预训练词嵌入Pretrained Word Embeddings
介绍
我们如何让机器理解文本数据?我们知道,机器在处理数字数据方面非常擅长,但如果我们把原始的文本数据提供给它们,它们的效果会很差。
我们的想法是创建一个词的表征,捕捉它们的含义、语义关系和它们使用的不同类型的语境。这就是词语嵌入–文本的数字表示。
而预训练的词嵌入是当今自然语言处理(NLP)领域的一个关键齿轮。
但是,问题仍然存在–预训练的词嵌入是否给我们的NLP模型带来了额外的优势?这是一个你应该知道答案的重要问题。因此,在这篇文章中,我将对预训练词嵌入的重要性进行一些说明。我们还将比较预训练的词嵌入和从头开始学习嵌入在情感分析问题上的表现。
目录
- 介绍
- 什么是预训练词嵌入?
- 为什么我们需要预训练的词嵌入
-
- 训练数据的稀缺性
- 大量的可训练参数
- 什么是不同的预训练词嵌入?
- Google’s Word2vec预训练词嵌入
- Stanford’s GloVe预训练词嵌入
什么是预训练词嵌入?
预训练的词嵌入是指在一个任务中学习的嵌入,用于解决另一个类似的任务。
这些嵌入是在大型数据集上训练的,保存起来,然后用于解决其他任务。这就是为什么预训练的词嵌入是迁移学习的一种形式。
转移学习,顾名思义,就是把一个任务的学习内容转移到另一个任务中。学习的内容可以是权重,也可以是词嵌入。在我们这里,学习的内容是词嵌入。因此,这个概念被称为预训练的词嵌入。在权重的情况下,这个概念被称为预训练的模型。
但是,为什么我们首先需要预训练的词嵌入?为什么我们不能从头开始学习我们自己的嵌入?我将在下一节中回答这些问题。
为什么我们需要预训练的词嵌入
预先训练的词嵌入可以捕捉到一个词的语义和句法含义,因为它们是在大型数据集上训练的。它们能够提高自然语言处理(NLP)模型的性能。
但为什么我们不应该学习自己的嵌入呢?有两个主要原因,从头开始学习词的嵌入是一个具有挑战性的问题。
- 训练数据的稀缺性
- 大量的可训练参数
训练数据的稀缺性
不这样做的主要原因之一是训练数据的稀少性。大多数现实世界的问题都包含一个有大量稀有词的数据集。从这些数据集中学到的词嵌入不能得出正确的词的表示。
为了达到这个目的,数据集必须包含丰富的词汇。经常出现的词正是建立了这样一个丰富的词汇表。
大量的可训练参数
其次,在从头开始学习词嵌入时,可训练参数的数量增加。这导致了较慢的训练过程。从头开始学习词嵌入也可能让你对单词的表示方法不清楚。
因此,上述所有问题的解决方案是预训练的词嵌入。让我们在接下来的章节中讨论不同的预训练词嵌入。
什么是不同的预训练词嵌入?
我大致将嵌入分为两类。词级嵌入( Word-level embeddings)和字符级嵌入(Character-level embeddings)。ELMo和Flair嵌入是字符级嵌入的例子。在这篇文章中,我们将介绍两个流行的词级预训练的词嵌入。
- Googles’s Word2Vec
- Standford’s GloVe
Google’s Word2vec预训练词嵌入
Word2Vec是由谷歌开发的最流行的预训练词嵌入之一。Word2Vec是在谷歌新闻数据集(约1000亿字)上训练的。它有几个用例,如推荐引擎、知识发现,也适用于不同的文本分类问题。
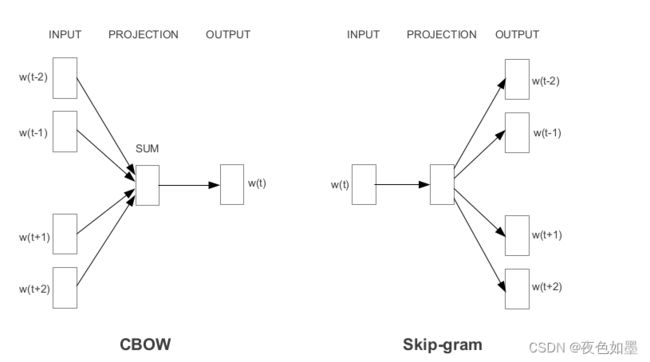
根据学习嵌入的方式,Word2Vec被分为两种方法。
- Continuous Bag-of-Words(CBOW)
- Skip-gram model
CBOW通过neighboring words学习focus word,而Skip-gram通过给定的focus word学习neighboring words。这就是为什么CBOW和Skip-gram是互相inverse的。
例如,对于这个句子:“I have failed at times but I never stopped trying”。我们想要学习单词“failed”的词嵌入,因此我们的focus word就是“failed”
第一步是定义一个上下文窗口(context window)。context window指的是出现在focus word前后的词的数量。出现在context window的词即为neighboring words或者context。我们把context window固定为2并尝试上述两种方法:
- Continuous Bag-of-Words:Input = [I, have, at, times],Output = failed
- Skip-gram: Input = failed,Output = [I, have, at, times]
如上,CBOW接收多个词作为输入,并产生一个词作为输出,而Skip-gram接收一个词作为输入,并产生多个词作为输出。
因此,我们通过输入和输出来定义模型架构。需要注意的是,每个词都是以one-hot向量的形式输入模型的。
Stanford’s GloVe预训练词嵌入
GloVe的基本思想是从Global Statistics中推导词之前的相互关系。
但Statistics能代表什么?
最简单的方法是看co-occurrence矩阵,co-occurrence矩阵表示某对词出现在一起的频率。co-occurrence矩阵的每个值都是一对词一起出现的次数。
例如,有这样一个语料库,“I play cricket, I love cricket and I love football”。其co-occurrence矩阵就是这样:
| play | love | football | I | cricket | |
|---|---|---|---|---|---|
| play | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 |
| love | 0.0 | 0.0 | 1.0 | 2.0 | 1.0 |
| football | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| I | 1.0 | 2.0 | 0.0 | 0.0 | 0.0 |
| cricket | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 |
我们可以计算出一对单词出现的概率。简单旗舰,我们focus单词"cricket"。
p ( c r i c k e t / p l a y ) = 1 p ( c r i c k e t / l o v e ) = 0.5 p(cricket/play) = 1 \\ p(cricket/love) = 0.5 p(cricket/play)=1p(cricket/love)=0.5
计算两者的ratio = p ( c r i c k e t / p l a y ) p ( c r i c k e t / l o v e ) = 2 > 1 =\frac{p(cricket/play)}{p(cricket/love)} = 2 > 1 =p(cricket/love)p(cricket/play)=2>1我们可以得到与cricket最相关的词是play而不是love。如果ratio接近1,那么两个词都与cricket相关。
我们能够用简单的统计学方法来推导出单词之间的关系,这就是GloVe预训练词嵌入的想法。
GloVe学习将概率比的信息以词向量的形式进行编码,该模型的一般形式是:
F ( w i , w j , w k ~ ) = P i k P j k F(w_i, w_j, \tilde{w_k}) = \frac{P_{ik}}{P_{jk}} F(wi,wj,wk~)=PjkPik