【论文阅读笔记】(2022 ECCV)Contrastive Positive Mining for Unsupervised 3D Action Representation Learning
论文题目:Contrastive Positive Mining for Unsupervised 3D Action Representation Learning
论文下载地址:https://arxiv.org/pdf/2208.03497.pdf
目录
0. 论文简介 & 创新点
1、Contrastive Positive Mining (CPM)
2、Similarity Distribution
3、Positive Mining
4、Positive-enhanced Learning
5、Learning of CPM
0. 论文简介 & 创新点
简介:
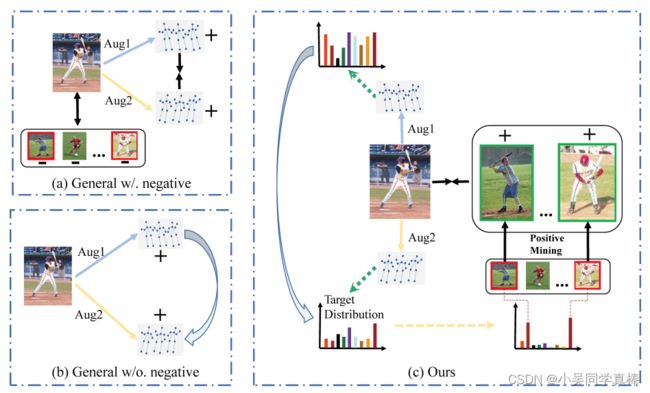
论文在骨架点序列上做了一个自监督对比学习任务:首先先像 simclr 任务一样对一段骨架点序列分别做两次数据增强,分别送入两个分支,分别得到两个增强样本的特征。比起直接拉近两个增强样本之间特征的距离,这篇论文拉近的是:这两个增强样本与队列中的 N 个样本相似程度的分布。同时,除了两个增强样本互为各自的正样本,在训练的第二阶段里,模型还会使用 Positive Mining 策略将队列中的某些样本也作为这两个增强样本的正样本,进行 positive-enhanced 的对比学习。
创新点:
1、提出了一个针对股价点特征表达的自监督学习框架:Contrastive Positive Mining (CPM)。
2、用了一个非常简单但也非常有效的挖掘策略去确定 contextual queue 中的 “非自身增强得到” 的正样本。
3、有了创新点 2之后,对比学习的正样本就变多了,所以 就变成了 positive-enhanced 学习策略。
1、Contrastive Positive Mining (CPM)
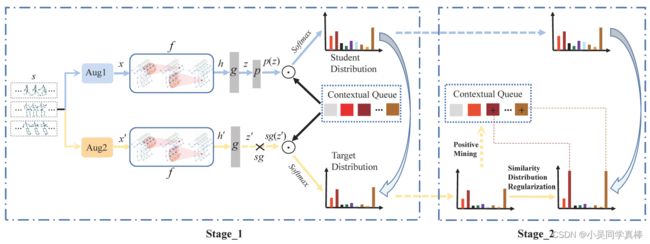
CPM 框架是由两个分支构成的,一个是 student,一个是 target。
一段骨架点序列经过两次数据增强之后,一个送入 student 分支,一个送入 target 分支。
数据增强操作包括有:
- shear:给原来的骨架点序列数据乘上一个线性变换的矩阵,相当于将原来的骨架点序列随机变换一个角度。
- crop:从 T 帧骨架点序列中随机截取连续的 t 帧(t < T)
两个分支的 encoder 为共享参数的 ST-GCN encoder。
得到特征 h=f(x) 和 h'=f(x') 之后,再分别送入一个 MLP g(·),得到 z=g(h) 和 z'=g(h')。
最后在 student 分支后面再接上一个和 g(·) 同样结构的 MLP p(·),得到 p(z);而 target 分支后面接上的是 stop-gradient 的操作,也就是说,target 分支不更新参数。
除此之外,还会维护一个包含之前送入网络的、由 N 个样本的 embedding【z = g(h)】所组成的 contextual queue(先进先出)。
student 分支的训练目标就是:让 “送入 student 分支的增强样本与 contextual queue 中所有样本之间的距离分布” 和 ““送入 target 分支的增强样本与 contextual queue 中所有样本之间的距离分布” 匹配上,也就是说希望这两个分布尽可能相似,也就是对比学习拉近的是这两个分布的距离。

2、Similarity Distribution
假设 contextual queue 中有 10000 个样本的 embeddings。
那么,送入 student 分支的增强样本 1 得到的 p(z) 和 contextual queue 里的所有样本进行点积,得到 10000 个值,再对这 10000 个值做一个 softmax,就可以得到这个样本和 contextual queue 中所有样本的相似度分布。
同样,送入 target 分支的增强样本 2 得到的 z' 和 contextual queue 里的所有样本进行点积,得到 10000 个值,再对这 10000 个值做一个 softmax,也可以得到这个样本和 contextual queue 中所有样本的相似度分布。
原论文计算公式如下:

其中变量上方带横线的意思是:对这个变量进行 l2-normalized.
D 和 D' 就是这两个增强样本分别和 contextual queue 的相似度分布,维度为 10000.
最后,既然是拉近两个相似度分布的距离,loss 就用的是 KL 散度:
![]()
个人觉得这个创新点是这篇论文里最巧妙的一点:比起直接拉近两个增强样本之间特征的距离,这篇论文拉近的是:这两个增强样本与队列中的 N 个样本相似程度的分布。
增强样本与队列中的哪些样本相似,与队列中的哪些样本不相似,具体相对于队列中的其他样本有多相似都会体现在这个相似度分布里。
3、Positive Mining
针对某个增强样本的 embedding z,队列里所有 embeddings 和它最为相似的 k 个样本可以作为这个增强样本的正样本。

4、Positive-enhanced Learning
增强样本 xi 通过 Positive Mining 得到更多正样本之后,对原来的相似度分布 D 进行修正,直接把相似度分布 D 里正样本对应的值置为 1(原来相似度分布的每个值都在 0~1 范围内,所有值求和之后才等于 1)。
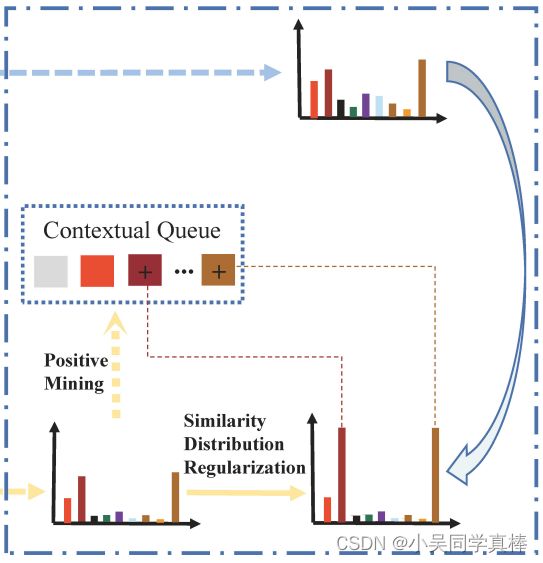
再用 KL 散度去拉近两个增强样本修正过后的相似度分布 D'_NP。

5、Learning of CPM
作者提到在早期的训练时,网络还不太稳定,所以一开始先不进行 positve mining,用公式 (4) 进行训练。
训练了一段时间之后,再开始进行 positve mining,用公式 (7) 和 (8) 进行训练。