swin transformer
vit模型要求处理图片的像素不能太大(vit论文中给定的图片为224*224),但是针对于更高像素的图片,vit还是无法处理,并且vit模型无法在物体检测等领域发挥较好效果。swin transfomer就很好的解决了这些问题。swin transfomer收到了CNN中卷积操作的启发,将图片划分成一个个小patch块,并且以patch块为基本单位,在一个个window 窗口内部进行注意力学习。patch merging则类似于CNN中的池化操作,更够增大感受野,对数据进行压缩。通过这些操作能够使swin transformer能好的提取图片的局部信息,从而实现多种不同的计算机视觉任务。
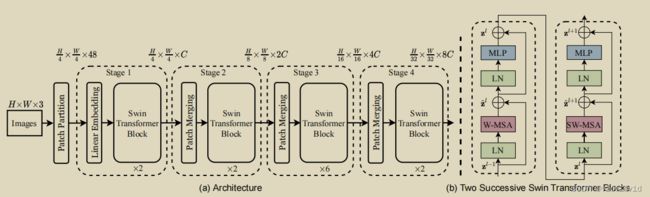
上图是swin transformer的架构。
(a)为整体架构。(H,W,3)的image首先经过patch partition变成(H/3,W/3,48),然后经过stage1,2,3,4最后得到输出。其中stage1和stage2,3,4结构稍微由区别。stage2,3,4中的patch merging就相当于池化操作。stage1中的Linear Embedding和前面的patch partition在源码中是用一次卷积操作完成的。
(b)为swin transformer block的内部结构,一个swin transformer block由2个连续的block组成。前一个block对以window为单位进行注意力计算,后一个block引入滑动窗口,通过滑动窗口和mask技巧,间接的在相邻的window窗口之间进行注意力计算。
数据处理流程:
根据上图(H,W,3)的image首先通过patch partition进行预处理,然后输入到stage中,但是源码中将patch partition和stage1中的linear embedding结合到了一起。
代码参考链接
class PatchEmbed(nn.Module):
# img_size 为图片大小
# patch_size 为分割成的patch的大小,swin transformer以patch为基本单元
# in_c 为输入土图片的维度 RGB图片的 in_c = 3
# embed_dim 为将patch 映射成vector的大小,类似于transformer中的 d_model 和 d_word_vec
# norm_layer 为规定的正则化方法
def __init__(self, patch_size=4, in_c=3, embed_dim=96, norm_layer=None):
super().__init__()
patch_size = (patch_size, patch_size)
self.patch_size = patch_size
self.in_chans = in_c
self.embed_dim = embed_dim
# self.proj 将图片映射成 self.num_pathes 个 维度为 embed_dim的向量组
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self,x):
# X的维度为(batchsize,channel,图片长度,图片宽度)
_,_,H,W = x.shape
# swin transformer对于H,W不是patch_size的整数倍
# 则将其padding成符合条件的img_size
pad_input = (H%self.patch_size[0]!=0) or (W%self.patch_size[1]!=0)
if pad_input :
# F.pad 根据X的维度倒序进行pad(后三维度),分别对X矩阵的left, (right),top,(bottom),front,back。
x = F.pad(x,(0,self.patch_size[1]-W%self.patch_size[1],0,
self.patch_size[0]-H%self.patch_size[0],0,0))
#利用卷积层进行下采样
# H,W 为patch在高度和宽度方向上的数量。
# H*W 为patch的数量
# (batchsize,channel,图片长度,图片宽度) -> self.proj -> (batchsize,embed_dim,H,W)
x = self.proj(x)
_,_,H,W = x.shape
# (batchsize, embed_dim, H, W) -> flatten -> ((batchsize,embed_dim,H*W))
# ((batchsize,embed_dim,H*W)) -> transpose -> ((batchsize,H*W,embed_dim))
x = x.flatten(2).transpose(1,2)
x = self.norm(x)
return x,H,W
预处理完之后,进入stage中,源码中将本个stage中的swin transformer block和下一个stage中的patch merging当成一个BasicLayer(stage4需要特殊判断)。
首先是swin transformer block的实现:
swin transformer block由两个block块组成,前一个block块将图片划分成若干window,在window内部进行atttention。后一个block块在引入shift操作,实现了window和window之间的通信。
# 实现W-MSA 和 MW-MAS
class WindowAttention(nn.Module):
