超大模型工程化实践打磨,百度智能云发布云原生AI 2.0方案
近日,百度智能云发布云原生AI 2.0方案,方案将百度自身超大模型训练(文心等)经验,资源管理和资源利用率优化经验,多场景工程实践经验充分吸收融合,用标准化的能力帮助企业应对缺乏大模型训练经验而导致的资源利用率低等问题,加速AI应用落地。该方案在资源弹性、跨节点架构感知、训练推理效率等方面做了重点升级。

助力超大模型预训练落地

针对大模型复杂网络、稠密参数的特点,云原生2.0方案支持了PaddlePaddle和Pytorch+DeepSpeed两种框架:
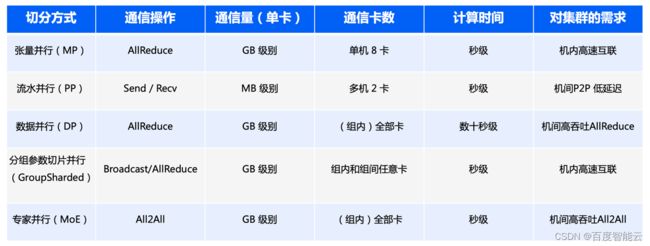
- 百度智能云自研的PaddlePaddle框架,早在2021年4月份就推出业内首创的4D混合并行策略:数据并行、张量模型并行、分组参数切片并行、流水线并行。针对性能优化和显存优化,几种并行策略都有用武之地,但也有各自的局限性,这几种策略相互组合,取长补短,能够在训练大模型时发挥各自的优势。
- Pytorch 原生混合并行能力欠缺,针对大模型场景混合并行场景,微软推出的 deepspeed 开源库,做 Pytorch 框架的大模型训练的补充。

此外,业界还在GPT-3基础上提出混合专家模型(Mixture Of Expert, MoE),使得计算量不增加的情况下,参数量可以扩大到万亿,我们将上述相关模式进行仔细分析后得出如下结论(以1000亿参数模型为例):
很多企业因为缺乏上文提及的大规模集群实践经验而无法顺利完成超大模型的预训练,百度拥有8年多的万卡规模EFlops算力最佳实践的能力和积累,等效算力高达50%以上,数千卡并发训练线性加速比90%,整体大模型预训练的集群利用率高达95%。在2022年6月30日最新发布的 MLPerf Training v2.0 榜单里,百度使用飞桨( PaddlePaddle )框架和百度智能云百舸计算平台提交了 BERT Large 模型的 GPU 性能结果,在同等机器条件下性能排名世界第一,向全世界展现了百度智能云的性能领先性。借助这些经验积累,百度智能云的云原生AI2.0方案针对超大模型的预训练提供了以下特色能力:
- 网络:全IB网络,盒式组网最大规模,单机转发延迟200ns,千卡通信近线性扩展。
- 通信库:自研的异构集合通信库ECCL。将硬件拓扑感知的能力封装到ECCL通信库中,并作为集群标准的基础接口提供给上层的调度器和训练框架,从而联动配合地使能最高训练效率。
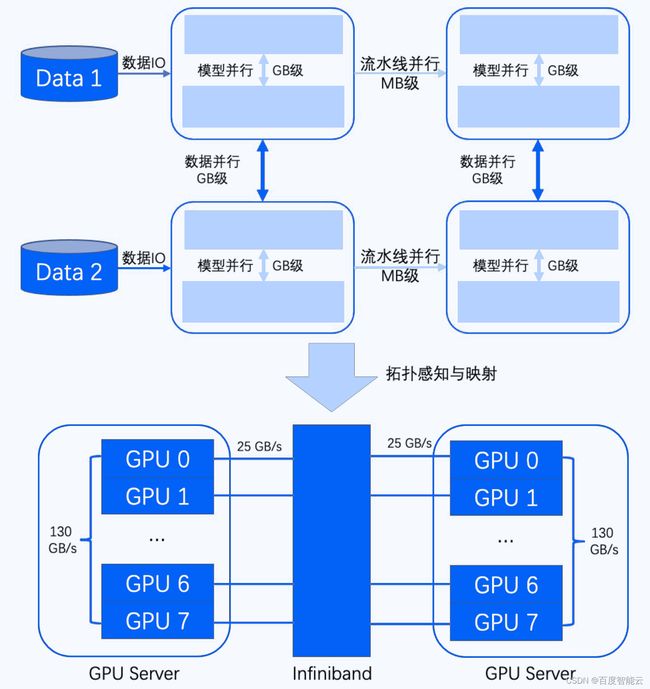
- 调度:跨节点架构感知高性能调度,支持通过慢节点感知发现分布式训练节点的性能瓶颈。在千卡规模的弹性训练的场景下,调度结合框架,能够提供容错功能,保证大规模训练的稳定性。
- 可观测:自研面向模型并行的多机调优profile工具,能够发现任务/数据分配不均等问题,经过优化的最终端到端吞吐可提升1倍以上。
实际上,不仅仅是超大模型预训练实际场景沉淀出的特色能力,云原生AI2.0还对资源弹性、训练推理效率、易用性等通用能力做了全面升级。
提升资源弹性
GPU、NPU作为主要的AI算力资源,品牌型号多样且价格昂贵,如何让这些算力资源充分发挥作用、提高资源利用效率,是资源管理层面的问题。以往,借助以容器为代表的云原生技术通过一定的技术升级和改造之后就可以将GPU等AI算力作资源虚拟化以及资源池化,可以将AI应用和GPU服务器硬件解耦,实现虚拟GPU 资源的动态伸缩和灵活调度。百度智能云对以上关键技术升级,实现了如下能力:
1、虚拟化:提供了用户态和内核态两种实现,用户态能够实现进程融合、显存交换、编解码实例等,性能更好;内核态隔离性强,可以实现算力隔离以及显存隔离,用户可以根据自己的需求灵活选择。用户态方案:通过拦截Driver API进行资源隔离或限制操作,实现显存隔离、算力隔离基础隔离功能及显存超发、高优抢占等高级功能。

