机器学习小白阅读笔记:深度学习时序预测模型 Temporal Fusion Transformers
机器学习笔记:深度学习时序预测模型 Temporal Fusion Transformers
前言
由于接触的时序预测问题基本都来自于数字化转型期的企业,我经常发现,在解决实际时序预测问题的时候,大部分时候还是用树模型结合特征工程的思路,关键点往往都在数据和特征工程上,如果想要使用深度学习,有时候客户的数据量不满足,有时候客户的生产环境不允许。
我自己在一些时序预测问题,比如销量预测问题的比赛上,也做过一些尝试,发现深度学习模型里面,TFT 这个模型基本都能有不错的效果,所以就萌生了学习一下的想法,但是我对深度学习并不很熟悉,一直有一些畏难情绪,拖着没去细看,这一次也算是自顶向下地补足了一些知识,路线上遇到的好资料我也会附在文末的参考中。
毕业工作一年了,感觉自己在时序领域还是一个小白,有理解不对的地方还希望多多指教,通过输出来引发思考和指正也是我尝试写一些博客的初心,感谢阅读!
内容
本篇文章以了解 TFT 的机制和调包侠式使用为主,主要分享三个方面:
- TFT 模型有什么优点
- TFT 是如何运作的,以及是如何实现这些优点的
- 如何通过 Pytorch-forecasting 库直接使用 TFT 解决时序预测问题
TFT 的优点
-
多步预测
传统上的多步预测通常是单步预测迭代而来的,即将
t+1时刻的预测值,再作为模型的输入,反复迭代出多步的结果,这样会导致误差积累,就不如一次性预测多步的模型好,这样的模型往往在训练时,同时将多步的预测结果纳入loss函数的计算。TFT 采用 seq2seq 的思路,输入多个历史值,输出多个预测值
-
对不同类型的输入加以区分并分开利用
传统上时序预测时,比如我们把销量预测问题建模为回归任务,特征一般会包括:可提前预知的时间特征——星期几、月份、年份;不随时间改变的静态特征——商品的类别、店铺所在城市,等等。而这些特征我们通常作为一个特征向量,直接一股脑喂进模型训练,这样一来,不同类型的特征就是同等地位的。
而 TFT 对输入的特征做了严格的区分,分为静态变量——如商品的类别、店铺所在的城市、可知动态变量——如星期几、月份、年份这些提前就能知道的、不可知动态变量——如某店铺所有商品的平均销量,这种提前不可能知道的特征
-
输出的预测值并不是一个值,而是一个预测区间
在时序预测问题中,给出一个预测区间的模型往往比给出一个值的模型有实际意义得多,因为在每一个预测的时间步,预测的置信度是不同的,而预测基本都是给决策服务的,一个要利用预测信息进行决策的人,可以根据预测区间的宽窄去决定自己要多信赖这一次预测的结果,在实际应用中是很有价值的
-
可解释性
TFT 从三个方面体现自己的可解释性:
-
依赖它的
Variable Selection模块得到的——特征重要度:哪些特征更重要 -
依赖它的
Multi-head Attention模块得到的——输入的历史时间步被关注的情况:是否存在某些特定模式 -
在被关注模式的基础上进一步研究数据集的时序是否发生过重大变化,比如每家商店的每个商品就是一条时序,标识为 store-item,那么通过计算不同时序被关注模式的距离,就可以发现一些
significant events出现的时间点
-
TFT 的结构
TFT 核心思路是采用 Encoder-Decoder 的模式,将输入的各个历史时刻的特征,以及要输入到未来的各个时刻的特征,分别进行一系列处理(后面会具体说明),变成一个抽象的表征,然后再输入到Encoder和Decoder中,在Decoder部分,要预测多少步就有多少个输出值,每个输出值都来自于,对它之前的所有值的attention结果,也就是说,给该预测时刻之前的各个时刻分配权重,然后计算出一个加权的结果。
输出的抽象结果会再经过一些处理,把它变成对于10th、50th、90th这几个分位数的预测,从而获得预测区间。
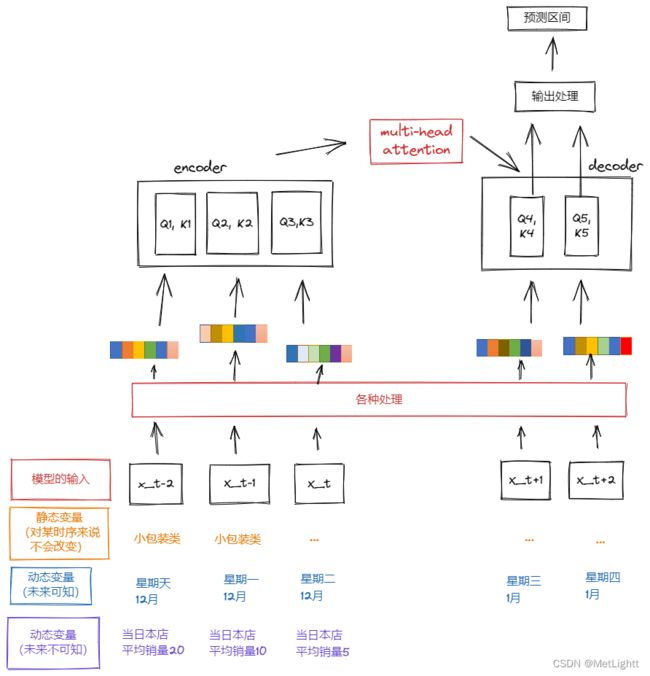
Multi-head Attention
这里简单说明一下Attention机制
最早的Encoder-Decoder设计中,Encoder会把过去的历史输入信息全部整合,变成一个中间信息,再由中间信息在decoder中解码
