CUDA C编程10:核函数可达到的带宽
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、理论知识
- 二、案例分享
-
- 2.1 朴素转置
- 2.2 展开转置
- 2.3 对角转置
- 2.4 通过瘦块方法来增加并行性
- 2.5 完整代码:
- 总结
- 参考资料
前言
忙里偷闲,继续学习CUDA C编程,今天开始学习核函数的带宽的相关知识点,提高性能。
一、理论知识
分析核函数性能时,要注意以下两点:
(1)内存延迟:完成一次内存请求的时间;
(2)内存带宽:SM访问设备内存的速度,以每单位时间内的字节数来度量。
之前了解的改进核函数性能的方法有两种:
(1)通过最大化并行线程束执行数来隐藏内存延迟,这主要是通过维持更多正在执行的内存访问来达到更好的总线利用率。
(2)通过适当的对齐和合并内存访问来最大化内存带宽效率。
在一个原本不好的访问模式下,如何设计核函数来实现良好的性能就是本节要介绍的内容。
大多数核函数都有内存带宽的限制,因此在调整核函数时要格外注意内存带宽的指标。
影响带宽的因素有两个:
(1)全局内存中数据的安排方式
(2)线程束访问数据的方式
带宽的类型有两种:
(1)理论带宽:当前硬件的绝对最大带宽。
(2)有效带宽:核函数实际可达到的带宽
有 效 带 宽 ( G B / s ) = ( 读 字 节 数 + 写 字 节 数 ) × 1 0 − 9 ) 运 行 时 间 有效带宽(GB/s)=\frac{(读字节数+写字节数)\times 10^{-9})}{运行时间} 有效带宽(GB/s)=运行时间(读字节数+写字节数)×10−9)
二、案例分享
这里以矩阵转置为例介绍测量和调整核函数的有效带宽。
矩阵转置就是将矩阵的行与列交换。
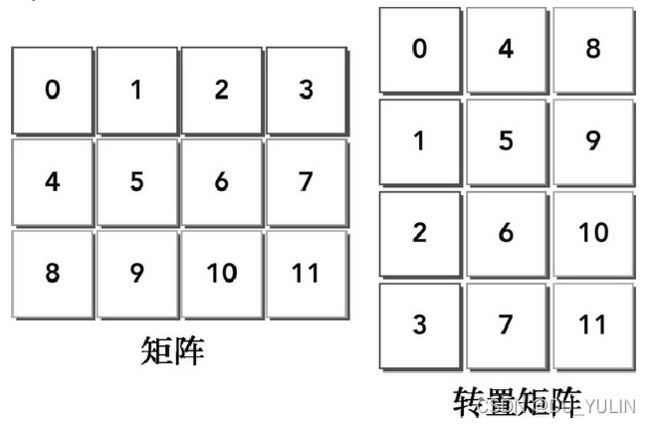
主机上实现矩阵转置函数实现代码片段如下:
void transposeHost(float* out, float* in, const int nx,
const int ny)
{
for (int iy = 0; iy < ny; iy++)
{
for (int ix = 0; ix < nx; ix++)
{
out[ix*ny + iy] = in[iy*nx + ix];
}
}
}
用一维数组保存二维矩阵,
(1)读:通过原矩阵的行进行访问,结果为合并访问;
(2)写:通过转置矩阵的列进行访问,结果为交叉访问;
交叉访问是GPU性能最差的内存访问模式,但在矩阵转置中不可避免。这里介绍两种转置核函数提高带宽利用率:
(1)按行读取,按列存储;
(2)按列读取,按行存储;
如果禁用一级缓存加载,上述两种实现性能相同;如果启用一级缓存,那么方法(2)性能会更好。
为什么启动一级缓存,方法(2)性能更好呢?