# dim为 token的维度大小
# num_heads 为多头注意力机制中的head个数
# attn_drop_ratio 为 注意力机制中 ScaledDotProductAttention 中的Layer norm中的p
# proj_drop_ratio 为 concat之后是否经过 Layer norm
def __init__(self,
dim, # 输入token的dim
window_size,
num_heads,
qkv_bias=True,
attn_drop=0.,
proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size
self.num_heads = num_heads
head_dim = dim // num_heads
# 和 transformer中的 操作有区别。
# transformer中的多头注意力机制中的head_dim = dim,最后concat成的dim 为 n_head * dim
# vit 中的 head_dim = dim / n_head,最后concat成的dim 为 dim
self.scale = head_dim ** -0.5
# ------------------------------------------------------
# 生成相对位置偏移的表(不是很懂)
# relative_position_bias_table的大小为((2*Mh-1)*(2*Mw-1),num_heads)
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2*window_size[0]-1)*(2*window_size[1]-1),num_heads)
)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing="ij")) # [2, Mh, Mw]
coords_flatten = torch.flatten(coords, 1) # [2, Mh*Mw]
# [2, Mh*Mw, 1] - [2, 1, Mh*Mw]
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # [2, Mh*Mw, Mh*Mw]
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # [Mh*Mw, Mh*Mw, 2]
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # [Mh*Mw, Mh*Mw]
self.register_buffer("relative_position_index", relative_position_index)
# ------------------------------------------------------
self.qkv = nn.Linear(dim,dim*3,bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim,dim)
self.proj_drop = nn.Dropout(proj_drop)
#对相对位置偏移的表进行初始化
nn.init.trunc_normal_(self.relative_position_bias_table,std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self,x,mask:Optional[torch.Tensor]=None):
#(batch_size*窗口的个数,窗口的高度*窗口的宽度,dim)
# x (bacth_size*num_window,Mh*Mw,dim)
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q = qkv[0]
k = qkv[1]
v = qkv[2]
# q,k,v (bacth_size*num_window,n_head,Mh*Mw,每个head的dim=dim/n_head)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
# attn (bacth_size*num_window,n_head,Mh*Mw,Mh*Mw)
# 代表了window内部patch块之间的相似度
# 查表----------------------------
# relative_position_bias_table.view: [Mh*Mw*Mh*Mw,n_head] -> [Mh*Mw,Mh*Mw,n_head]
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # [n_head, Mh*Mw, Mh*Mw]
# 查表----------------------------
#relative_position_bias [n_head, Mh * Mw, Mh * Mw]
#attn [bacth_size*num_window,n_head,Mh*Mw,Mh*Mw]
# 在相似度矩阵上加上相对位置信息
attn = attn + relative_position_bias.unsqueeze(0)
# 如果是第一个block mask is None
# 如果是第二个block mask is not None
if mask is not None:
# 如果mask is not None: 那么输入的image就是经过shift的image,window内部即包括
# 在shift前相邻的patch,还包括shift前完全不相邻的patch,针对于这些patch,需要人为
#的添加mask保证这些不相邻的patch相似度尽可能小。