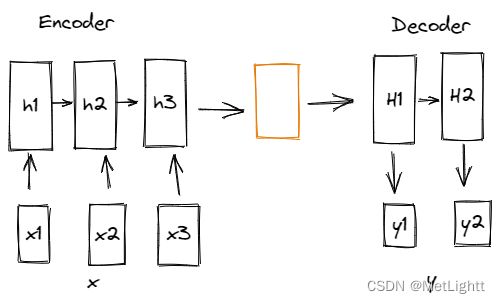
这样存在的问题是,如果输入的序列太长,信息太多,中间信息的长度总是固定的,它的信息容量有限。于是就有人想,那如果在整合历史信息的环节,加一个可以学习的注意力机制,就可以让网络有选择地去整合历史信息。
为了让这个机制本身具备学习能力,为每一个输入都准备了3个矩阵——W_Q, W_K, W_V。
对于输入x,3个矩阵代表三种变换方式,可以理解为3种理解x的方式——x * W_Q得到 x 作为匹配项时应该如何理解,x * W_K得到 x 作为被匹配项时如何理解,x * W_V 探索出 x 的实际含义。举个例子,此时的输入是一个没见过的词Mosi Mita,现在我想知道它的真正含义,网络首先要思考,它和之前输入的哪些词相关(之前输入的词每个也都有三种理解含义),我们通过“Mosi Mita” * W_Q得到它作为匹配项的时候应该如何理解,记为Q,然后之前输入的词全都和W_K相乘,得到这些之前的词作为被匹配项时应该如何理解,记为K_1, K_2, K_3, ...计算 Q 和每一个 K 的得分,就是每个K应该被施予的注意力权重,加权求和我们就得到了注意力得分。
在输出 y2 时,对之前的词的注意力得分、上一个输出值 y1、上一个隐含状态 H1 共同作为输入,计算出 y2 时对应的隐含状态 H2,然后通过 H2 就可以计算得到 y2
而 Multi-head Attention,就是为每一个词,准备了多组 W_Q, W_K, W_V,这样一来,不光一个词有3个理解,对同一个词,每个脑袋都有3个理解,最终将多个脑子的理解汇总一下,比如加权平均一下,就能得到最终的注意力得分
这里我隐去了相当多的细节,后面我会在参考中附上对我理解attention非常有帮助也更详细的大佬的文章,现在我们只需要知道,在 TFT 中,输入的不同时刻的特征,处理后就相当于多个词,而 TFT 也会用比如 Decoder Masking这样的机制,来保证矩阵运算时,每个 k 时刻的输出只在之前的所有时刻计算注意力得分
对于输入的各种处理
在我画的简略结构图中,隐去了很多网络的细节,以便能够自顶向下进行说明,现在我们可以更深一步,看看网络真实的样子,并暂时只关注输入处理部分,即输入到 Multi-head Attention 之前的部分
输入的内容
最底部的 Static Metadata, Past Inputs, Known Future Inputs 并不是上面的简略结构图中的分类特征、可知连续变量特征和不可知连续变量特征,而是这些特征进行变换之后的向量,比如分类型变量通过entity embedding,连续型变量通过linear transformations,统一为长度为 d_model 维的向量
Variable Selection
GRN(Gated Residual Network)
Variable Selection 由 GRN 模块组装而成,GRN 模块在整个 TFT 网络中都频繁出现,它的结构为
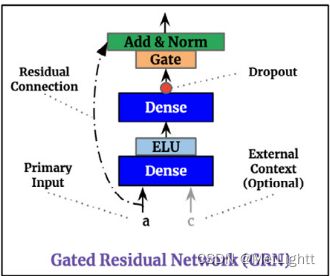
G R N ( a , c ) = L a y e r N o r m ( a + G L U ( η 1 ) ) , η 1 = W 1 η 2 + b 1 [ D e n s e 层的效果 ] η 2 = E L U ( W 2 a + W 3 c + b 2 ) GRN(a, c) = LayerNorm(a + GLU(η_1)),\\ η_1 = W_1η_2 + b_1\ [Dense层的效果] \\ η_2 = ELU(W_2a + W_3c + b_2) GRN(a,c)=LayerNorm(a+GLU(η1)),η1=W1η2+b1 [Dense层的效果]η2=ELU(W2a+W3c+b2)
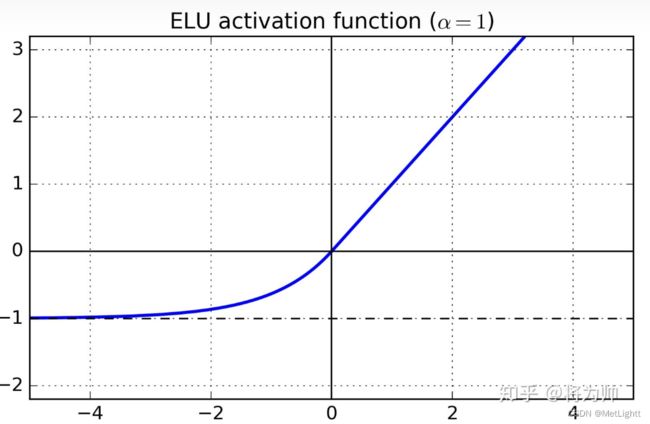
ELU(Exponential Linear Unit)是优化版RELU激活函数,函数图像为
而Gate(GLU)做的事情是,对输入γ进行线性变换后的向量,和该向量经过sigmoid函数激活的结果(取值属于(0,1)),元素对应位置相乘。这样一来,信号有的变大有的变小,甚至有的会趋于0,由此实现了adaptive depth