按列读取操作是不合并的(因此带宽会浪费在未被请求的字节上),将这些额外的字节存入一级缓存意味着下一个读操作可能会在缓存上执行而不在全局内存上执行。因为写操作不在一级缓存中缓存,所以对按列执行写操作而言,任何缓存都没有意义。个人理解,按列读取,可以利用一级缓存提高交叉访问的性能,按行存储,可以利用合并访问提高存储的效率。
利用两个拷贝核函数可以粗略计算所有转置核函数性能的上下限:
(1)通过加载(读)和存储(写)行来实现拷贝矩阵的上限(最高效率),只能使用合并访问;
//the highest efficiency about transpose matrix
__global__ void copyRow(float* out, float* in, const int nx,
const int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
if (ix < nx && iy < ny)
{
out[iy*nx + ix] = in[iy*nx + ix];
}
}
(2)通过加载(读)和存储(写)列来实现拷贝矩阵的下限(最低效率),只能使用交叉访问;
//the lowest efficiency about transpose matrix
__global__ void copyCol(float* out, float* in, const int nx,
const int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
if (ix < nx && iy < ny)
{
out[ix*ny + iy] = in[ix*ny + iy];
}
}
2.1 朴素转置
朴素转置就是将CPU上执行的按行与按列转置函数转换为设备函数:
__global__ void transposeNaiveRow(float* out, float* in, const int nx, const int ny)
{
unsigned int ix = threadIdx.x + blockDim.x * blockIdx.x;
unsigned int iy = threadIdx.y + blockDim.y * blockIdx.y;
if (ix < nx && iy < ny)
{
out[ix * ny + iy] = in[iy * nx + ix];
}
}
__global__ void transposeNaiveCol(float* out, float* in, const int nx, const int ny)
{
unsigned int ix = threadIdx.x + blockDim.x * blockIdx.x;
unsigned int iy = threadIdx.y + blockDim.y * blockIdx.y;
if (ix < nx && iy < ny)
{
out[iy * nx + ix] = in[ix * ny + iy];
}
}
2.2 展开转置
利用展开技术来提高转置内存带宽利用率,展开的目的是为每个线程分配更独立的任务,从而最大化当前内存请求。
// unroll transpose
__global__ void transposeUnroll4Row(float* out, float* in,
const int nx, const int ny)
{
unsigned int ix = threadIdx.x + blockDim.x * blockIdx.x * 4;
unsigned int iy = threadIdx.y + blockDim.y * blockIdx.y;
unsigned int ti = iy * nx + ix;
unsigned int to = ix * ny + iy;
if (ix + 3 * blockDim.x < nx && iy < ny)
{
out[to] = in[ti];
out[to + ny * blockDim.x] = in[ti + blockDim.x];
out[to + 2 * ny*blockDim.x] = in[ti + 2 * blockDim.x];
out[to + 3 * ny*blockDim.x] = in[ti + 3 * blockDim.x];
}
}
__global__ void transposeUnroll4Col(float* out, float* in,
const int nx, const int ny)
{
unsigned int ix = threadIdx.x + blockDim.x * blockIdx.x * 4;
unsigned int iy = threadIdx.y + blockDim.y * blockIdx.y;
unsigned int ti = iy * nx + ix;
unsigned int to = ix * ny + iy;
if (ix + 3 * blockDim.x < nx && iy < ny)
{
out[ti] = in[to];
out[ti + blockDim.x] = in[to + blockDim.x*ny];
out[ti + 2 * blockDim.x] = in[to + 2 * blockDim.x * ny];
out[ti + 3 * blockDim.x] = in[to + 3 * blockDim.x*ny];
}
}
2.3 对角转置
当启用一个线程块网格时,线程块被分配给SM。每个线程块都有其唯一标识符 b i d bid bid,可用网格中线程块按行优先顺序计算:
