EfficientNet学习笔记
EfficientNet学习笔记
1.论文思想
在之前的一些论文中,有的会通过增加网络的width即增加卷积核的个数(增加特征矩阵的channels)来提升网络的性能如图(b)所示,有的会通过增加网络的深度即使用更多的层结构来提升网络的性能如图©所示,有的会通过增加输入网络的分辨率来提升网络的性能如图(d)所示。而在本篇论文中会同时增加网络的width、网络的深度以及输入网络的分辨率来提升网络的性能如图(e)所示:
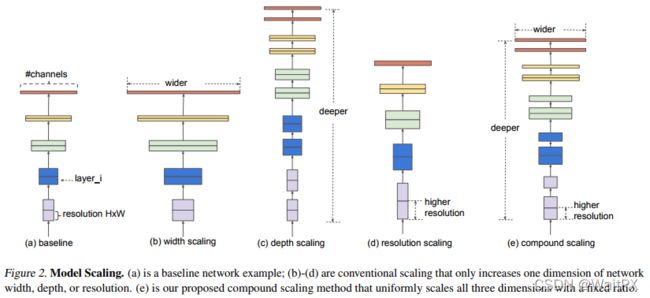
根据以往的经验,我们不难发现:
(1)增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。
(2)增加网络的width能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。
(3)增加输入网络的图像分辨率能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小。并且大分辨率图像会增加计算量。
下图展示了在基准EfficientNetB-0上分别增加width、depth以及resolution后得到的统计结果。通过下图可以看出大概在Accuracy达到80%时就趋于饱和了。
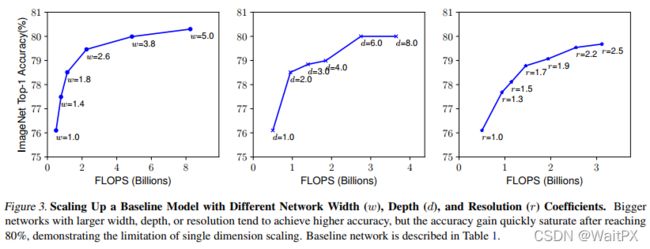
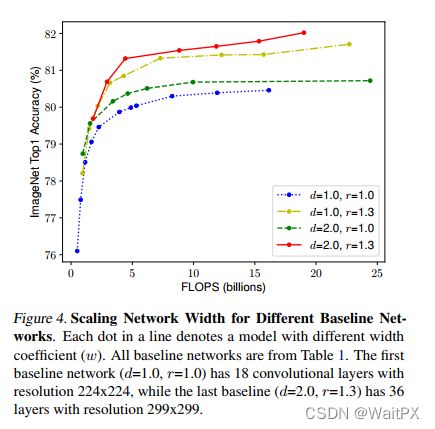
接着作者又做了一个实验,采用不同的d,r组合,然后不断改变网络的width就得到了如下图所示的4条曲线,通过分析可以发现在相同的FLOPs下,同时增加d和r的效果最好。
作者对整个网络模型的计算进行抽象:
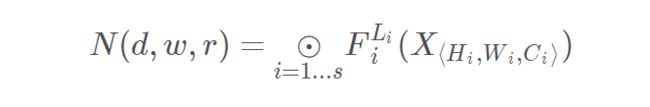
其中 F i L i F_i^{L_i} FiLi表示的是对第i个stage运算操作执行 L i L_i Li次,X表示的是 S t a g e i Stage_i Stagei的特征矩阵, H i , W i , C i H_i,W_i,C_i Hi,Wi,Ci表示的是X的高度,宽度和通道数。
为了探究d,r,w三个因子对最终准确率的影响,将d,r,w放入公式,我们可以得到抽象化后的优化问题(在指定资源限制下),s.t.代表限制条件,
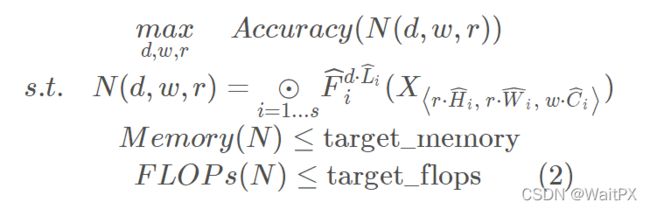
其中d用来缩放深度 L i ^ \hat {L_i} Li^,r用来缩放分辨率即影响 H i ^ 和 W i ^ \hat{H_i}和\hat{W_i} Hi^和Wi^,w用来缩放特征矩阵的通道即 C i ^ \hat{C_i} Ci^,target_memory为memory限制,target_flops为flops限制。
接着作者又提出了一个混合缩放方法 ( compound scaling method) 在这个方法中使用了一个混合因子ϕ去统一的缩放width,depth,resolution参数,具体的计算公式如下,其中 s.t.代表限制条件:

需要注意的是:
(1)FLOPs(理论计算量)与depth的关系是:当depth翻倍,FLOPs也翻倍。
(2)FLOPs与width的关系是:当width翻倍(即channal翻倍),FLOPs会翻4倍,因为卷积层的FLOPs约等于 f e a t u r e W × f e a t u r e H × f e a t u r e C × k e r n e l W × k e r n e l H × k e r n e l n u m b e r feature_W×feature_H×feature_C×kernel_W×kernel_H×kernel_number featureW×featureH×featureC×kernelW×kernelH×kernelnumber(假设输入输出特征矩阵的高宽不变),当width翻倍,输入特征矩阵的channels(feature_C)和输出特征矩阵的channels或卷积核的个数( kernel_number)都会翻倍,所以FLOPs会翻4倍。
(3)FLOPs与resolution的关系是:当resolution翻倍,FLOPs也会翻4倍,和上面类似因为特征矩阵的宽度 f e a t u r e W feature_W featureW 和特征矩阵的高度 f e a t u r e H feature_H featureH都会翻倍。
所以总的FLOPS的倍率可以用 ( α ⋅ β 2 ⋅ γ 2 ) ϕ (α⋅β^2⋅γ ^2)^ϕ (α⋅β2⋅γ2)ϕ来表示,当限制 ( α ⋅ β 2 ⋅ γ 2 ) (α⋅β^2⋅γ ^2) (α⋅β2⋅γ2)约等于2的时候,对于任意一个ϕ的FLOPS都增加了 2 ϕ 2^ϕ 2ϕ倍。
接下来作者在基准网络EfficientNetB-0上使用NAS来搜索 α , β , γ 这三个参数,
(1)首先固定 ϕ = 1 \phi=1 ϕ=1,并基于上面给出的公式(2)和(3)进行搜索,作者发现对于EfficientNetB-0最佳参数为 α = 1.2 , β = 1.1 , γ = 1.15 \alpha=1.2, \beta=1.1, \gamma=1.15 α=1.2,β=1.1,γ=1.15 。
(2)接着固定 α = 1.2 , β = 1.1 , γ = 1.15 \alpha=1.2, \beta=1.1, \gamma=1.15 α=1.2,β=1.1,γ=1.15,在EfficientNetB-0的基础上使用不同的 ϕ \phi ϕ分别得到EfficientNetB-1至EfficientNetB-7。
