Spark综合学习笔记(十六)SparkStreaming整合Kafka-代码实现3-手动提交偏移量到MYSQL
学习致谢:
https://www.bilibili.com/video/BV1Xz4y1m7cv?p=50
需求:
手动提交偏移量到MYSQL
代码实现
(1)SparkStreaming_Kafka_Demo03
package streaming
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* Author itcast
* DESC 演示使用spark-atreaming-kafka-0-10_2.12中的Direct模式连接Kafka消费数据+手动提交offset到MYSQL
*/object SparkStreaming_Kafka_Demo03 {
//TODO 0.准备环境
val conf:SparkConf=new SparkConf().setMaster("spark").setMaster("local[*]")
val sc: SparkContext=new SparkContext(conf)
sc.setLogLevel("WARN")
//the time interval at which streaming data will be dicided into batches
val ssc:StreamingContext= new StreamingContext(sc,Seconds(5))//每隔5秒划分一个批次
ssc.checkpoint("./ckp")
//TODO 1.加载数据-从Kafka
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1:9092",//kafka集群地址
"key.deserializer" -> classOf[StringDeserializer],//key的反序列化规则
"value.deserializer" -> classOf[StringDeserializer],//value的反序列化规则
"group.id" -> "sparkdemo",//消费者组名称
//earliest:表示如果有offset记录从offset记录开始消费,如果没有从最早的消息开始消费
//latest:表示如果有offset记录从offset记录开始消费,如果没有从最后/最新的消息开始消费
//none:表示如果有offset记录从offset记录开始消费,如果没有就报错
"auto.offset.reset" -> "latest",//如果有offset记录从offset开始消费,没有从最新开始消费
//"auot.commit.interval.ms"->"1000",//自动提交的实际间隔
"enable.auto.commit" -> (false: java.lang.Boolean)//是否自动提交
)
val topics = Array("spark_kafka")//要订阅的主题
//Map[主题分区,offset]
val offsetMap: mutable.Map[TopicPartition, Long] = OffsetUtil.getOffsetMap("sparkdemo","spark_kafka")
val kafkaDS:InputDStream[ConsumerRecord[String,String]] = if (offsetMap.size>0){
println("MYSQL中存储了该消费者组消费该主题的偏移量记录,接下来从记录处开始消费")
//使用工具类从kafka中消费消息
KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,//位置策略,使用源码中推荐的
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams,offsetMap)//消费策略,使用源码中推荐的
)
}else{
println("MYSQL中没有存储了该消费者组消费该主题的偏移量记录,接下来从latest开始消费")
//使用工具类从kafka中消费消息
KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,//位置策略,使用源码中推荐的
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)//消费策略,使用源码中推荐的
)
}
//TODO 2.处理消息
//注意提交的时机:应该是消费完一批就该提交一次offset而在DStream一小批的体现是RDD
kafkaDS.foreachRDD(rdd=> {
if (!rdd.isEmpty()) {
//消费
rdd.foreach(record => {
val topic: String = record.topic()
val partition: Int = record.partition()
val offset: Long = record.offset()
val key: String = record.key()
val value: String = record.value()
val info: String = s"""topic:${topic},partition:${partition},,offset:${offset}, key:${key}. value:${value} """
println("消费到的消息的 详细信息为" + info)
})
//获取rdd中offset相关的信息:offsetRanges里面就包含了该批次各个分区的offset信息
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
//提交
// kafkaDS.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
//提交到MYSQL
OffsetUtil.savepOFfsetRanges("sparkdemo",offsetRanges)
println("当前批次的数据已消费并手动提交到MYSQL")
}
})
//TODO 3.输出结果
//TODO 4.启动并等待结束
ssc.start()
ssc.awaitTermination()//注意:流式应用程序启动之后需要一直运行等待停止、等待到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true,stopGracefully = true)//优雅关闭
}
(2)mysql工具类
package streaming
import java.sql.{DriverManager, ResultSet}
import org.apache.kafka.common.TopicPartition
import org.apache.spark.streaming.kafka010.OffsetRange
import scala.collection.mutable
/**
* DESC: 连接MYSQL操作工具类
*/
/**
手动维护offset的工具类首先在MySQL创建如下表
CREATE TABLE `t_offset`(
`topic` varchar(255) NOT NULL,
`partition`int(11)NOT NULL,
`groupid` varchar(255) NOT NULL,
`offset` bigint(20) DEFAULT NULL,
PRIMARY KEY ( `topic`, `partition`, `groupid`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
object OffsetUtil{
//1.将偏移量保存到数据库
def savepOFfsetRanges(groupid: String,offsetRange: Array[OffsetRange]) = {
val connection = DriverManager .getConnection("jdbc.mysq1://localhost:306/bigdataicharacterE5ncoding-JTF-8","root", "root")
//replace into表示之前有就替换,没有就插入
val ps = connection.prepareStatement("'replace into t_offset ( 'topic ', 'partition ', `gnoupid' , 'offset ) values(?,?,?,?)")
for (o <- offsetRange) {
ps.setString(1, o.topic)
ps.setInt(2, o.partition)
ps.setString(3, groupid)
ps.setLong(4, o.untilOffset)
ps.executeUpdate()
}
ps.close()
connection.close()
}
//2.从数据库读取偏移量Map(主题分区,offset)
def getOffsetMap(groupid: String, topic: String)= {
val connection=DriverManager.getConnection("jdbc:mysqL//localhost:336/bigdatalcharacterEncoding=JTF-8","rot", "rot ")
val ps = connection.prepareStatement("select * from t_offset where groupid=? and topic=?")
ps.setString( 1, groupid)
ps.setString(2,topic)
val rs: ResultSet = ps.executeQuery()
//Map(主题分区,offset)
val offsetMap = mutable.Map[TopicPartition,Long]()
while (rs.next()){
offsetMap += new TopicPartition(rs.getString("topic" ), rs.getInt( "partition")) ->rs.getLong( "offset")}
rs.close()
ps.close()
connection.close()
offsetMap
}
}
(3)建表语句
CREATE TABLE `t_offset`(
`topic` varchar(255) NOT NULL,
`partition`int(11)NOT NULL,
`groupid` varchar(255) NOT NULL,
`offset` bigint(20) DEFAULT NULL,
PRIMARY KEY ( `topic`, `partition`, `groupid`)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
演示
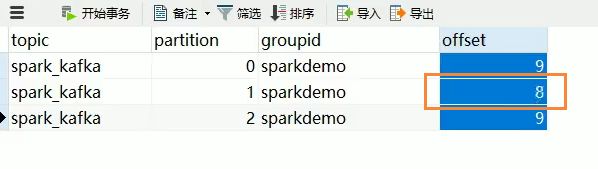
(1)输入a,b,c,d

查看控制台和mysql表中数据,可以看到offset都修改为下一偏移量,

因为MySQL工具类源码中设置获取untilOffset(下一位置)

(2)再在kafka中输入e

查看mysql,对应partition1的offset加一,变为8