【Ensemble Learning】第 3 章:混合模型
在第2章中,您学习了如何以不同方式划分和混合训练数据以构建集成模型,其性能优于在未划分数据集上训练的模型。
在本章中,您将学习不同的组装方法。与混合训练数据方法不同,混合模型方法在不同的机器学习模型中使用相同的数据集,然后以不同的方式组合结果以获得性能更好的模型。
首先,让我们看看本章的目标。
介绍和解释基于集成的混合模型
引入投票合奏
通过代码示例介绍和解释软硬投票合奏
了解超参数调优集成
检查使用随机森林调整超参数的示例实现
了解横向投票合奏
使用 scikit-learn 和 Keras 检查 CIFAR 数据集上水平投票集成的示例实现
介绍与循环学习率一起使用的快照集成技术
在本章中,您不依赖于单一模型,而是一起训练各种机器学习模型的数据集(见图3-1),然后使用不同的技术组合这些模型的结果。首先,您将学习如何以投票和平均的形式组合不同训练模型的输出。接下来,您将了解超参数调优集成,您将在其中学习如何使用通过不同超参数设置训练的相同模型,然后组合结果以获得更好的模型。最后,您将了解相对鲜为人知的水平投票集成 和快照集成技术 ,它们正因其潜力在机器学习社区中站稳脚跟。

图 3-1 组合/混合不同的模型
投票合奏
硬投票
让我们先来看看最流行的集成学习技术 之一:投票集成。投票合奏训练不同的机器学习模型。再看一下图3-1,其中相同的数据在三种不同的机器学习模型上进行训练——逻辑回归、支持向量机 (SVM)和随机森林. 这三个模型的输出被组合起来得到一个整体预测。任何从业者的第一个问题是如何实际组合这些模型的结果。最简单的答案之一是从一种最古老的久经考验的技术中汲取灵感:投票。正如投票选举我们的领导人一样,不同人群的多数票选出官员,我们使用不同的机器学习模型进行选举。如果是分类问题,每个 ML 模型都会投票给一个特定的类别。在多数表决中,获得最多选票的班级是首选班级。人们广泛观察到,结果类通常比任何单一模型具有更高的准确性。
清单3-1中的数据集使用三种机器学习模型进行训练:k 最近邻 (KNN)、随机森林和使用 scikit-learn Python 库的逻辑回归。然后使用在 scikit-learn 库中实现的投票分类器组合它们的输出。如果您测量每个单独模型的结果准确性,以及测试数据集上的组合模型,您将获得非常好的准确性提升。我们鼓励您将代码作为练习运行,并检查各个模型和组合模型的准确性。
您可以为此使用的一个主要辅助函数是 scikit-learn 库的 sklearn.ensemble 包中的投票分类器类。
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_breast_cancer
import numpy as np
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=123)
### k-最近邻(k-NN)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
params_knn = {'n_neighbors': np.arange(1, 25)}
knn_gs = GridSearchCV(knn, params_knn, cv=5)
knn_gs.fit(X_train, y_train)
knn_best = knn_gs.best_estimator_
### 随机森林分类器
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=0)
params_rf = {'n_estimators': [50, 100, 200]}
rf_gs = GridSearchCV(rf, params_rf, cv=5)
rf_gs.fit(X_train, y_train)
rf_best = rf_gs.best_estimator_
### 逻辑回归
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression(random_state=123, solver="liblinear", penalty="l2", max_iter=5000)
C = np.logspace(1, 4, 10)
params_lr = dict(C=C)
lr_gs = GridSearchCV(log_reg, params_lr, cv=5, verbose=0)
lr_gs.fit(X_train, y_train)
lr_best = lr_gs.best_estimator_
# 结合所有三个投票合奏
from sklearn.ensemble import VotingClassifier
estimators=[('knn', knn_best), ('rf', rf_best), ('log_reg', lr_best)]
ensemble = VotingClassifier(estimators, voting="soft")
ensemble.fit(X_train, y_train)
print("knn_gs.score: ", knn_best.score(X_test, y_test))
# Output: knn_gs.score: 0.9239766081871345
print("rf_gs.score: ", rf_best.score(X_test, y_test))
# Output: rf_gs.score: 0.9766081871345029
print("log_reg.score: ", lr_best.score(X_test, y_test))
# Output: log_reg.score: 0.9590643274853801
print("ensemble.score: ", ensemble.score(X_test, y_test))
# Output: ensemble.score: 0.9649122807017544清单 3-1 最大投票合奏
平均/软投票
平均 是另一种组合不同分类器输出的方法。投票和平均之间的主要区别在于,在平均中,我们将每个类别的预测概率与模型分开,然后通过取这些预测的平均值来组合结果概率。这种组合方式称为软投票 。