需要注意的是,对于不同的基准网络搜索出的 α , β , γ \alpha, \beta, \gamma α,β,γ也不定相同。还需要注意的是,在原论文中,作者也说了,如果直接在大模型上去搜索 α , β , γ \alpha, \beta, \gamma α,β,γ可能获得更好的结果,但是在较大的模型中搜索成本太大,所以这篇文章就在比较小的EfficientNetB-0模型上进行搜索的。
2.网络详细结构
下表为EfficientNet-B0的网络框架(B1-B7就是在B0的基础上修改Resolution,Channels以及Layers),可以看出网络总共分成了9个Stage,第一个Stage就是一个卷积核大小为3x3步距为2的普通卷积层(包含BN和激活函数Swish),Stage2~Stage8都是在重复堆叠MBConv结构(最后一列的Layers表示该Stage重复MBConv结构多少次),而Stage9由一个普通的1x1的卷积层(包含BN和激活函数Swish)一个平均池化层和一个全连接层组成。表格中每个MBConv后会跟一个数字1或6,这里的1或6就是倍率因子n即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷积核大小。Channels表示通过该Stage后输出特征矩阵的Channels。
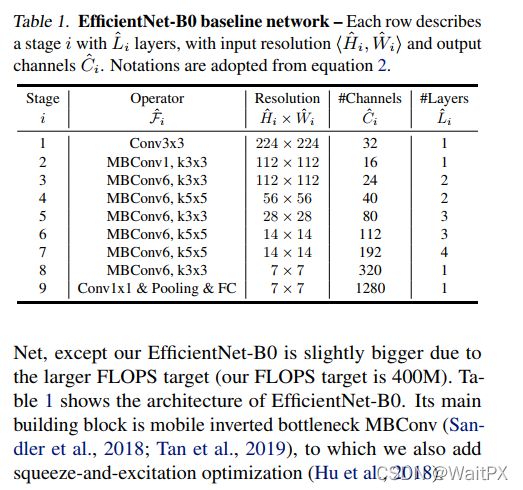
从上图我们可以发现,整个EfficientNet由7个部分的MBConv组成,对应于上图中的 S t a g e 1 − S t a g e 7 Stage_1-Stage_7 Stage1−Stage7,其具体参数如下所示:
BlockArgs(kernel_size=3, num_repeat=1, input_filters=32, output_filters=16, expand_ratio=1, id_skip=True, stride=[1], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=2, input_filters=16, output_filters=24, expand_ratio=6, id_skip=True, stride=[2], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=2, input_filters=24, output_filters=40, expand_ratio=6, id_skip=True, stride=[2], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=3, input_filters=40, output_filters=80, expand_ratio=6, id_skip=True, stride=[2], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=3, input_filters=80, output_filters=112, expand_ratio=6, id_skip=True, stride=[1], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=4, input_filters=112, output_filters=192, expand_ratio=6, id_skip=True, stride=[2], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=1, input_filters=192, output_filters=320, expand_ratio=6, id_skip=True, stride=[1], se_ratio=0.25)]
GlobalParams(batch_norm_momentum=0.99, batch_norm_epsilon=0.001, dropout_rate=0.2, num_classes=1000, width_coefficient=1.0,
depth_coefficient=1.0, depth_divisor=8, min_depth=None, drop_connect_rate=0.2, image_size=224)
MBConv结构
MBConv其实就是MobileNetV3网络中的InvertedResidualBlock,但也有些许区别。一个是采用的激活函数不一样(EfficientNet的MBConv中使用的都是Swish激活函数),另一个是在每个MBConv中都加入了SE(Squeeze-and-Excitation)模块。

如图所示,MBConv结构主要由一个1x1的普通卷积(升维作用,包含BN和Swish),一个kxk的Depthwise Conv卷积(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的普通卷积(降维作用,包含BN),一个Droupout层构成。
注意:
(1)第一个升维的1x1卷积层,它的卷积核个数是输入特征矩阵channel的n倍, n ∈ { 1 , 6 } n \in \left\{1, 6\right\} n∈{1,6}。
(2)当 n = 1时,不要第一个升维的1x1卷积层,即MBConv结构都没有第一个升维的1x1卷积层
