论文笔记(三)《Unsupervised representation learning using deep convolution to generate adversarial network》
0 Abstract
近年来,利用卷积网络(CNNs)进行的有监督学习在计算机视觉应用中得到了巨大的应用。相对而言,使用CNNs的无监督学习受到的关注较少。在这项工作中,我们希望能够帮助缩小CNNs在有监督学习和无监督学习之间的差距。我们介绍了一类被称为深度卷积生成对抗性网络(Deep convolutional generative adversarial networks,DCGANs)的CNNs,它们具有一定的架构约束,并证明它们是无监督学习的有力候选者。在各种图像数据集上进行训练,我们展示了我们的深度卷积对抗者对在生成器和判别器中学习到了从物体部分到场景的分层表示。此外,我们将学习到的特征用于新任务--证明了它们作为一般图像表示的适用性。
1 INTRODUCTION
在这篇论文中,我们做出了以下贡献--我们提出并评估了一组关于Convolutional GANs的架构拓扑的约束,使其在大多数情况下都能稳定地进行训练。我们将这一类架构命名为深度卷积GANs(Deep Convolutional GANs)--我们将训练好的判别器用于图像分类任务,显示出与其他无监督算法的竞争性能。在图像方面,人们可以对图像补丁进行分层聚类(Coates & Ng, 2012),以学习强大的图像表示。另一种流行的方法是训练自动编码器(卷积式、堆叠式(Vincent等,2010),将代码中的what和where分量分离出来(Zhao等,2015),梯形结构(Rasmus等,2015))),将图像编码成紧凑的代码,并对代码进行解码,尽可能准确地重构图像。这些方法也被证明可以从图像像素中学习到良好的特征表示。深度信念网络(Lee等人,2009)也被证明在学习分层表示方面有良好的效果。
2 RELATED WORK
无监督表示学习的一个经典方法是对数据进行聚类(例如使用K-means),并利用聚类来提高分类分数。
3 APPROACH AND MODEL ARCHITECTURE
稳定的深度卷积式GAN的架构指南
- 替换任何池化层,用分股卷积(判别器)和分股卷积层来取代任何池化层。
变量(生成器)。
- 在生成器和判别器中使用 batchnorm。
- 移除完全连接的隐藏层,以获得更深的架构。
- 在生成器中对所有层使用ReLU激活,除了输出层使用Tanh,其他层都使用ReLU激活。
- 在判别器中对所有层使用LeakyReLU激活。
4 DETAILS OF ADVERSARIAL TRAINING
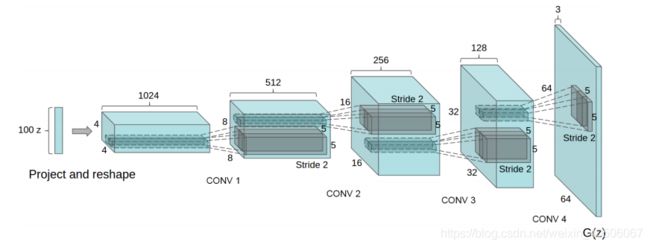
图1:用于LSUN场景建模的DCGAN生成器。一个100维的均匀分布Z被投射到具有许多特征图的小空间范围卷积表示。
然后,一系列的四个分层卷积(在最近的一些论文中,这些被错误地称为去卷积)将这个高阶表示转换为64×64像素的图像。值得注意的是,没有使用完全连接或池化层。
我们在三个数据集上训练了DCGANs,分别是大尺度场景理解(LSUN)(Yu等人,2015)、Imagenet-1k和一个新组装的Faces数据集。下面给出了这些数据集的详细使用方法。
除了缩放到tanh激活函数[-1,1]的范围外,没有对训练图像进行预处理。所有的模型都用迷你批次随机梯度下降(SGD)训练,迷你批次大小为128。所有的权重都是从零中心正态分布中初始化的,标准差为0.02。在LeakyReLU中,所有模型中的泄漏斜率都被设置为0.2。
虽然之前的GAN工作使用动量加速训练,但我们使用了Adam优化器(Kingma & Ba, 2014),并对超参数进行了调整。我们发现建议的学习率为0.001,太高了,我们用0.0002代替。此外,我们发现将动量项β1留在建议值0.9时,会导致训练振荡和不稳定,而降低到0.5有助于稳定训练。
4.1 LSUN

图2:经过一次训练通过数据集后生成的卧室。理论上,该模型可以学习记忆训练实例,但在实验中,这是不可能的,因为我们用较小的学习率和最小的SGD进行训练。据我们所知,之前没有任何经验证据证明在SGD和小学习率的情况下,模型可以学习记忆。
图3:五个时代的训练后产生的卧室。似乎有证据表明,在多个样本中,如一些床的底板,通过重复的噪音纹理,可以看出视觉上的不足。
4.1.1 DEDUPLICATION
4.2 FACES
4.3 IMAGENET-1K
5 EMPIRICAL VALIDATION OF DCGANS CAPABILITIES
为了评估DCGANs学习到的表征的质量,对监督任务的表征进行评估。我们在Imagenet-1k上进行训练,然后使用判别器的卷积特征从所有图层中提取。对每个图层的表示进行maxpool处理,生成一个4×4的空间网格。然后,这些特征被扁平化并串联,形成28672维向量和正则化的线性L2-SVM分类器在其上进行训练。准确率达到82.8%,超过了所有K-means的方法。

表1:使用我们的预训练模型的CIFAR-10分类结果。我们的DCGAN并没有对CIFAR-10进行预训练,而是在Imagenet-1k上进行了预训练,并对CIFAR-10图像进行了特征分类。
5.1 CLASSIFYING CIFAR-10 USING GANS AS A FEATURE EXTRACTOR
5.2 CLASSIFYING SVHN DIGITS USING GANS AS A FEATURE EXTRACTOR
6 INVESTIGATING AND VISUALIZING THE INTERNALS OF THE NETWORKS
6.1 WALKING IN THE LATENT SPACE
6.2 VISUALIZING THE DISCRIMINATOR FEATURES
6.3 MANIPULATING THE GENERATOR REPRESENTATION

图4:顶部行。Z中一系列9个随机点之间的插值显示,所学的空间具有平滑的过渡,空间中的每一个图像看起来都像一个卧室。在第6行中,你看到一个没有窗户的房间慢慢变成了一个有巨大窗户的房间。在第10排,你看到看似电视的东西慢慢地被改造成了窗户。
6.3.1 FORGETTING TO DRAW CERTAIN OBJECTS
6.3.2 VECTOR ARITHMETIC ON FACE SAMPLES
7 CONCLUSION AND FUTURE WORK
我们提出了一套更稳定的架构,用于训练生成式对抗性网络,我们给出了对抗性网络能够学习到良好的图像表示,用于监督学习和生成式建模的证据。仍然存在一些形式的模型不稳定性---我们注意到随着模型训练时间的延长,它们有时会将滤波器子集折叠成单一的振荡模式。
我们需要进一步的工作来解决这种不稳定的问题。我们认为,将这个框架扩展到其他领域,如视频(用于帧预测)和音频(用于语音合成的预训练特征)应该是非常有趣的。进一步研究学习的潜伏空间的属性也将是非常有趣的。