- 内核态方案:内核态方案主要由拦截接口跟拦截驱动两部分。
用户应用还是通过原来的设备接口(/dev/nvidiactl ,/dev/nvidia0 )来跟GPU 设备交互,拦截驱动通过拦截接口用将户应用跟GPU的通信进行解析并拦截。

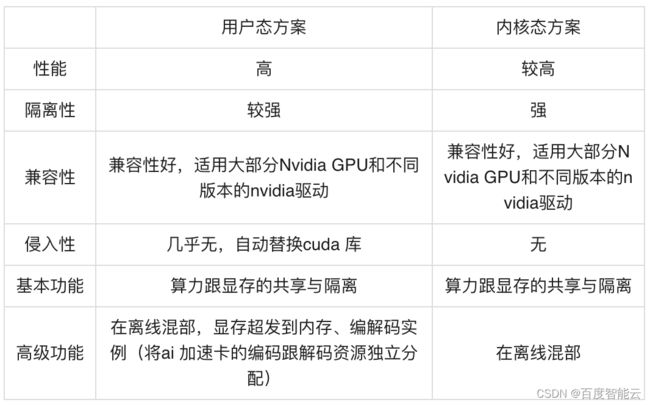
- 单内核态GPU容器 VS 单GPU直通性能比较
下图分别使用内核态容器与标准的容器跑任务测试( 测试环境与模型:resnet50,batchsize=32,在v100-32GB ),可以看出内核态GPU容器几乎没有性能损失。

同时,从下图的数据结果可以看到用户态方案性能比内核性能高8%-10%;而内核方案隔离性更强,几乎没有性能损失。
单位:平均吞吐(Img/sec)

2、调度层面:支持共享混部,拓扑感知以及亲和调度。
3、资源层面:池化架构,资源被统一动态管理,避免资源浪费,实时调度减少资源碎片。
4、国产化层面:支持昆仑芯等国产芯的虚拟化和调度,
实践中,上述能力给业务带来了真金白银的实际收益。比如,百度商业广告模型业务从之前单实例独占GPU卡的使用方式转变为在离线业务混部的方式,优化后的商业在线业务GPU 共享部署的占比90%+,整体GPU利用率从13%提升到50%,在线业务 Latency P97 性能不变 。
提升训练、推理效率
为了更好地加速训练和推理任务,在训练场景下如何实现分布式训练的加速以及数据的加速?AI镜像会有复杂的CUDA依赖,甚至会有一些驱动,镜像本身比较大,严重影响启动的速度,如何针对性进行优化?为此,云原生AI2.0方案推出了AI 加速套件 AI Accelerate Kit(简称 AIAK,本文将使用简称),该套件基于百度智能云IaaS 资源推出的AI 加速能力,用来加速 Pytorch、TensorFlow等深度学习框架的AI 应用,能极大提升分布式训练和推理的性能。

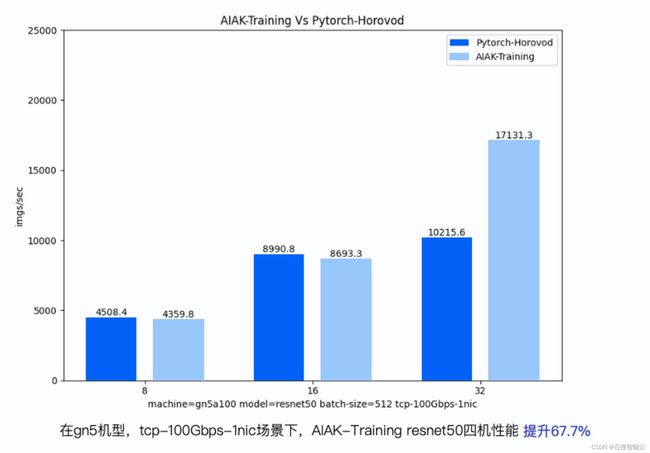
分布式训练加速:AIAK-Training 是基于 Horovod 深度定制优化的分布式训练框架(Horovod是TensorFlow、Pytorch等的分布式深度学习训练框架),在保留 Horovod 已有功能特性的基础上,增加了新的通信优化特性,完全兼容 Horovod 原有API,经典模型的训练效率提升50%以上。