(3)在shortcut的时候,只有当MBConv结构中的DepthwiseConv的stride为1以及输入过滤器的个数和输出过滤器的个数相等时候才可以使用。
(4)在SE模块中,第一个1×1卷积的通道是输入该MBConv特征矩阵channels的 1 4 \frac{1}{4} 41 ,且使用Swish激活函数。第二个1×1卷积的通道等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数。
class MBConvBlock(nn.Module):
'''
EfficientNet-b0:
[BlockArgs(kernel_size=3, num_repeat=1, input_filters=32, output_filters=16, expand_ratio=1, id_skip=True, stride=[1], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=2, input_filters=16, output_filters=24, expand_ratio=6, id_skip=True, stride=[2], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=2, input_filters=24, output_filters=40, expand_ratio=6, id_skip=True, stride=[2], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=3, input_filters=40, output_filters=80, expand_ratio=6, id_skip=True, stride=[2], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=3, input_filters=80, output_filters=112, expand_ratio=6, id_skip=True, stride=[1], se_ratio=0.25),
BlockArgs(kernel_size=5, num_repeat=4, input_filters=112, output_filters=192, expand_ratio=6, id_skip=True, stride=[2], se_ratio=0.25),
BlockArgs(kernel_size=3, num_repeat=1, input_filters=192, output_filters=320, expand_ratio=6, id_skip=True, stride=[1], se_ratio=0.25)]
GlobalParams(batch_norm_momentum=0.99, batch_norm_epsilon=0.001, dropout_rate=0.2, num_classes=1000, width_coefficient=1.0,
depth_coefficient=1.0, depth_divisor=8, min_depth=None, drop_connect_rate=0.2, image_size=224)
'''
def __init__(self, block_args, global_params):
super().__init__()
self._block_args = block_args
# 获得标准化的参数
self._bn_mom = 1 - global_params.batch_norm_momentum
self._bn_eps = global_params.batch_norm_epsilon
# 注意力机制的缩放比例
self.has_se = (self._block_args.se_ratio is not None) and (
0 < self._block_args.se_ratio <= 1)
# 是否需要短接边
self.id_skip = block_args.id_skip
Conv2d = get_same_padding_conv2d(image_size=global_params.image_size)
# 1x1卷积通道扩张
inp = self._block_args.input_filters # number of input channels
oup = self._block_args.input_filters * self._block_args.expand_ratio # number of output channels
if self._block_args.expand_ratio != 1:
self._expand_conv = Conv2d(
in_channels=inp, out_channels=oup, kernel_size=1, bias=False)
self._bn0 = nn.BatchNorm2d(
num_features=oup, momentum=self._bn_mom, eps=self._bn_eps)
# 深度可分离卷积
k = self._block_args.kernel_size
s = self._block_args.stride
self._depthwise_conv = Conv2d(
in_channels=oup, out_channels=oup, groups=oup,
