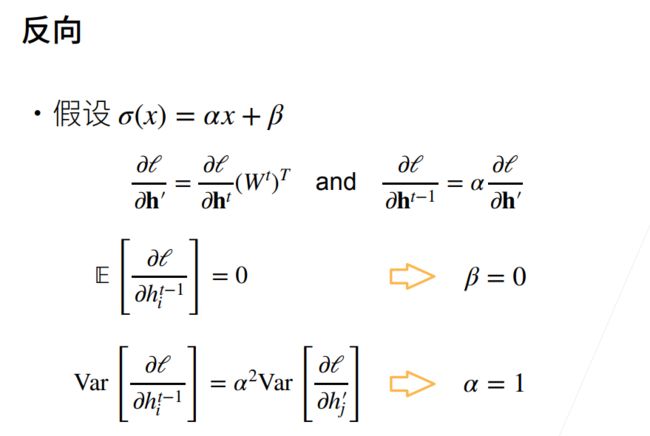李沐《动手学深度学习》课程笔记:14 数值稳定性 + 模型初始化和激活函数
目录
14 数值稳定性 + 模型初始化和激活函数
1.数值稳定性
2.模型初始化和激活函数
14 数值稳定性 + 模型初始化和激活函数
1.数值稳定性










考虑一个具有L层、输入x和输出o的深层网络。 每一层l由变换fl定义, 该变换的参数为权重W(l), 其隐藏变量是h(l)(令 h(0)=x)。 我们的网络可以表示为:
(4.8.1)h(l)=fl(h(l−1)) 因此 o=fL∘…∘f1(x).
如果所有隐藏变量和输入都是向量, 我们可以将o关于任何一组参数W(l)的梯度写为下式:
(4.8.2)∂W(l)o=∂h(L−1)h(L)⏟M(L)def=⋅…⋅∂h(l)h(l+1)⏟M(l+1)def=∂W(l)h(l)⏟v(l)def=.
换言之,该梯度是L−l个矩阵 M(L)⋅…⋅M(l+1) 与梯度向量 v(l)的乘积。 因此,我们容易受到数值下溢问题的影响. 当将太多的概率乘在一起时,这些问题经常会出现。 在处理概率时,一个常见的技巧是切换到对数空间, 即将数值表示的压力从尾数转移到指数。 不幸的是,上面的问题更为严重: 最初,矩阵 M(l) 可能具有各种各样的特征值。 他们可能很小,也可能很大; 他们的乘积可能非常大,也可能非常小。
不稳定梯度带来的风险不止在于数值表示; 不稳定梯度也威胁到我们优化算法的稳定性。 我们可能面临一些问题。 要么是梯度爆炸(gradient exploding)问题: 参数更新过大,破坏了模型的稳定收敛; 要么是梯度消失(gradient vanishing)问题: 参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
梯度消失
import torch
import matplotlib.pyplot as plt
from d2l import torch as d2l
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
y.backward(torch.ones_like(x))
d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()], legend=['sigmoid', 'gradient'], figsize=(4.5, 2.5))
plt.show()
梯度爆炸
import torch
from d2l import torch as d2l
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
M = torch.normal(0, 1, size=(4, 4))
print('一个矩阵\n', M)
for i in range(100):
M = torch. mm(M, torch.normal(0, 1, size=(4, 4)))
print('乘以100个矩阵后\n', M)一个矩阵
tensor([[-2.8753, 0.5506, 0.5894, 0.4806],
[-2.0750, 0.7418, 0.0458, -0.3233],
[ 0.7529, 0.0730, 0.3382, 1.0584],
[-0.7484, -1.0875, 1.4321, 0.0862]])
乘以100个矩阵后
tensor([[ 5.5158e+21, 5.5644e+21, 3.8531e+21, -9.4234e+20],
[ 2.9583e+21, 2.9844e+21, 2.0666e+21, -5.0541e+20],
[ 3.5856e+21, 3.6172e+21, 2.5048e+21, -6.1258e+20],
[-8.4640e+21, -8.5384e+21, -5.9127e+21, 1.4457e+21]])2.模型初始化和激活函数