G L U ( γ ) = σ ( W 4 γ + b 4 ) ⊙ ( W 5 γ + b 5 ) GLU(γ) = σ(W_4γ + b_4)\odot (W_5γ + b_5) GLU(γ)=σ(W4γ+b4)⊙(W5γ+b5)
此外,残差连接是比较常规的操作,允许本层网络啥也不学,也是让网络的深度更具有灵活性,也保护了梯度
Variable Selection networks
了解了GRN模块在做的事情——让网络以一种高灵活性的方式变深,之后,大概就能理解为什么 GRN 这个模块在 TFT 网络里为什么塞得到处都是,接下来回到我们上面标出的“处理部分”,看一下对于输入的向量的第一层处理——Variable Selection
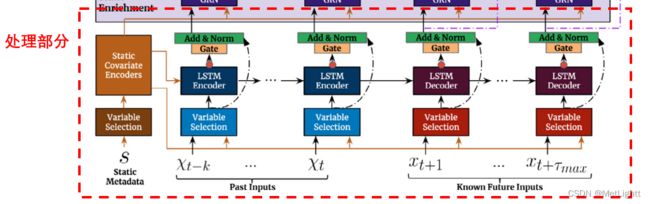
首先,输入的静态特征,会经过4个不同的GRN,分别得到C_s, C_c, C_h, C_e这 4 个context vectors,其中C_s就是用于变量筛选的
如上图所示,某个 t 时刻,输入的各个特征各自经过一个GRN,得到新的向量,而组合起来并加上C_s的向量则通过GRN和softmax变成了各个向量对应的权重,这些权重和向量加权求和,就得到了一个全新的特征向量,该向量整合了所有输入的特征向量经过选择之后的信息,是输入的一系列特征的高度抽象
LSTM Seq2Seq层
这一层我看源码 LSTM Encoder 和 LSTM Decoder使用的其实都是nn.LSTM,所以他们应该是一样的,在这里起到的是对特征筛选结果进一步抽象的作用,可以类比GRN结构看,也通过skip connection和Gate保证深度的灵活性,只是变换方式,从Dense+ELU改为了LSTM的遗忘、记忆、选择性输出机制,可以更好的捕捉序列的长期信息
LSTM的结构(From 台大李宏毅老师)
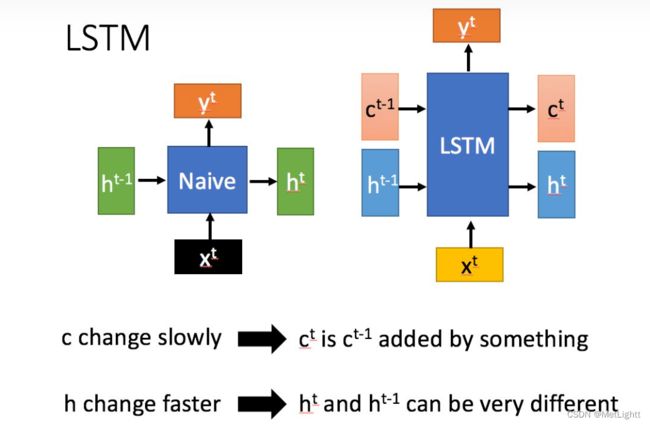
可以看到相比RNN传递一个隐藏状态h,LSTM有两个状态需要传递,c_t 和 h_t,而这二者就用我们上面说到的C_c 和 C_h 初始化,这么做的目的是把静态变量信息也作为影响长短期信息捕捉的影响因素之一,在时序预测任务中,一个值的前后变化跨越多远的距离相互影响,应该受到它所属的类别等信息影响,确实是一个比较直观好理解的想法
Static Enrichment Layer 和 Position-wise feed forward Layer
处理部分结束后,进入到Decoder部分,在我们之前说过的Multi-head Attention前后还有两次处理,比较简单好理解,无非就是再一次利用GRN,以灵活的方式增加网络的深度,从而增强学习能力
Static Enrichment layer
这一层就是再一次利用GRN,把由静态特征经过4个GRN之一得到的C_e再一次和经过LSTM层抽象的特征向量组合,目的是把静态特征信息再融合一次
Position-wise feed forward Layer
这一层把Multi-head attention的输出——每个预测时刻进行预测时,对前面各项施予注意力的结果,通过了一个共享权重的GRN,也就是说,在预测输出时,每个时刻到这里都经过同一个GRN,所以对forecasting horizon内的各步,这里的操作是一视同仁的,能够保证attention的结果不被有偏的GRN稀释,但是同时又让网络更深了
Output Dense
输出层的线性变换目的是把抽象的输出,变换为可以解读成10th, 50th, 90th的预测值的形式(而这个“解读”方式因为使用Dense,所以也是网络要学习的事情之一),通过10th, 50th, 90th几个分位数的预测值,可以获得这个时刻预测结果的预测区间
分位数预测的结果在计算Loss时,比较好理解,网上也有很多资料,这里不赘述,通常核心在于
Q L = m a x ( 0 , q ( y − y ^ ) ) + m a x ( 0 , ( 1 − q ) ( y ^ − y ) ) QL = max(0, q(y-\hat y)) + max(0, (1-q)(\hat y - y)) QL=max(0,q(y−y^))+max(0,(1−q)(y^−y))
