从4篇论文看Transformer的局部信息建模

©PaperWeekly 原创 · 作者|张一帆
学校|华南理工大学本科生
研究方向|CV,Causality
本文根据时间线整理了几篇 transformer 相关的文章,如何更好地建模超长距离依赖以及其他优化问题。目前来看对于超长文本,我们大概有两个选择:
1)用一些启发式的手段,比如丢弃掉长的部分,或者分段处理;
2)改进 transformer 的架构,利用局部信息替代全局信息。在研究过程中,众多领域发现了局部信息的重要性,甚至每个注意力头都被设计为关注局部信息的 transformer 在很多任务依旧表现良好。

HIBERT

论文标题:
HIBERT: Document Level Pre-training of Hierarchical BidirectionalTransformers for Document Summarization
收录会议:
ACL 2019
论文链接:
https://arxiv.org/abs/1905.06566
代码链接:
https://github.com/abisee/cnn-dailymail
文章的 motivation 很简单,对于文章摘要抽取任务,传统工作是使用层次化的 encoder(RNN,CNN)来提取文章的表示,本文尝试了使用 transformer 来代替传统 encoder 并提出了一种用于摘要提取的预训练 encoder 的方式。
1.1 Document Representation
所谓层次化的 transformer,就是我们先对每个 sentence 抽取表示,然后将每个 sentence 的表示输入上一层 transformer 从而得到整个文章的表示。具体过程如下,我们先用一个 transformer 对每一个单词的 embedding 进行处理,我们选择每个句子 EOS token 最终的表示作为这个句子的表示,接下来所有句子会被扔进文档级别的 transformer 中。
这里需要注意的是,在处理每个单词的时候,我们会加上单词的 position encoding,同样在文档级别的 transformer 中我们会对每个 sentence 加上 position encoding。

1.2 Pre-Training
我们已经知道了 encoder 的设计,那么接下来的任务就是如何训练他,最好是无监督的训练。其实传统的 Summarization 任务中也是没有句子级别的 label 的,往往我们需要先对每个句子的 label 进行预测,然后用预测的 label 作为目标进行摘要抽取,这种自己预测的标签本来就是不准确的,要用它来训练这么复杂的层次化 encoder 是非常难以收敛的,因此文章更倾向于无监督的方式对 encoder 进行预训练。
对摘要抽取任务而言,我们要学习的是整个文章的表达,它的基本单元是句子,因此预训练应该以句子为单位,即将句子 mask 掉然后利用左,右侧的信息来预测 mask 掉的整个句子。Mask 的方式与 BERT 一致。
随机选择文档中 15% 的句子进行 mask,然后根据文档中其他的句子表示向量来预测 mask 的部分
80% 使用 [MASK] 进行填充
10% 使用从文档中随机选择的句子进行填充
10% 不改变选择的句子
从上面的模型图中可以看出,在预测 mask 的句子时同样是进行逐词预测,直到遇到 [EOS] 为止。特殊之处在于这里预测的每一步都会给当前预测词的 embedding 上该句子的 embedding。预训练的 loss 就是这些单词预测结果的负对数似然。
1.3 摘要生成
这里主要就是如何定义句子的重要性,摘要生成就是选择最重要的那些句子构成文章的摘要(给每个句子打上 True 或者 False 的标签)。因为我们已经将最重要的分层 encoder 预训练好了,所以直接 Linear projection 就能得到结果。
这时我们需要 sentence 真实的标签来对全连接层进行训练,文中是对每一个文章,选择一个句子的子集,该子集使得 ROUGE 指标最大。子集中的句子都打上 true,其余句子为 false。

1.4 Experiments
HiBERT 的总体分为三个部分:
1. 在 GIGA-CM 数据集上预训练(out-of-domain data)
2. 在 CNNDM(NYT50)数据集上预训练(in domain data)
3. 在 CNNDM(或者 NYT50)fine-tune(即使用摘要生成的目标进行训练)
在定量的分析上,HiBERT 击败了现有的方法。其中下标 S 表示模型使用上述提到的预训练数据集,in-domain 表示只使用 CNNDM,M 表示使用更大的数据集进行训练。


Transformer Based Models

论文标题:
On the Importance of Local Information in Transformer Based Models
论文链接:
https://arxiv.org/abs/2008.05828
目前已经有很多文章研究多头注意力机制取得成功的本质原因,他们有一些共性的发现:少部分关注于局部信息或者语义信息的注意力比其他 head 更加重要。本文是一篇实验性的文章,旨在在这个观察下更进一步,文章得到的结论也很振奋:即使我们只保留局部注意力,transformer 的性能依旧不会收到影响。
2.1 Analysis of Locality in Transformerbased models
这一节主要论证了局部信息在当前基于 transformer 的模型中起到的重要性。文章针对两组任务分别选择了两个基准模型
针对机器翻译任务,选择了 Transformer (标准的 transformer)作为基准模型,用在 WMT'14 的 En-Ru 和 En-De 两个翻译任务上。
针对自然语言理解任务,选择 作为基准模型,用在 QQP, SST-2, MRPC, QNLI 四个数据集上。
2.2 Sensitivity analysis
作者首先使用梯度评估重要程度,使用如下三个公式度量局部,语义和无关信息在传统模型中所占比重。 指的是输出 对输入 的梯度(梯度越大对结果的影响也越大,即对该位置比较敏感)。 指的是在第 i 个 token 附近距离小于 2 的 token 集合。
表示与第 i 个 token 有语义关系的 token 集合, 表示其他。以对局部信息重要性的度量为例,其实就是对每个 token,求出他临近位置 4 个 token 的重要性的均值,然后在整个 sequence 上求均值。