b i d = b l o c k I d x . y ∗ g r i d D i m . x + b l o c k I d x . x bid=blockIdx.y*gridDim.x+blockIdx.x bid=blockIdx.y∗gridDim.x+blockIdx.x
当启用一个核函数时,线程块被分配给SM的顺序由 b i d bid bid决定。由于线程块完成的速度和顺序是不确定的,随着内核进程的执行,起初通过 b i d bid bid相连的活跃线程块会变得不连续。
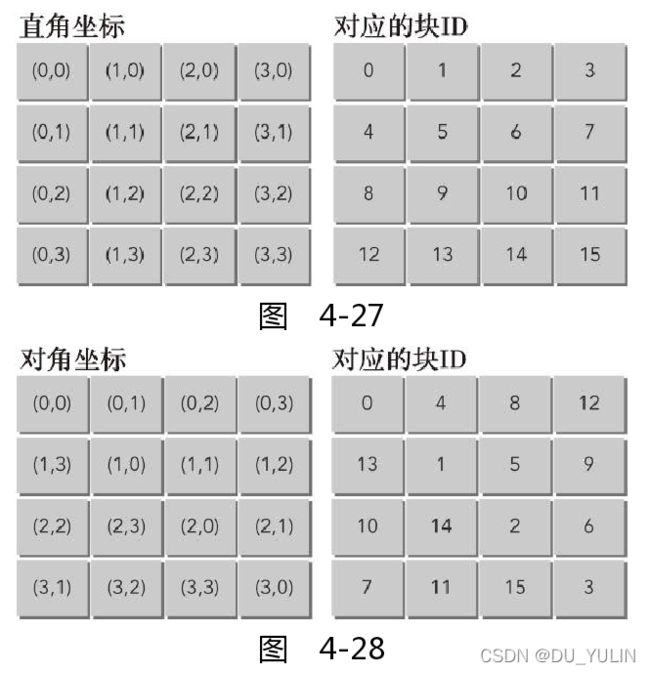
上图对角坐标需要映射到笛卡尔坐标中,以便访问到正确的数据块,映射公式如下:
b l o c k _ x = ( b l o c k I d x . x + b l o c k I d x . y ) block\_x = (blockIdx.x+blockIdx.y)%gridDim.x block_x=(blockIdx.x+blockIdx.y)
b l o c k _ y = b l o c k I d x . x block\_y = blockIdx.x block_y=blockIdx.x
上式中 b l o c k I d x . x , b l o c k I d x . y blockIdx.x, blockIdx.y blockIdx.x,blockIdx.y表示对角坐标。
通过使用对角坐标系修改线程块的执行顺序,使得基于行的核函数性能得到提升。这种提升与DRAM并行访问有关,发送给全局内存的请求由DRAM分区完成。设备内存中连续的256字节区域被分配到连续分区。当使用笛卡尔坐标将线程块映射到数据块时,全局内存访问可能无法均匀地被分配到整个DRAM分区中,这时可能发生“分区冲突”。发生分区冲突是,内存请求在某些分区排队等候,另一些分区则一直未被调用。因为对角坐标映射造成线程块到待处理数据块的非线程映射,所以交叉访问不太可能落入到一个独立的分区中,会带来性能提升。
对最佳性能来说,被所有活跃的线程束并发访问的全局内存应该在分区中被均匀地划分。
下图笛卡尔坐标出现分区冲突,假设通过两个分区访问全局内存,每个分区256字节,如果每个数据块为128字节,则需要两个分区为第0,1,2,3个线程块加载数据。但现在只能使用一个分区为第0,1,2,3,个线程块存储数据,造成了分区冲突。
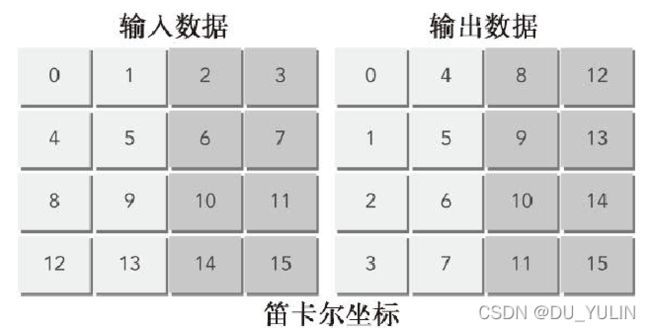
下图采用对角坐标,使用两个分区为第0,1,2,3个线程块加载和存储数据,加载和存储请求在两个分区间被均匀分配。

//Diagonal transpose
__global__ void transposeDiagonalRow(float* out, float* in,
const int nx, const int ny)
{
unsigned int blk_y = blockIdx.x;
unsigned int blk_x = (blockIdx.x + blockIdx.y) % gridDim.x;
unsigned int ix = blockDim.x * blk_x + threadIdx.x;
unsigned int iy = blockDim.y * blk_y + threadIdx.y;
if (ix < nx && iy < ny)
{
out[ix * ny + iy] = in[iy * nx + ix];
}
}
__global__ void transposeDiagonalCol(float* out, float* in,
const int nx, const int ny)
{
unsigned int blk_y = blockIdx.x;
unsigned int blk_x = (blockIdx.x + blockIdx.y) % gridDim.x;
unsigned int ix = blockDim.x * blk_x + threadIdx.x;
unsigned int iy = blockDim.y * blk_y + threadIdx.y;
if (ix < nx && iy < ny)
{
out[iy * nx + ix] = in[ix * ny + iy];
}
}
2.4 通过瘦块方法来增加并行性
增加并行性最简单的方法就是调整块的大小,通过尝试不同块的大小来总结出最优的块大小。
2.5 完整代码:
#include >> "
"effective bandwidth %f GB\n", kernelName, iElaps, grid.x,
grid.y, block.x, block.y, ibnd);
// check kernel results
if (iKernel > 1)
{
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
checkResult(hostRef, gpuRef, nx*ny);
}
//free host and device memory
cudaFree(d_A);
cudaFree(d_C);
free(h_A);
free(hostRef);
free(gpuRef);
//reset device
cudaDeviceReset();
system("pause");
return 0;
}
总结
这部分的内容信息量很大,有些部分的内容还是不太理解,比如对角转置提升性能方面,而且个人PC进行实验,结果也与预期不符,可能是数据量太小的关系,后面还需要继续深入理解。
参考资料
《CUDA C编程权威指南》