# mask [n_window,Mh*Mw,Mh*Mw]
nW = mask.shape[0]
# attn.view [bacth_size,num_window,n_head,Mh*Mw,Mh*Mw]
# mask.unsqueeze: [1, nW, 1, Mh*Mw, Mh*Mw]
attn = attn.view(B//nW,nW,self.num_heads,N,N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1,self.num_heads,N,N)
attn = self.softmax(attn)
else :
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
# x (bacth_size*num_window,Mh*Mw,dim)
return x
两个block的attention计算过后都跟一个mlp
class Mlp(nn.Module):
"""
MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
这样一个基本的swin transformer block就完成了
class SwinTransformerBlock(nn.Module):
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
# 将图片分成一个个不重叠的window,在window内进行注意力计算。
self.window_size = window_size
# shift_size 指滑动窗口的大小。(window向 下/右 移动多少个patch)
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size <self.window_size, "shift_size must in 0-window_size"
# 对于奇数block 采用SW-MSA 对于偶数block 采用 W-MSA
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(dim,
window_size=(self.window_size,self.window_size),
num_heads=num_heads,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path>0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim*mlp_ratio)
self.mlp = Mlp(in_features=dim,hidden_features=mlp_hidden_dim,act_layer=act_layer,
drop=drop)
def forward(self,x,attn_mask):
# attn_mask [n_window,Mh*Mw,Mh*Mw]
# x [batch_size,Mh*Mw,dim]
H,W = self.H,self.W
B,L,C = x.shape
assert L==H*W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B,H,W,C)
# 对x的右侧,下侧进行padding,使图片能够划分为大小相同的若干window块
pad_l = 0
pad_t = 0
pad_r = (self.window_size - W%self.window_size)%self.window_size
pad_b = (self.window_size - H%self.window_size)%self.window_size
x = F.pad(x,(0,0,pad_l,pad_r,pad_t,pad_b))
_,Hp,Wp,_ = x.shape
# 如果shift_size >0 (第二个block)就需要对x进行shift,shift规则为:
# 每一行都向上平移shift个patch,每一列都向左平移shift个patch
# SW-MSA
if self.shift_size >0 :
shifted_x = torch.roll(x,shifts=(-self.shift_size,-self.shift_size),
dims=(1,2))
# W - MSA
else :
shifted_x = x
attn_mask = None
# partition windows 该函数用来把shift之后的图像拆分。
#[batch_size,Mh,Mw,dim] - window_partition-> [num_window*batch_size, 窗口高度, 窗口宽度,dim]
x_windows = window_partition(shifted_x, self.window_size)
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # [num_Window*Batch_size, 窗口高度*窗口宽度, dim]
#attn_windows [num_Window*Batch_size, 窗口高度*窗口宽度, dim]
attn_windows = self.attn(x_windows, mask=attn_mask)
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [num_Window*Batch_size, 窗口高度,窗口宽度, dim]
# partition windows 的逆变换
#[num_Window*Batch_size, 窗口高度,窗口宽度, dim] -> [Batch_size, 图片高度,图片宽度, dim]