kernel_size=k, stride=s, bias=False)
self._bn1 = nn.BatchNorm2d(
num_features=oup, momentum=self._bn_mom, eps=self._bn_eps)
# 注意力机制模块组,先进行通道数的收缩再进行通道数的扩张
if self.has_se:
num_squeezed_channels = max(
1, int(self._block_args.input_filters * self._block_args.se_ratio))
self._se_reduce = Conv2d(
in_channels=oup, out_channels=num_squeezed_channels, kernel_size=1)
self._se_expand = Conv2d(
in_channels=num_squeezed_channels, out_channels=oup, kernel_size=1)
# 输出部分
final_oup = self._block_args.output_filters
self._project_conv = Conv2d(
in_channels=oup, out_channels=final_oup, kernel_size=1, bias=False)
self._bn2 = nn.BatchNorm2d(
num_features=final_oup, momentum=self._bn_mom, eps=self._bn_eps)
self._swish = MemoryEfficientSwish()
def forward(self, inputs, drop_connect_rate=None):
x = inputs
if self._block_args.expand_ratio != 1:
x = self._swish(self._bn0(self._expand_conv(inputs)))
x = self._swish(self._bn1(self._depthwise_conv(x)))
# 添加了注意力机制
if self.has_se:
x_squeezed = F.adaptive_avg_pool2d(x, 1)
x_squeezed = self._se_expand(
self._swish(self._se_reduce(x_squeezed)))
x = torch.sigmoid(x_squeezed) * x
x = self._bn2(self._project_conv(x))
# 满足以下条件才可以短接
input_filters, output_filters = self._block_args.input_filters, self._block_args.output_filters
if self.id_skip and self._block_args.stride == 1 and input_filters == output_filters:
if drop_connect_rate:
x = drop_connect(x, p=drop_connect_rate,
training=self.training)
x = x + inputs # skip connection
return x
def set_swish(self, memory_efficient=True):
"""Sets swish function as memory efficient (for training) or standard (for export)"""
self._swish = MemoryEfficientSwish() if memory_efficient else Swish()
3.EfficientNetB-0~B-7的详细参数
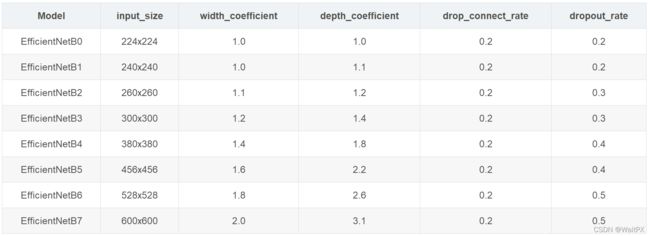
其中,
(1)input_size代表训练网络时输入网络的图像大小
(2)width_coefficient代表channel维度上的倍率因子,比如在 EfficientNetB0中Stage1的3x3卷积层所使用的卷积核个数是32,那么在B6中就是 32 × 1.8 = 57.6,接着取整到离它最近的8的整数倍即56,其它Stage同理。
(3)depth_coefficient代表depth维度上的倍率因子(仅针对Stage2到Stage8),比如在EfficientNetB0中Stage7的 L ^ i = 4 \hat L_i=4 L^i=4,那么在B6中就是 4 × 2.6 = 10.4接着向上取整即11。
(4)drop_connect_rate是在MBConv结构中dropout层使用的drop_rate,在官方keras模块的实现中MBConv结构的drop_rate是从0递增到drop_connect_rate的(具体实现可以看下官方源码,注意,在源码实现中只有使用shortcut的时候才有Dropout层)。还需要注意的是,这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。
(5)dropout_rate是最后一个全连接层前的dropout层(在stage9的Pooling与FC之间)的dropout_rate。
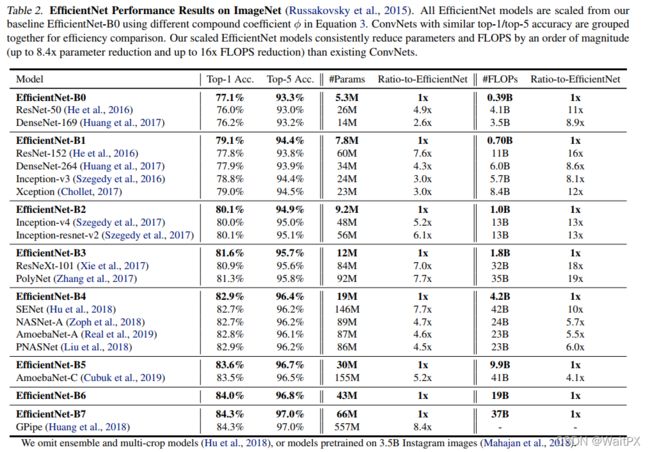
4.实验结果