图解seq2seq+attention机制
seq2seq 是一个Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列, Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。–简书
一、注意力机制Attention
任务:德文翻译为英文
先讲解Encoder部分的注意力机制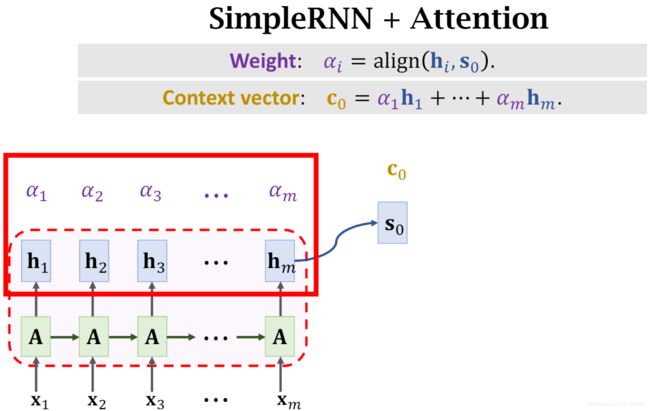
x i x_i xi:表示输入的每一个德文单词(严谨的说,应该是德文单词的向量表示word_embedding)
A:Encoder,隐藏层,可以是GRU、LSTM、RNN
h i h_i hi:每个时刻最后一层生成的隐藏层状态
h m h_m hm:最后一层最后时刻生成的隐藏层状态
s 0 s_0 s0:数值上= h m h_m hm,在此记为换个名字
α i α_i αi: s 0 s_0 s0与 h i h_i hi的"相似度"(相关性)的权重表示
Weight: α i \alpha_i αi=align( s 0 s_0 s0, h i h_i hi)
计算得到 m 个相关性αi之后,将这些值与hi进行加权平均
c 0 = ∑ i = 1 m α i h i = α 1 h 1 + ⋅ ⋅ ⋅ α m h m c_0=\sum_{i=1}^m \alpha_i h_i=\alpha_1h_1+···\alpha_mh_m c0=∑i=1mαihi=α1h1+⋅⋅⋅αmhm
c 0 c_0 c0称为context vector ,上下文背景变量
- 简单说明一下计算 c 0 c_0 c0的原因:
对于那些权重比较大的 α k α_k αk,最终 c 0 c_0 c0中也会有一大部分来自于 α k α_k αk。 c 0 c_0 c0实际上考虑到了所有时刻的隐藏层变量h,而h又是输入的x的表示。也就是说 c 0 c_0 c0考虑了所有的输入,但对于重要的输入时刻关注得更多,而某些时刻关注的更少,这就是注意力机制。
接下来讲解Decoder部分的注意力机制
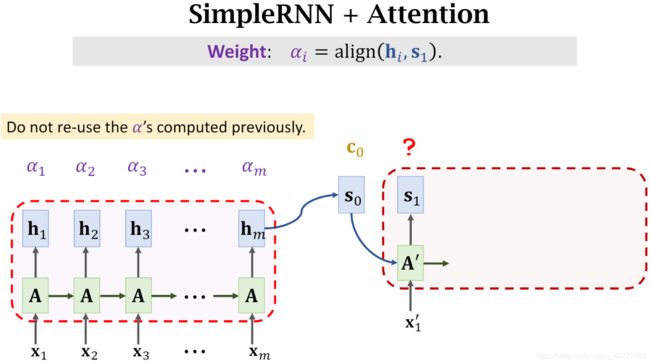
x i ’ x_i^’ xi’:表示正确的的英文单词翻译输入
A ’ A^’ A’:Decoder隐藏层,也是RNN或RNN的变种
s 0 s_0 s0:在Encoder部分计算得到的
将 s 0 , c 0 , x 1 ’ s_0,c_0,x_1^’ s0,c0,x1’作为 t 0 t_0 t0时刻 Decoder 的输入,计算得到 s 1 s_1 s1,然后再计算 s 1 s_1 s1与所有 h i ( i = 1 , . . . , m ) h_i\ (i=1,...,m) hi (i=1,...,m)之间新的相关性 α i \alpha_i αi
同样的,将新计算得到的 α i \alpha_i αi与 h i h_i hi做加权平均,得到新的 context vector c 1 c_1 c1
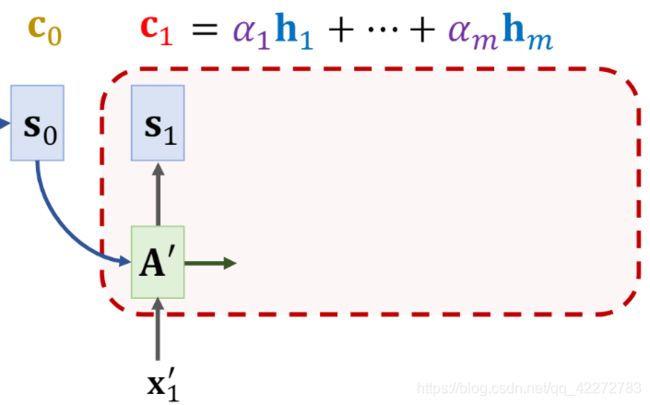
重复上述步骤,直到 Decoder 结束
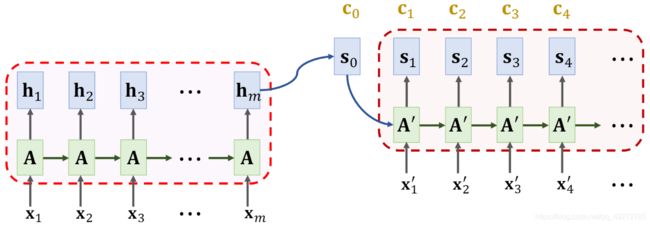
ps:简化版的Decoder也可能没有多次计算context vector ci,而是用c0一以贯之。
二、编码器 — 解码器
编码器和解码器分别对应输入序列和输出序列的两个循环神经网络。我们通常会在输入序列和输出序列后面分别附上一个特殊字符
二(1)、编码器Encoder
注:context vextor:称背景向量、上下文向量、上下文背景向量
编码器的作用是把一个不定长的输入序列转化成一个定长的背景词向量c。该背景词向量包含了输入序列的信息。常用的编码器是循环神经网络。
假设 x t x_t xt是单个输出在嵌入层的结果,即输入。
隐藏层变量为
h t = f ( x t , h t − 1 ) \boldsymbol{h}_t = f(\boldsymbol{x}_t, \boldsymbol{h}_{t-1}) ht=f(xt,ht−1)
编码器的上下文背景向量为
c = q ( h 1 , … , h T ) \boldsymbol{c} = q(\boldsymbol{h}_1, \ldots, \boldsymbol{h}_T) c=q(h1,…,hT)
一个简单的背景向量可以认为是该网络最终时刻的隐藏层变量 。我们将这里的循环神经网络叫做编码器。