当q比较小,即预测的分位数比较小时,预测值偏大的Loss取决于加号右侧,预测值偏小的Loss取决于加号左侧,因为此时1-q > q,模型更倾向于回避Loss大的情景,会倾向于让预测值向小的方向移动;
同理q比较大时,模型会倾向于预测值向大的方向移动
如何使用Pytorch-forecasting中的TFT
大致理解了 TFT 的机制后,可以通过 pytorch-forecasting 上手试一试,对 API 也会有更好的理解
-
load data
要使用pytorch-forecasting中的TFT,传入的dataframe不能用时间或者日期标识时间,而需要一列integer表示先后的值,小的数表示先,大的数表示后
-
TimeSeriesDataSet
# define dataset max_encoder_length = 36 max_prediction_length = 6 training_cutoff = "YYYY-MM-DD" # day for cutoff training = TimeSeriesDataSet( data[lambda x: x.date < training_cutoff], time_idx= ..., target= ..., # weight="weight", group_ids=[ ... ], max_encoder_length=max_encoder_length, max_prediction_length=max_prediction_length, static_categoricals=[ ... ], static_reals=[ ... ], time_varying_known_categoricals=[ ... ], time_varying_known_reals=[ ... ], time_varying_unknown_categoricals=[ ... ], time_varying_unknown_reals=[ ... ], ) # create validation and training dataset validation = TimeSeriesDataSet.from_dataset(training, data, min_prediction_idx=training.index.time.max() + 1, stop_randomization=True) batch_size = 128 train_dataloader = training.to_dataloader(train=True, batch_size=batch_size, num_workers=2) val_dataloader = validation.to_dataloader(train=False, batch_size=batch_size, num_workers=2)需要初始化为 TimeSeriesDataSet,其中的 time_varying_known, time_varying_unknown就对应我们前面介绍的输入部分,它们要区分开categoricals和reals,应该就是因为categoricals要进行embedding,而reals要进行linear transformation
除此以外,这部分还有很多别的参数,可以参考官方文档添加,如:
- categorical_encoders,如果未来会出现没见过的categoricals,这里就可以使用NaNLabelEncoder(add_nan=True)
- 从
pytorch_forecasting.data.encodersimport即可,在官方文档的getting-started/example中可以看见Main API
- 从
- add_xxx:add开头的都是一些特征添加,比如是否添加相对的time_index作为feature
- allow_missing_timsteps:如果你的时间是有残缺的
- categorical_encoders,如果未来会出现没见过的categoricals,这里就可以使用NaNLabelEncoder(add_nan=True)
-
train