在清单3-2中,训练不同模型的初始步骤是相同的,但我们没有使用投票分类器,而是在我们的测试数据集上对我们的模型进行推理,取出每个类别的预测概率,然后取出所有概率的平均值作为测试数据集上的结果类别概率。
请注意,我们在计算平均输出时为所有模型分配了相同的权重。但是,如果我们认为某个特定模型比其他模型更重要,我们可以增加该特定模型的权重并降低所有其他模型的权重。这种方法称为加权平均。
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_breast_cancer
import numpy as np
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=0)
### k-Nearest Neighbors (k-NN)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
params_knn = {'n_neighbors': np.arange(1, 25)}
knn_gs = GridSearchCV(knn, params_knn, cv=5)
knn_gs.fit(X_train, y_train)
knn_best = knn_gs.best_estimator_
knn_gs_predictions = knn_gs.predict(X_test)
### Random Forest Classifier
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=0)
params_rf = {'n_estimators': [50, 100, 200]}
rf_gs = GridSearchCV(rf, params_rf, cv=5)
rf_gs.fit(X_train, y_train)
rf_best = rf_gs.best_estimator_
rf_gs_predictions = rf_gs.predict(X_test)
### Logistic Regression
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression(random_state=123, solver="liblinear", penalty="l2", max_iter=5000)
C = np.logspace(1, 4, 10)
params_lr = dict(C=C)
lr_gs = GridSearchCV(log_reg, params_lr, cv=5, verbose=0)
lr_gs.fit(X_train, y_train)
lr_best = lr_gs.best_estimator_
log_reg_predictions = lr_gs.predict(X_test)
# 通过对 Ensembles 结果进行平均来组合所有三个
average_prediction = (log_reg_predictions + knn_gs_predictions + rf_gs_predictions)/3.0
# 或者通过使用 VotingClassifier 和 voting="soft" 参数组合所有
# 结合所有三个投票合奏
from sklearn.ensemble import VotingClassifier
estimators=[('knn', knn_best), ('rf', rf_best), ('log_reg', lr_best)]
ensemble = VotingClassifier(estimators, voting="soft")
ensemble.fit(X_train, y_train)
print("knn_gs.score: ", knn_gs.score(X_test, y_test))
# Output: knn_gs.score: 0.9239766081871345
print("rf_gs.score: ", rf_gs.score(X_test, y_test))
# Output: rf_gs.score: 0.9532163742690059
print("log_reg.score: ", lr_gs.score(X_test, y_test))
# Output: log_reg.score: 0.9415204678362573
print("ensemble.score: ", ensemble.score(X_test, y_test))
# Output: ensemble.score: 0.9473684210526315清单 3-2 平均
除了手动计算预测概率之外,如果您想要使用平均的直接结果,您可以再次使用 sklearn.ensemble 包中的VotingClassifier 类。但不是传递voting='hard'参数,而是使用voting='soft'参数。
超参数调优集合
到目前为止,您已经看到了两个训练 不同机器学习模型并组合其输出的示例。超参数调整集成是获得集成输出的另一种方法。您无需依赖不同的模型来制作集成模型,而是使用良好的机器学习模型并使用不同的超参数设置来训练该模型。
图3-2使用相同的机器学习模型——随机森林,但使用不同的超参数设置实例化了该模型的三个实例。在随机森林算法中,最重要的超参数之一是树的数量,在 scikit-learn API 中称为n_estimators 。使用不同数量的树(分别为 10、50 和 100)训练三种不同的随机森林。类似地,训练该模型所依据的训练数据周期数或纪元数对于三个实例中的每一个也不同。 然后使用先前的技术(例如,投票或平均)组合这些实例的输出以获得集成输出。
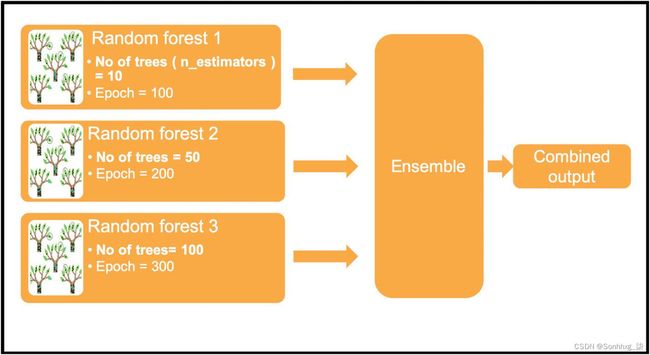
图 3-2 超参数调优集合
清单3-3使用三个不同的参数(即树的数量或 m_estimators)训练随机森林,以使用投票获得组合结果。
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_breast_cancer
import numpy as np