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp)
# 如果shift_size >0,将shift之后的图片变化转变过来
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0:
# 把前面pad的数据移除掉
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
# [Batch_size, 图片高度,图片宽度, dim]
return x
经过swin transformer block之后经过patch merging操作。patch merging 功能将图片的高度,宽度减半,通道数翻倍。起到增大感受野的作用
# patch mergering 实现图片高度宽度减半,通道特征数倍增的操作
class PatchMerging(nn.Module):
def __init__(self,dim,norm_layer = nn.LayerNorm):
super().__init__()
self.dim = dim
# 图片经过拆分后高度减半,宽度减半,dim相应变成4倍
# 所以需要将四倍的dim变成二倍的dim
self.reduction = nn.Linear(4*dim,2*dim,bias=False)
self.norm = norm_layer(4*dim)
def forward(self,x,H,W):
# 对高度和宽度进行下采样2倍
# x (batch_size,H*W,dim),
# 因为 L = H*W,所以如果要具体知道x的H,W需要额外传入参数H,W
B,L,C = x.shape
assert L == H*W,"input feature has wrong size"
x = x.view(B,H,W,C)
# 如果x的shape不支持下采样,需要进行padding操作
pad_input = (H%2 == 1) or (W%2 == 1)
if pad_input :
# F.pad(x) 对x的后三个维度进行padding,并且按照倒叙的方式进行padding
# 所以padding的顺序为 前后,左右,上下。
#在右侧和下方padding 0
x = F.pad(x, (0, 0,0,W%2,0,H%2))
# padding之后需要进行剪裁操作
x0 = x[:, 0::2, 0::2, :] #蓝色
x1 = x[:, 0::2, 1::2, :] # 橙黄色
x2 = x[:, 1::2, 0::2, :]#绿色
x3 = x[:, 1::2, 1::2, :]#红色
# 利用conat在最后一个维度上进行拼接
# 拼接完毕的x shape (batch_size,H/2,W/2,dim*4)
x = torch.cat([x0,x2,x1,x3],-1)
x = x.view(B,-1,C*4) # (batch_size,H*W/4,dim*4)
x = self.norm(x)
# self.reduction 将 dim*4 -> dim*2
x = self.reduction(x)
#最后完成patch_merge操作
# 图片的长宽减半,channel*2
# (batch_size,H*W/4,dim*2)
return x
将swin transformer block 和 patch merging结合起来就是BasicLayer,BasicLayer实现每一层stage的功能:每一层stage包括这一层的swin transformer block和下一层的patch merging
class BasicLayer(nn.Module):
def __init__(self,dim,depth,num_heads,window_size,mlp_ratio=4.,qkv_bias=True,
drop=0.,attn_drop=0.,drop_path=0.,norm_layer=nn.LayerNorm,
downsample=None,use_checkpoint=False):
super().__init__()
#depth 代表这个stage中有多少个block块(总为偶数)
# shift_size 代表将窗口向下,向右移动多少个patch
self.shift_size = window_size // 2
self.dim = dim
self.depth = depth
self.window_size = window_size
self.use_checkpoint = use_checkpoint
# 初始化swin transformer block,每一个stage中有depth个swin transformer block
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i%2==0) else self.shift_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path,list) else drop_path,
norm_layer=norm_layer
) for i in range(depth)
])
# 代表是否进行patch merging
if downsample is not None:
self.downsample = downsample(dim=dim,norm_layer=norm_layer)
else :
self.downsample = None
# 计算SW-MSA的 mask
def create_mask(self, x, H, W):