接下来构建一个study,寻找最优超参,官方文档都说得很详细。不过一般在寻找到最优参数以后,我们会使用全部的数据,和这组最优的参数,以及early_Stopping看到的epochs的数目,重新训练模型,再用新模型去预测测试集的数据,作为我们最终参与评估考核的结果。
这里参考官方文档中利用pytorch_lightning的trainer就可以,无非就是重新训练的时候,train_loader是通过TimeSeriesDataSet的API基于所有的数据构造的,val_dataloader设置为None
-
predict
如果是在用TimeSeriesDataSet提供的API构造好的val_Dataloader上做Predict是很简单的,所有的TimeSeriesDataSet内部都帮你构造好了,这里参考官方文档就可以
但在预测新到来的数据的时候,官方文档感觉说得不太清楚,在没有前面对TFT的了解之前是很难明白的。因为TimeSeriesDataSet并不能构造一个没有target的数据集,所以我们必须通过手动构造的方式。先看看官方的例子:
# select last 24 months from data (max_encoder_length is 24) encoder_data = data[lambda x: x.time_idx > x.time_idx.max() - max_encoder_length] # select last known data point and create decoder data from it by repeating it and incrementing the month # in a real world dataset, we should not just forward fill the covariates but specify them to account # for changes in special days and prices (which you absolutely should do but we are too lazy here) last_data = data[lambda x: x.time_idx == x.time_idx.max()] decoder_data = pd.concat( [last_data.assign(date=lambda x: x.date + pd.offsets.MonthBegin(i)) for i in range(1, max_prediction_length + 1)], ignore_index=True, ) # add time index consistent with "data" decoder_data["time_idx"] = decoder_data["date"].dt.year * 12 + decoder_data["date"].dt.month decoder_data["time_idx"] += encoder_data["time_idx"].max() + 1 - decoder_data["time_idx"].min() # adjust additional time feature(s) decoder_data["month"] = decoder_data.date.dt.month.astype(str).astype("category") # categories have be strings # combine encoder and decoder data new_prediction_data = pd.concat([encoder_data, decoder_data], ignore_index=True) new_raw_predictions, new_x = best_tft.predict(new_prediction_data, mode="raw", return_x=True)这里有一个问题官方并没有说清楚,我们的一次输入实际上是这样的

我们把最末尾的 Encoder_length + 新构造的测试集的Decoder_length(prediction steps) 行数据输入,encoder 行的特征都是已知的,而 decoder 行有一部分的特征是未知的,所以这里把它们forward_fill,取encoder的值就好了,因为在初始化TimeSeriesDataSet的时候,已经指明了哪些是未来不可知的,输入模型以后,应该会自动按照长度处理