当我们希望编码器的输入既包含正向传递信息又包含反向传递信息时,我们可以使用双向循环神经网络:
如果输入序列是 ,在正向传递中 x 1 , x 2 , . . . , x T \boldsymbol {x}_1,\boldsymbol {x}_2,...,\boldsymbol {x}_T x1,x2,...,xT,隐藏层变量为:
h → t = f ( x t , h → t − 1 ) \overrightarrow {\boldsymbol{h}}_t = f(\boldsymbol{x}_t,\overrightarrow {\boldsymbol{h}}_{t-1}) ht=f(xt,ht−1)
而反向传递过程中 x T , x T − 1 , . . . , x 1 \boldsymbol {x}_T,\boldsymbol {x}_T-1,...,\boldsymbol {x}_1 xT,xT−1,...,x1,隐藏层变量的计算变为:
h ← t = f ( x t , h ← t − 1 ) \overleftarrow {\boldsymbol{h}}_t = f(\boldsymbol{x}_t,\overleftarrow {\boldsymbol{h}}_{t-1}) ht=f(xt,ht−1)
此时的隐藏层变量为:
h ← t = f ( h → t − 1 , h ← t − 1 ) \overleftarrow {\boldsymbol{h}}_t = f(\overrightarrow{\boldsymbol{h}}_{t-1},\overleftarrow {\boldsymbol{h}}_{t-1}) ht=f(ht−1,ht−1)
二(2)、解码器Decoder
编码器最终输出了一个上下文背景向量c,该背景向量整合了输入序列 x 1 , x 2 , . . . , x T \boldsymbol {x}_1,\boldsymbol {x}_2,...,\boldsymbol {x}_T x1,x2,...,xT
假设训练数据中的输出序列是 y 1 , y 2 , . . . , y T ′ \boldsymbol {y}_1,\boldsymbol {y}_2,...,\boldsymbol {y}_{T'} y1,y2,...,yT′,我们希望表示每个 t ’ t^’ t’时刻输出的向量,既取决于之前的输出又取决于背景向量。因为,我们可以最大化输出序列的联合概率
P ( y 1 , y 2 , . . . , y T ′ ) = ∏ t ′ = 1 T ′ P ( y t ′ ∣ y 1 , . . . , y t ′ − 1 , c ) P(\boldsymbol{y}_1,\boldsymbol{y}_2,...,\boldsymbol{y}_{T'})=\prod_{t'=1}^{T'}P(\boldsymbol{y}_{t'}\mid \boldsymbol{y}_1,...,\boldsymbol{y}_{t'-1},\boldsymbol{c}) P(y1,y2,...,yT′)=∏t′=1T′P(yt′∣y1,...,yt′−1,c)
为此,我们使用另一个循环神经网络作为解码器。解码器使用函数p来表示单个输出 y t ′ \boldsymbol {y}_{t'} yt′的概率
P ( y t ′ ∣ y 1 , . . . , y t ′ − 1 , c ) = p ( y t ′ − 1 , s t ′ , c ) P(\boldsymbol{y}_{t'}\mid \boldsymbol{y}_1,...,\boldsymbol{y}_{t'-1},\boldsymbol{c})=p(\boldsymbol{y}_{t'-1},\boldsymbol{s}_{t'},\boldsymbol{c}) P(yt′∣y1,...,yt′−1,c)=p(yt′−1,st′,c)
其中的 s t ′ \boldsymbol{s}_{t'} st′为 t ′ \boldsymbol{t'} t′时刻的解码器的隐藏层变量。该隐藏层变量
s t ′ = g ( y t ′ − 1 , c , s t ′ − 1 ) \boldsymbol{s}_{t'}=g(\boldsymbol{y}_{t'-1},\boldsymbol{c},\boldsymbol{s}_{t'-1}) st′=g(yt′−1,c,st′−1)
其中函数 g 是循环神经网络单元。
需要注意的是,编码器和解码器通常会使用多层循环神经网络
图解attention