# 保证Hp和Wp是window_size的整数倍 Hp和Wp代表该行或该列的patch block个数
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
# 拥有和feature map一样的通道排列顺序,方便后续window_partition
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # [1, Hp, Wp, 1]
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
#对 shift 的区域块进行编号,原图片中相邻的区域用相同的编号表示
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
# 通过window_partition将img_mask划分成一个个窗口
mask_windows = window_partition(img_mask, self.window_size) # (窗口个数,窗口高度,窗口宽度,1)
mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # [窗口个数,窗口高度*窗口宽度]
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # [窗口个数, 1, 窗口高度*窗口宽度] - [窗口个数, 窗口高度*窗口宽度, 1]
# [窗口个数,窗口高度*窗口宽度,窗口高度*窗口宽度]
# attn_mask 等于0的地方填入0, 不等于0的地方填入-100
# 0 表示和当前patch同区域的patch
# -100表示和当前patch不在同一区域
# attn_mask 表示针对于某一个windown内的patch,有多少是跟他在原图中的同一个位置的(这里是相对于shift完的图像)
# cnt标记相同说明原来在一个图像里,cnt标记不同说明原来不在一个图像里。
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x, H, W):
# attn_mask [窗口数量, 窗口长度*窗口宽度, 窗口长度*窗口宽度]
attn_mask = self.create_mask(x, H, W)
for blk in self.blocks:
blk.H, blk.W = H, W
if not torch.jit.is_scripting() and self.use_checkpoint:
x = checkpoint.checkpoint(blk, x, attn_mask)
else:
x = blk(x, attn_mask)
if self.downsample is not None:
# 实现patch merge
x = self.downsample(x, H, W)
H, W = (H + 1) // 2, (W + 1) // 2
# 图片的长度和宽度减半,通道数翻倍
return x, H, W
最后全部都整合起来就得到swin transformer
class SwinTransformer(nn.Module):
# swin transformer 中的window_size 保持不变,注意力机制以window_size 为单位对window_size中的patch块
# 进行运算,swin transformer以patch块为运算的基本单位
def __init__(self,patch_size=4,in_chans=3,num_classes=1000,
embed_dim=96,depths=(2,2,6,2),num_heads=(3,6,12,24),
window_size=7,mlp_ratio=4.,qkv_bias=True,
drop_ratio=0.,attn_drop_ratio=0.,drop_path_ratio=0.1,
norm_layer=nn.LayerNorm,patch_norm=True,
use_checkpoint=False,**kwargs):
super().__init__()
# num_classes 代表分类数
self.num_classes = num_classes
# num_layers 代表stage个数
self.num_layers = len(depths)
# 代表输入到第一个stage中的特征矩阵的channel
self.embed_dim = embed_dim
self.patch_norm = patch_norm
# 代表stage4所输出的特征矩阵的channel
# stage4输出特征矩阵的channel为8*embed_dim,每经过一个patch merging embed都会翻倍,总共有3个patch merging
self.num_features = int(embed_dim*(2 **(self.num_layers - 1)))
self.mlp_ratio = mlp_ratio
# patch_embed 代表将图片划分成若干个没有重叠的patch,以便输入到swin transformer block中
# patch_embed 代表 Patch Partition 和 Linear Embedding
# 使图片输入到第一个stage中做图片预处理,与vit中patch embedding 类似
self.patch_embed = PatchEmbed(
patch_size=patch_size,in_c=in_chans,embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None
)
self.pos_drop = nn.Dropout(p=drop_ratio)
