【论文翻译】End-to-End Human Pose and Mesh Reconstruction with Transformers
【cvpr论文】End-to-End Human Pose and Mesh Reconstruction with Transformers (thecvf.com)
【github】microsoft/MeshTransformer: Research code for CVPR 2021 paper "End-to-End Human Pose and Mesh Reconstruction with Transformers" (github.com)
摘要
我们提出了一种新的方法,称为MEsh TRansfOrmer (METRO),从单张图像中重建三维人体姿态和网格顶点。该方法使用transformers编码器联合建模顶点-顶点和顶点-关节的相互作用,并同时输出三维关节坐标和网格顶点。与现有的回归姿态和形状参数的技术相比,METRO不依赖于任何参数网格模型,如SMPL,因此可以很容易地扩展到其他物体,如手。我们进一步放松了网格拓扑结构,允许变压器自注意机制在任意两个顶点之间自由参与,使得学习网格顶点和节点之间的非局部关系成为可能。通过提出的蒙面顶点建模,我们的方法在处理部分遮挡等具有挑战性的情况时更加健壮和有效。METRO在公共Human3.6M和3DPW数据集上生成新的最先进的人体网格重建结果。此外,我们展示了METRO在野外对3D手部重建的可泛化性,优于FreiHAND数据集上现有的最先进方法。
1.介绍
基于单幅图像的三维人体姿态和网格重建技术因其在虚拟现实、运动运动分析、神经退行性疾病诊断等方面的广泛应用而受到广泛关注。由于复杂的关节运动和咬合,这是一个具有挑战性的问题。
最近在这一领域的工作大致可以分为两类。第一类方法使用参数化模型,如SMPL[24],并学习预测形状和姿态系数[12,21,34,17,19,29,39,18]。这种方法已经取得了巨大的成功。参数模型中的强先验编码增强了模型对环境变化的鲁棒性。这种方法的缺点是位姿和形状空间受到用于构造参数模型的有限样本的约束。为了克服这一限制,第二类方法不使用任何参数模型[20,7,27]。这些方法要么使用图卷积神经网络来建模邻域顶点-顶点相互作用[20,7],或使用1D热图回归顶点坐标[27]。这些方法的一个局限性是它们在建模非局部顶点-顶点相互作用时效率不高。
研究人员已经证明,可能属于身体不同部位(例如手和脚)的非局部顶点之间存在很强的相关性。在计算机图形学和机器人技术中,逆运动学技术[2]已经被开发出来,用于在给定末端执行器(如手尖端)的位置的情况下估计关节图形的内部关节位置。我们认为,学习身体关节和网格顶点之间的相关性,包括近距离和长距离,对于处理身体形状重建中的挑战性姿势和咬合是有价值的。在本文中,我们提出了一个简单而有效的框架来建模全局顶点-顶点相互作用。我们框架的主要组成部分是一个transformer。
最近的研究表明,transformer[48]显著提高了自然语言处理中各种任务的性能[3,8,35,36]。成功主要归功于transformer的自注意机制,1954年,它在建模依赖关系(或相互作用)时特别有效,而不考虑它们在输入和输出中的距离。给定依赖关系,transformer能够对相关tokens进行软搜索,并根据重要特征进行预测[3,48]。
在这项工作中,我们提出METRO,一个多层transformer编码器逐步降维,从给定的输入图像,同时重建三维身体关节和网格顶点。我们设计了带有transformer编码器架构的带掩码的Vertex建模目标,以增强关节和顶点之间的相互作用。如图1所示,METRO学会了发现人体关节和网格顶点之间的短期和长期相互作用,这有助于更好地重建具有大姿态变化和咬合的三维人体形状。
在多个公共数据集上的实验结果表明,METRO在学习顶点-顶点和顶点-关节相互作用方面是有效的,因此在人类网格重建方面大大优于先前的工作。据我们所知,METRO是第一个利用transformer编码器架构从单个输入图像联合学习3D人体姿势和网格重建的方法。此外,METRO是一个通用框架,可以很容易地应用于预测不同的3D网格,例如,从输入图像重建3D手。
综上所述,我们作出以下贡献。
•我们引入了一种新的基于变压器的方法,名为METRO,用于从单张图像进行3D人体姿势和网格重建。
•我们设计了带有多层transformer编码器的带掩码的Vertex建模目标,以建模顶点-顶点和顶点-关节的相互作用,以便更好地重建。
•METRO在大规模基准Human3.6M和具有挑战性的3DPW数据集上实现了新的最先进的性能。
•METRO是一个多功能的框架,可以很容易地实现预测不同类型的3D网格,如在实验中演示的3D手。在论文提交时,METRO在FreiHAND排行榜上获得第一名。