我在Kaggle上看到的一个人的实操案例是这样的:
# select last 30 days from data (max_encoder_length is 24)
encoder_data = df_train[lambda x: x.time_idx > x.time_idx.max() - max_encoder_length]
last_data = df_train[df_train['time_idx'].isin([idx - prediction_steps for idx in df_test['time_idx'].unique()])]
last_data['time_idx'] = last_data['time_idx'] + prediction_steps
decoder_data = pd.merge(df_test[[col for col in df_test.columns if 'sales' not in col]],
last_data[['time_idx','store_nbr', 'family', 'sales', 'average_sales_by_family', 'average_sales_by_store' , 'transactions']],
on = ['time_idx', 'store_nbr', 'family',]
)
# combine encoder and decoder data
new_prediction_data = pd.concat([encoder_data, decoder_data], ignore_index=True)
他的decoder_data = pd.merge()的操作,就会导致df_test那部分未知的数据,直接使用encoder最后的prediction steps 长度内的数据。
比如decoder_data中,因为要预测的是sales,average_sales_by_family, average_sales_by_store, transactions就都会是未知的,这一部分输入他直接在 df_train 里取了等同于prediction steps的最末几个时间,作为last data,把他们的unkown inputs直接合并了
看github上的源码的话,可以发现,输入的 df 按照列全部 embedding,然后这些列被分为unknown_inputs, known_combined_layer, obs_inputs, static_inputs;而所有行被分为historical_inputs和future_inputs,future_inputs只会从known_combined_layer列里面取,因此个人认为在测试部分,unknown的部分数据如何构造,应该按照以上forward_fill或者merge最后一段,都是可以的,唯一的要求就是不能embedding失败
后记
头一回写这么长的博客,五千字写了一整天,markdown也不是很熟悉,思考结构和逻辑也思考了很久,写着写着又要开始疯狂查资料,然后想想又觉得哪里应该补一个图,但是写完的一刻还是觉得蛮有成就感的,至少是善始善终了!
如果里面有任何我理解错误的地方,还希望可以帮我指出,多多指教!
References
- Lim B, Arık S Ö, Loeff N, et al. Temporal fusion transformers for interpretable multi-horizon time series forecasting[J]. International Journal of Forecasting, 2021, 37(4): 1748-1764.
- 雅正冲蛋——知乎:小白也能懂的Attention机制讲解
- Kaggle TFT案例
- pytorch-forecasting Demand Forecasting tutorail