ends are not equivalent.
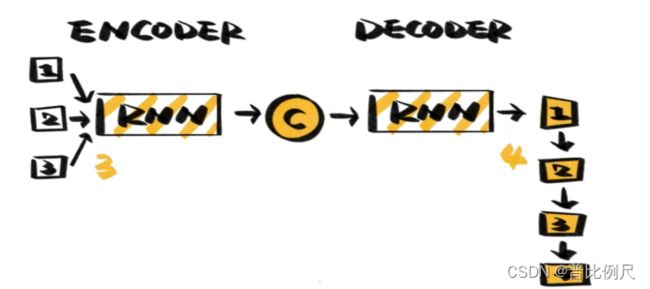
However, this translation method relies heavily on the storage space of the intermediate “meaning” unit. If a sentence is too long, the accuracy of the translation will inevitably be lost.
So people introduced Attention again. When generating each word, based on the original basic structure, consciously extract the information most needed to generate the word in the original sentence, thus getting rid of the length limit of the input sequence.
But, this calculation method is too slow, and RNN needs to filter each word in the sentence one by one to give an output. So, people further found Self-Attention. First extract the meaning of each word, and then select the required information according to the order of generation. This translation method supports parallel computing and is also closer to human translation methods.
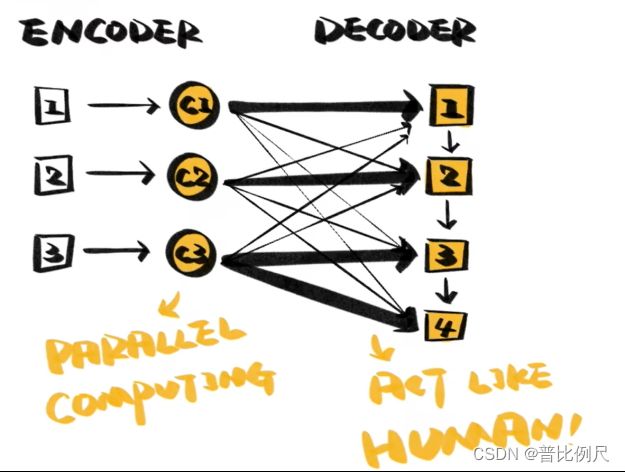
This model that got rid of the original RNN model structure and is completely based on the self-attention mechanism is Transformer.
Personal understanding:
Compared with RNN, transformer can have more layers. This deeply stacked conversion architecture allows the converter to outperform traditional models on various tasks. At the same time, the transformer has a memory function, and the content of the following text can affect the understanding of the previous text.
3.BERT Model(Bidirectional Encoder Representation from Transformers):
Computers cannot directly process human language, so humans use models to convert natural language into vectors composed of numbers based on the words in a sentence and the correlation between words. And BERT is one of the models that help humans find the position of words. The birth of BERT originated from transformer. By using Encoder, the “meaning” of language is separated and independent, so as to better represent the language. In addition, BERT also has a special training method, one of the masked language models. For the collected corpus, randomly block 15% of the vocabulary, and let BERT guess what these vocabulary are.
4.Long Short-Term Memory(LSTM) Model
A temporal recurrent neural network suitable for processing and forecasting important events in time series with very long intervals and delays. The traditional RNN model has a certain memory ability, but it can only save short-term information. According to the selection mechanism, the LSTM model retains important information and discards unimportant information. In the LSTM model, the concept of “gate” is proposed. “Gate” is similar to a switch, which is used to determine how to retain information. The value is in [0 ,1], 1 means completely reserved, 0 means completely discarded. There are three “gates” in LSTM:
- FORGET gate: It determines how much original information the model should retain, that is, which information is forgotten.
- INPUT gate: determines how much current network information will be saved in the small box, and determines which information can be retained.
- OUTPUT gate: decide how much to output information
In the LSTM model, the current network status can be understood through the INPUT gate, and important information in the past can also be retained through the FORGET gate.
5.BILSTM Model(Bi-directional LSTM)
Ordinary LSTM models process data one-way, that is, the previous text determines the subsequent text, while in natural language processing, the meaning of a word often needs to be judged by combining context. So the bi-directional LSTM model was introduced.
Personal understanding of the BiRNN model is that two RNNs are stacked up and down together, and do not interfere with each other in the process of processing data, but the final output is determined by the states of the two RNNs. For example, the result Y in the picture depends on A and A'.

6.Transfer learning:
Using the similarity between data, tasks, and models to transplant the trained content to new tasks, this process is called transfer learning. The transferred object is called the source domain, and the endowed object is called the target domain. Migration learning is not a specific model.
7.Transformer-xl:
A focused language model beyond fixed-length contexts, the paper of the same name was published in 2019. Transformer-xl solves the fixed-length context problem seen in other Transformer architectures, allowing long sequences of inputs without loss of performance. During evaluation in this paper, Transformer-XL outperforms the vanilla Transformer model on both short and long sequences, and is three orders of magnitude faster.
Ⅲ:PERFORMANCE EVALUATION
In data testing, in order to ensure fairness, all models were run for the same time on computers with the same configuration. The tested model combinations included LSTM, BILSTM, BERT+LSTM, and BERT+BILSTM. The method of testing is to decompose the complete sequence into fixed-size fragments, and then input them into the model.
This approach has the undesirable side effect that the model ignores contextual information before and after each segment. To solve this problem, we add a normal RNN which takes the output of each BERT segment. A softmax classifier is then applied to the final RNN output to obtain the final classification score.

Accuracy:
The final experimental results show that the combination of BERT+LSTM and BERT+BiLSTM has better accuracy.
Since the attention mechanism in the BERT model can extract context-aware information in a better way than LSTM or RNN alone, it is superior to traditional NLP models.
In addition, what is interesting is that if you simply compare the accuracy of LSTM and BILSTM, there is a gap of about 7% between them, indicating that BILSTM has been greatly improved compared to LSTM. But for the combination of BERT+LSTM and BERT+BiLSTM, the gap is only a negligible 0.3%, which may be explained by the fact that BERT has a built-in two-way mechanism, so even adding another two-way mechanism does not help the model to improve performance.
FLOPs:
It can be seen that the Accuracy of the model is at the cost of FLOPs,this means transformer-based models will take much more time to compute and will require more computational resources. Moreover, the relationship between FLOPs and accuracy indicates further work in more complex NLP architectures could further improve the accuracy of detecting security vulnerabilities.
Unique Tokens:
with the traditional NLP deep learning models than with the BERT models, which were capped at 32k unique tokens. This indicates that the BERT models generalized much better than the traditional models, and, therefore, expect to perform better when subjected to data outside our dataset.
Ⅳ:Reading Experience
I read this paper three times before I learned a little bit of knowledge. I am ashamed, compared with the paper itself, my understanding is still very limited, such as explanation of “how to process the code into data acceptable to the model? And how to perform vulnerability detection?” I still don’t understand clearly.
But In the process of reading papers, I have benefited a lot from the conceptual explanation query of proper nouns. For example, I used to think that artificial intelligence processes language in the same way as it processes images, recognizing text through pixels. But by querying the BERT model data, I understand that it is machine recognition that converts sentences into vectors for processing.
I will continue to read this paper.
Finally, I would like to thank the professor for guiding me and Shared such an excellent paper with me.