2.相关工作
人体网格重建(Human Mesh Reconstruction, HMR):人体网格重建(Human Mesh Reconstruction, HMR)是一项对人体三维形体进行重建的任务,是近年来一个活跃的研究课题。虽然先锋工作已经展示了使用各种传感器(如深度传感器[28,43]或惯性测量单元[15,49])进行令人印象深刻的重建,但研究人员正在探索使用更高效和方便的单目相机设置。然而,由于复杂的姿态变化、遮挡和有限的3D训练数据,来自单张图像的HMR是困难的。
先前的研究建议采用预先训练好的参数化人体模型SMPL [24], STAR [30], MANO[38],并估计参数化模型的位姿和形状系数。由于直接从输入图像中回归姿态和形状系数具有挑战性,最近的工作进一步提出利用人体骨骼[21,34]或分割图[29]等各种人体先验,并探索不同的优化策略[19,17,46,12]和时间信息[18]来改善重建。
另一方面,除了采用参数化人体模型,研究人员还提出了从输入图像直接回归三维人体形状的方法。例如,研究人员已经探索使用3D网格[20,7]、体积空间[47]或占用场[41,42]来表示人体。前面的每个作品都针对其目标应用程序处理特定的输出表示。在文献中,相关的研究是GraphCMR[20],其目的是使用图卷积神经网络(graph convolutional neural networks, gcnn)回归3D网格顶点。此外,最近提出的Pose2Mesh[7]是一个使用gcnn的级联模型。Pose2Mesh基于给定的人体姿态表示重建人体网格。
虽然基于gcnn的方法[7,20]被设计用于基于预先指定的网格拓扑来建模邻域顶点-顶点相互作用,但在建模更远距离相互作用时效率较低。相比之下,METRO对关节和网格顶点之间的全局交互进行建模,而不受任何网格拓扑结构的限制。此外,我们的学习方法具有自我注意机制,这与以往的研究不同[7,20]。
注意力和Transformers:最近的研究[31,23,48]表明,注意力机制可以提高各种语言任务的表现。他们的关键见解是学习对软搜索相关输入的关注,这些输入对预测输出[3]很重要。V aswani等[48]进一步提出了一个完全基于注意机制的变压器架构。Transformer使用多头自注意进行高效的训练和推理,并在大规模语言建模中获得卓越的性能,正如BERT[8]和GPT[35, 36, 4]中所探讨的那样。
受到神经语言领域最近成功的启发,人们对探索transformer架构用于各种视觉任务的兴趣越来越大,例如学习图像生成[6,32]和分类[6,9]的像素分布,或将目标检测简化为集合预测问题[5]。然而,三维人体重建还没有沿着这一方向进行探索。
在这项研究中,我们提出了一个多层transformer结构,逐步降维,回归关节和顶点的三维坐标。

图2:建议框架的概述。给定一个输入图像,我们使用卷积神经网络(CNN)提取图像特征向量。我们通过将图像特征与每个身体关节i的三维坐标(xi, yi, zi)和每个顶点j的三维坐标(xj, yj, zj)连接在一起,在图像特征向量上添加一个模板人体网格来进行位置编码。给定一组关节查询和顶点查询,我们通过变压器编码器的多层进行自注意,并并行回归身体关节和网格顶点的三维坐标。我们使用渐进式降维架构(右)来逐层逐步降低隐藏的嵌入维数。最后一层中的每个标记输出关节或网格顶点的3D坐标。每个编码器块有4层和4个注意头。H为图像特征向量的维数。
3.方法
图2是我们提出的框架的概述。它以大小为224 × 224的图像作为输入,预测一组体关节J和网格顶点V。该框架由两个模块组成:卷积神经网络和多层transformer编码器。首先,我们使用CNN从输入图像中提取图像特征向量。接下来,多层变压器编码器将特征向量作为输入,并并行输出体关节和网格顶点的三维坐标。下面我们将详细描述每个模块。
3.1. 卷积神经网络
在我们框架的第一个模块中,我们使用卷积神经网络(CNN)进行特征提取。CNN在ImageNet分类任务[40]上进行预训练。具体来说,我们从最后一个隐藏层提取一个特征向量X。提取的特征向量X的维数通常为2048。我们为回归任务向变压器输入特征向量X。
通过这种通用设计,它允许对人体姿势和网格重建进行端到端训练。此外,transformer可以很容易地受益于大规模预训练的cnn,如HRNets[51]。在实验中,我们对输入特征进行了分析,发现高分辨率图像特征有利于变压器回归人体关节和网格顶点的三维坐标。
3.2. 多层transformer编码器与逐步降维
由于我们需要输出3D坐标,我们不能直接应用现有的transformer编码器架构[9,5],因为它们为所有transformer层使用了常量维数的隐藏嵌入。受[14]对多个块进行逐步降维的启发,我们设计了一种具有渐进降维方案的新架构。如图2右所示,我们在每个编码器层之后使用线性投影来降低隐藏嵌入的维数。通过添加多个编码器层,该模型被视为以交替的方式执行自关注和降维。我们的变压器编码器的最终输出向量是关节和网格顶点的三维坐标。