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=0)
### 随机森林分类器
from sklearn.ensemble import RandomForestClassifier
rf_1 = RandomForestClassifier(random_state=0, n_estimators=10)
rf_1.fit(X_train, y_train)
rf_2 = RandomForestClassifier(random_state=0, n_estimators=50)
rf_2.fit(X_train, y_train)
rf_3 = RandomForestClassifier(random_state=0, n_estimators=100)
rf_3.fit(X_train, y_train)
# 结合所有三个投票合奏
from sklearn.ensemble import VotingClassifier
estimators = [('rf_1', rf_1), ('rf_2', rf_2), ('rf_3', rf_3)]
ensemble = VotingClassifier(estimators, voting="hard")
ensemble.fit(X_train, y_train)
print("rf_1.score: ", rf_1.score(X_test, y_test))
# Output: rf_1.score: 0.935672514619883
print("rf_2.score: ", rf_2.score(X_test, y_test))
# Output: rf_1.score: 0.9473684210526315
print("rf_3.score: ", rf_3.score(X_test, y_test))
# Output: rf_3.score: 0.9532163742690059
print("ensemble.score: ", ensemble.score(X_test, y_test))
# Output: ensemble.score: 0.9415204678362573清单 3-3 超参数调优集合
横向投票合奏
前面混合模型 的例子——投票、平均和超参数调整——在经典机器学习中非常有效。但是有时我们会遇到这样的情况(尤其是在深度学习中),我们的训练数据大小、训练数据时间和模型大小都非常大。可能存在训练需要太多计算和时间的情况。在这些情况下,实际上不可能在短时间内训练多个模型集合。例如,如果在数据集上训练,深度学习模型可能需要两三天才能在功能强大的 GPU 机器上收敛像 ImageNet。在这种情况下,使用不同的超参数训练多个模型和同一模型的多个实例通常是不切实际或成本过高的。因此,您可以尝试的技术之一是横向投票。
每当你运行一个长时间的机器学习工作时,你可能会遇到这样的困境:经过一定数量的训练 epoch 后,模型精度是否停止提高。在这种情况下,很难为模型选择准确的纪元时间。在水平投票集成中(参见图3-3),您可以在最少数量的 epoch 后保存模型(此处 epoch = 300)。使用投票技术重新组合生成的模型以获得准确性提升。

图 3-3
水平投票合奏
看看清单3-4,我们在其中使用 keras、tensorflow 和 scikit 学习库实现了水平投票集成。
#!pip install q keras==2.3.1 tensorflow==1.15.2
import keras
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.models import load_model
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
import os
import numpy
from numpy import array
from numpy import argmax
from numpy import mean
from numpy import std
from sklearn.metrics import accuracy_score
from keras.utils import to_categorical
def make_dir(directory):
if not os.path.exists(directory):
os.makedirs(directory)
# 从文件加载模型
def load_all_models(n_start, n_end):
all_models = list()
for epoch in range(n_start, n_end):
# 为这个集合定义文件名
filename = "models/model_" + str(epoch) + ".h5"
# 从文件加载模型
model = load_model(filename)
# 添加到成员列表
all_models.append(model)
print(">loaded %s" % filename)
return all_models
# 对多类分类进行集成预测
def ensemble_predictions(members, testX):
# 作出预测
yhats = [model.predict(testX) for model in members]
yhats = array(yhats)
# 整体成员的总和
summed = numpy.sum(yhats, axis=0)
# 跨类的argmax
result = argmax(summed, axis=1)
return result
# 评估集合中特定数量的成员
def evaluate_n_members(members, n_members, testX, testy):
# 选择成员的子集
subset = members[:n_members]
# 做出预测
yhat = ensemble_predictions(subset, testX)
# 计算精度
return accuracy_score(testy, yhat)
make_dir("models")