# 和vision transformer一样,每一层的drop_path_rate 都不一样
# 针对于每一个block ,执行不同程度的drop_path,越后面的层drop程度越大
# 每一个stage有偶数个block
dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, sum(depths))] # stochastic depth decay rule
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
# 代表第i_layer+1个stage
# 这里的一个block layer块代表当前swin transformer block和下一个stage的
# patch merging,这就意味着最后一个stage 4 没有 patch merging操作
# dim 每经过一个layer都会*2
layer = BasicLayer(dim=int(embed_dim * (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_ratio,
attn_drop=attn_drop_ratio,
# 每一个stage里的每一个swin transformer block都有不同的drop_path_ratio
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
# 最后数据经过四个stage会经过一个norm_layer层
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features,num_classes) if num_classes >0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self,x):
# x 的维度为(batchsize,channel,图片长度,图片宽度)
x,H,W = self.patch_embed(x)
# H,W 分别代表在高度和宽度方面有多少个patch块
# x 的维度为(batchsize,H*W,dim)
x = self.pos_drop(x)
# 每经过一个latyer(除了第四个layer),其W,H减半
# dim 增加
for layer in self.layers:
# 依次将图片通过stage1 2 3 4
x,H,W = layer(x,H,W)
x = self.norm(x)
# x 的维度为(batchsize,H/8*W/8,dim*8)-> avgpool&&transpose -> (batchsize,dim*8,1)
x = self.avgpool(x.transpose(1,2))
x = torch.flatten(x,1)
# (batchsize, dim * 8, 1) -> flatten -> (batchsize, dim * 8)
# (batchsize, dim * 8) -> head -> (batchsize, num_classes)
x = self.head(x)
return x
patch merging讲解
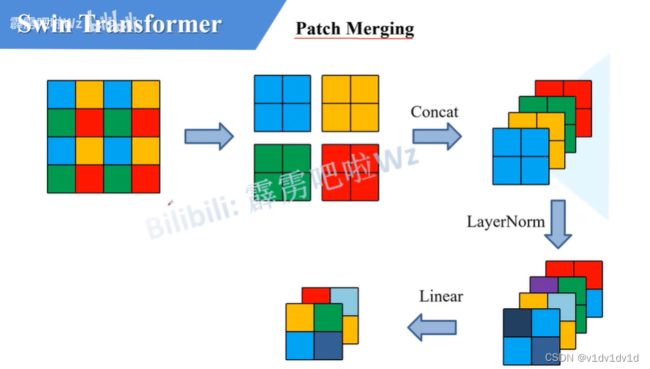
每一个stage(除了stage1)之后跟上patch merging进行下采样,如果输是一个(1,4,4)的特征图,patch merging会根据颜色把特征图分解成四个小的特征图,然后经过concat拼接最后得到了(4,2,2)的特征图,最后通过一个线性linear层,将通道数减半。所以通过patch merging层之后特征图的高,宽减半,深度翻倍。
基于窗口的注意力机制

vit模型中使用的是多头注意力机制,即为一种全局注意力机制。swin transformer中使用的是基于滑动窗口的注意力机制,现了局部注意力,同时使用滑动窗口思想,让不同窗口之间的信息得以交互,从而达到全局注意力建模。同时将以窗口为单位进行计算也大大减少了计算量。
一个swin transformer block中会连续实现2中注意力计算,第一次是正常的窗口自注意力,第二次是移动窗口自注意力,两次是绑定的,这也是在四个阶段swin transformer都为偶数的原因。
主要讲一下基于滑动窗口的注意力机制是如何实现的。

窗口会根据自身尺寸除以2向下取整来决定移动多少个patch 块,于是乎就有了

论文中的图例解释就是这么来的

可以明显看出经过shift之后窗口的大小变得不一样了,我们可以在小窗口外围pad上零,但变成了九个窗口,计算复杂度提升,论文中使用了循环移位的方法。经过循环以为之后还是四个窗口,但是进行移位之后相邻的两个元素也不一定可以用自注意力了。所以使用mask的操作,这样一个窗口不同区域使用一次前向就能把自注意力算出来 ,算完注意力之后,需要将循环位移还原。

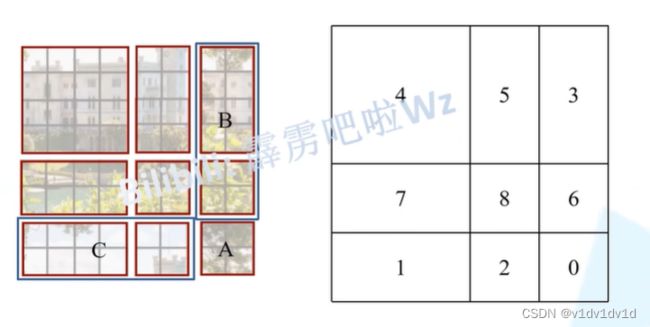
这样的化我们就解决了窗口大小不一致的问题,但是我们可以知道图中 0,2,6,8这4个部分在一个窗口中,但是这些部分在原图中其实并不相邻,所以在计算注意力矩阵的时候这些部分彼此之间的注意力权重应该比较小。所以我们需要加入mask矩阵来实现这一功能。以图中的5,3部分举例说明mask形成过程。

5,3代表索引,窗口长为2,其中元素索引组成的序列为55335533,那么做自注意力点乘就如上图所示。其中(5,5),(3.3)部分是我们要留下的,其代表在原图中相邻的位置。其它部分是不要的,需要mask掉,具体做法是加上一个mask矩阵,其中(5,5),(3.3)部分设为0,其它部分都设成-100。这样在原图中不相邻的patch块之间的关联性进行softmax时候就几乎为0了。