如左图2所示,transformer编码器的输入是体关节和网格顶点查询。与位置编码相同[48,20,11],我们使用模板人网来保存输入序列中每个查询的位置信息。具体来说,我们将图像特征向量X![]() 与每个体关节i的三维坐标(xi, yi, zi)串联起来,形成一组联合查询
与每个体关节i的三维坐标(xi, yi, zi)串联起来,形成一组联合查询![]() ,其中
,其中![]() 。类似地,我们对每个网格顶点j进行相同的位置编码,并形成一组顶点查询
。类似地,我们对每个网格顶点j进行相同的位置编码,并形成一组顶点查询![]() ,其中q
,其中q![]()
3.3. Masked Vertex Modeling 掩膜顶点建模
先前的工作[8,44]使用掩蔽语言建模(Masked Language Modeling,MLM)来学习训练语料库的语言特性。然而,MLM的目的是恢复输入,这不能直接应用到我们的回归任务。
为了充分激活变压器编码器中的双向关注,我们为回归任务设计了一个屏蔽Vertex建模(Masked Vertex Modeling,MVM)。我们随机屏蔽了一定百分比input queries 。与恢复像MLM[8]这样的屏蔽输入不同,我们要求转换器回归所有的关节和顶点。
为了预测与缺失query相对应的输出,模型将不得不求助于其他相关query,。这在思想上类似于模拟遮挡,其中部分身体部位是看不见的。因此,MVM强制transformer通过考虑其他相关的顶点和关节来回归3D坐标,而不考虑它们的距离和网格拓扑。这有助于关节和顶点之间的短期和长期交互,从而更好地进行人体建模。
3.4. Training
为了训练transformer编码器,我们在transformer输出上应用损失函数,并最小化预测和真实值之间的误差。给定一个数据集![]() ,其中T是训练图像的总数。
,其中T是训练图像的总数。![]() 表示RGB图像。
表示RGB图像。![]() 为网格顶点的ground truth 3D坐标,M为顶点个数。
为网格顶点的ground truth 3D坐标,M为顶点个数。
![]() 为人体关节的ground truth 3D坐标,K为人的关节数。同样地,
为人体关节的ground truth 3D坐标,K为人的关节数。同样地,![]() 表示身体关节的ground truth 2D坐标。
表示身体关节的ground truth 2D坐标。
![]() 表示输出顶点位置,
表示输出顶点位置,![]() 表示输出关节位置,我们使用L1损失来最小化预测与ground truth之间的误差:
表示输出关节位置,我们使用L1损失来最小化预测与ground truth之间的误差:
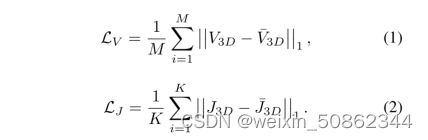
值得注意的是,三维节点也可以从预测网格中计算出来。参照文献[7,17,20,19]的常用做法,我们使用预定义的回归矩阵![]() ,通过
,通过![]() 得到回归后的三维关节。与之前的工作类似,我们使用L1损失函数来优化
得到回归后的三维关节。与之前的工作类似,我们使用L1损失函数来优化![]()

二维重投影已被普遍用于增强图像网格对齐[17,20,19]。此外,它还有助于在图像中可视化重建。受之前工作的启发,我们使用估计的摄像机参数将3D关节投影到2D空间,并将2D投影与2D地面真实值之间的误差最小化:

其中相机参数是通过使用transformer编码器输出上的线性层来学习的。
为了进行大规模训练,非常希望利用2D和3D训练数据集来更好地泛化。正如文献[29,17,20,19,18,7,27]中所探讨的那样,我们使用混合训练策略,利用不同的训练数据集,有或没有配对的图像网格注释。我们的总体目标如下:

其中α和β是每个训练样本的二进制标志,分别表示3D和2D ground truths的可用性。
3.5. 实现细节
我们的方法能够处理任意大小的网格。但是由于当前硬件内存限制,我们的transformer处理一个粗网格:(1)我们使用一个粗模板网格(431个顶点)进行位置编码,transformer输出一个粗网格;(2)我们使用可学习多层感知器(MLPs)将粗网格上抽样到原始网格(SMPL人体网格拓扑为6890个顶点);(3)对transformer和mlp进行端到端的训练;请注意,粗网格是用采样算法[37]对431个顶点进行两次子采样得到的。如文献[20]中所讨论的,学习一个粗网格然后上采样的实现有助于减少计算量。它还有助于避免原始网格中的冗余(由于顶点的空间局部性),这使得训练更有效。
4.实验结果
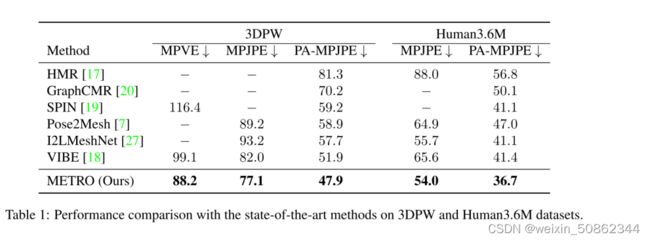
其他就不具体翻译了