batch_size = 32
num_classes = 10
epochs = 100
num_predictions = 20
model_name = "keras_cifar10_trained_model.h5"
# 数据,分为训练集和测试集:
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print("x_train shape:", x_train.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")
# 将类向量转换为二元类矩阵。
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, (3, 3), padding="same", input_shape=x_train.shape[1:]))
model.add(Activation("relu"))
model.add(Conv2D(32, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(Conv2D(64, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation("softmax"))
# 启动 RMSprop 优化器
opt = keras.optimizers.RMSprop(learning_rate=0.0001, decay=1e-6)
# 让我们使用 RMSprop 训练模型
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
x_train = x_train.astype("float32")
x_test = x_test.astype("float32")
x_train /= 255
x_test /= 255
# 拟合模型
n_epochs, n_save_after = 15, 10
for i in range(n_epochs):
# 适合单个时期的模型
print("Epoch: ", i)
model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=1,
validation_data=(x_test, y_test),
shuffle=True,
)
# 检查我们是否应该保存模型
if i >= n_save_after:
model.save("models/model_" + str(i) + ".h5")
# 按顺序加载模型
members = load_all_models(5, 10)
print("Loaded %d models" % len(members))
# 反向加载模型,所以我们首先用最后一个模型构建集成
members = list(reversed(members))
# 在保持集上评估不同数量的集成
single_scores, ensemble_scores = list(), list()
for i in range(1, len(members) + 1):
# 评估有 i 个成员的模型
y_test_rounded = numpy.argmax(y_test, axis=1)
ensemble_score = evaluate_n_members(members, i, x_test, y_test_rounded)
# 独立评估第 i 个模型
_, single_score = members[i - 1].evaluate(x_test, y_test, verbose=0)
# 单个模型与整体输出的打印精度
print("%d: single=%.3f, ensemble=%.3f" % (i, single_score, ensemble_score))
ensemble_scores.append(ensemble_score)
single_scores.append(single_score)
# Output:
# 1: single=0.731, ensemble=0.731
# 2: single=0.710, ensemble=0.728
# 3: single=0.712, ensemble=0.725
# 4: single=0.710, ensemble=0.727
# 5: single=0.696, ensemble=0.724清单 3-4 横向投票合奏
快照合奏
快照集成 是水平投票集成的扩展。您无需在达到最小阈值后保存模型,而是修改模型本身的学习率。如果您阅读过或实施过深度学习模型,您可能已经知道这种现象。在训练机器学习模型时,通常希望开始初始的高级学习,然后慢慢降低学习率。
在图3-4中,我们用一个训练周期来改变学习率。但通常情况下,这种方法会在桌面上留下很多优化,因为可以在任何局部最小值处进行训练。
这个局部最小值问题的主要解决方案之一是循环学习率,我们在循环中增加和减少学习率。
图3-4显示,在每 400 个 epoch 之后,我们将学习率改回最大值,然后从那里开始降低学习率。

图 3-4 快照合奏
如果您想了解有关快照集成的更多信息,请参阅康奈尔大学 2017 年撰写的论文,网址为https://arxiv.org/abs/1704.00109。在本文的图 1 中,标准 SGD 优化器中有一个损失与学习率的关系图。它包括一个简单的学习率计划和一个循环学习率计划。当达到某个最小值时,我们简单地以当时获得的权重和偏差值的形式保存模型状态,并提高我们的学习率(即,采取更大的步骤)。您可以将这个较大的步骤视为落在该图中不同点的跳跃点,并开始寻找下一个最小值。最后,有一组错误率低的模型。
就像水平投票合奏一样,每个局部最小状态的所有模型都被组合在一起。与单独使用单个模型相比,这种方法会产生非常好的模型。
概括
让我们快速回顾一下您在本章中学到的内容。
涉及混合模型策略的集成学习技术
投票合奏及其两个变体:软投票和硬投票
超参数调优集成,您可以在其中组合具有不同超参数的模型
Horizontal voting ensembles ,这在深度学习中特别有用
快照集成技术
在第4章中,您将学习如何通过尝试混合组合策略来构建集成模型。