推理加速:AIAK-Inference通过图优化、算子融合和自研高性能算子库来提升推理效率,ResNet、Bert等经典模型时延降低40%~63%。

IO加速:通过并行文件系统和分布式缓存技术,与对象存储数据双向流动,实现数据集的管理和读写加速。PFS提供完全托管、简单可扩展的并行文件存储服务,针对高性能计算场景提供亚毫秒级的访问能力、高IOPS及高吞吐的数据读写请求能力;RapidFS是由百度智能云推出的高可靠、高可用、弹性的数据加速服务,以对象存储作为数据湖存储底座,为计算应用提供统一的数据入口、命名空间及访问协议,加速海量数据分析、机器学习、AI训练等业务访问存储的性能,方便用户在不同的存储系统管理和流转数据。
在 4v100-32g 机型 ImageNet 1K 训练中,PFS + BOS 和 RapidFS + BOS 效果和本地 SSD 持平,比直接基于 BOS 训练提升 5 倍以上。

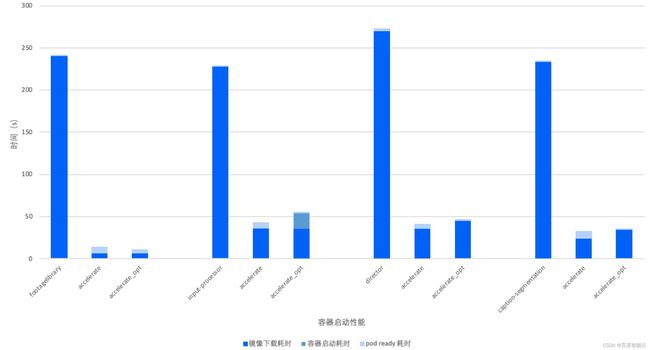
镜像加速:通过容器镜像按需加载技术,缩短镜像下载时间,实现容器冷启动加速。百度智能云容器镜像服务CCR提供的镜像加速功能,可在用户推送镜像时自动生成符合OCI镜像规范的加速格式的镜像。加速版本的镜像为镜像层中的每个文件和数据块建立索引,配合镜像仓库的HTTP Range Request的特性,使单机侧支持按需下载部分镜像层的文件。CCE 提供的镜像加速组件可一键为kubernetes集群开启/关闭镜像加速能力,并在容器调度前自动为容器“换装”加速镜像。
在基于内容生成视频的业务场景中,镜像按需加载将容器冷启动速度提升6-20倍。
加速AI作业开发,降低人力成本
- AI任务可视化:针对工作流做可视化的封装,内置Pytorch Operator、Tensorflow Operator、Paddle Operator等主流的深度学习框架支持分布式作业以云原生的方式提交,用户只要关心自己的镜像是哪一个,数据集是哪一个,点选填的方式就可以提交一个分布式训练的作业。用户也可以通过前端渲染的界面,查看运行的历史,以及每个DAG的结构展示。同时,用户通过表单的方式更改DAG节点的输入、输出就可以提交一个新的工作流,操作简单,降低学习门槛。
- 工作流编排:实际的AI训练过程包含数据处理、模型训练、模型评估、模型部署和发布等一系列过程,每个AI算法工作者针对每个步骤都会用自己的方式去临时管理,这样会导致代码和模型管理混乱,难以追踪和复现结果,也无法进行高效分享和代码复用。为了解决这些问题,云原生AI2.0方案集成了KubeFlow和PaddleFlow来做AI作业编排,KubeFlow作为社区的开源项目,这里不再赘述。其中,PaddleFlow定位为AI训练的最小资源内核,提供以ML/DL作业的编排为核心的工作流调度等能力,模板化作业的数据处理、训练以及部署过程,并提供Cache、Artifact管理能力使得实验过程可复用可重现。同时,对用户屏蔽多样的计算和存储类型,透明化资源管理与调度细节。

作为国内人工智能的「头雁」,百度正通过自身的经验和技术输出来不断降低 AI 技术开发和应用的门槛。百度智能云将持续以新技术为立足点,以用户需求为落脚点,加快云原生AI系列方案的迭代开发,助力企业AI应用落地,实现降本增效。