我们随机在数据集中抽取 100 个句子然后计算上面的指标,可以看到,基本上在所有数据集上局部信息的重要性都是 dominant 的。这也就证实了每一层的输出对他的局部信息都要更为敏感。

除了梯度外,作者也通过注意力权重来评估了局部信息的重要性。评估方式如下 l:给定一整段 sentence 和其中一组 token 集合 , 表示计算第 i 个 token 的表示时对位置 j 的 token 的注意力权重,那么我们说一个 token 对 的注意力偏向比为:

如果 取上述的 ,那么我们就评估的是 model 对局部信息的注意力偏向程度,结果如下图所示,我们知道一个完全随机初始化的 transformer 他的偏向比应该为 1。下图的横坐标表示这个比例,纵坐标显示了注意力偏向比大于该阈值的 head 占总体 head 的数目,可以看到非常多的 head 对局部信息有偏向。

那么我们不妨大胆一点,如果我们强制让所有的注意力头都学习局部信息会怎样呢?
2.3 Transformers With Only Local Attention
文章通过两个设计来 enforce 这个目标。
2.4 Applying Masks to Attention Heads
最简单的方式就是给原本计算好的 attention map 乘上一个 mask,文中提出了好几种 mask 的方式,无非就是限制一定距离内的 token 的注意力权重不变,其他的置为 0。虽然这样的手段引入了归纳偏置,减小了感受野,但是因为 encoder 也是多层的,所有最终还是可以建模长距离依赖(参考 CNN)。

2.5 Parameter Sharing Across Heads
第二种方式称为参数共享,也就是说我们能否在多个注意力头中共享 ,但是给他们选择不同的 mask,从而得到不同的激活结果。这里也有很多的问题值得讨论:
1. 如何给每个注意力头选择合适的 mask?
2. 哪些注意力头需要共享参数?
显然,参数共享可以使得我们的参数量大大下降,但是这对我们的性能有什么影响呢,实验部分会一一展开。
2.6 Results and Discussions
2.6.1 Intermixing Global and Local AttentionHeads
在第一个实验中,作者尝试了将传统 attention 和完全局部的 attention 进行组合来观察,一共有六种组合方式。如下图(a-f)所示。
(a)就是传统 transformer 没变,(b)称之为 2locHeads_All6(6 个 encoder 换 2 个位局部头,这里应该是笔误,一共 8 个 head),(d)称之为 8LocaHeads_First3(前三层全部换为局部头,同样笔误。

效果感人,即使全部用局部头,性能也并没有下降多少,甚至在 EN-DE 这里还有所上升。

2.6.2 Parameter Sharing Within Layer
共享参数作者一共实现了四种方式,对应图四 (g-j),图中淡蓝色 head 共享其左侧深蓝色 head 的 query,key 参数矩阵。称(g)为 4LocHeads4TiedLocAll6 (其余类推)。结果既然很惊艳,我们可以发现掉点其实很少,甚至在有些 setting 下还有所提升。

2.6.3 Parameter Sharing Across Layers
这一步做得更绝,整层 attention 都共享参数,或者说一半的 attention 共享参数,一般为原始。Again,效果基本不降甚至有所提升。

总结一下,这篇文章最突出的地方在于验证了 局部注意力在翻译以自然语言理解任务上的有效性,除此之外,还验证了参数共享的可行性。

Longformer

论文标题:
Longformer: The Long-Document Transformer
论文链接:
https://arxiv.org/abs/2004.05150
代码链接:
https://github.com/allenai/longformer
本文最大的亮点就在于:attention 机制对内存与算力的需求与序列长度呈线性关系,而不是原有的二次方。而且作者给出了不同的实现方式,在速度方面有些许的差异。

3.1 Background
我们知道,对 attention 机制进行改进的文章已经很多了,对长序列而言最暴力的就是我们只用它开头的 个 token 强行处理,但是这样显然会丢失非常多的信息。
目前主要有如下两种方式进行改进(i)ltr: left-to-right,我们从左到右依次处理小块的 token,这种方式使得它在需要双向信息的任务上表现不佳。
本文属于第二种类型(ii)不去计算整个注意力矩阵,使其稀疏化。但是从下图可以看到,作者 argue 他们的实验都不完善,大多数只在 LM 的任务上进行验证,作者做了 LM, 其他常见 NLP 的 tasks,还将模型进行预训练然后微调再进行做对比。

3.2 LongFormer
文中给出了三种线性复杂度的 attention 实现方案:

1. (b) 滑动窗口为 即每一个 token 左右各取 个 token 计算局部注意力。假设窗口大小是 w,序列长度是 n,那么这个 pattern 的计算复杂度就是 。有点像卷积,多层堆叠同样能得到较大的感受野。
2. (c) 窗口的缝隙大小是 (每两个 window之间距离为 ),假设 window size 是 ,transformer 的层数是 ,那么窗口能覆盖到的接受范围就是 。在 mutilhead attention 中,作者设置允许一些没有空洞的 head 专注于局部上下文,而其他具有空洞的 head 专注于较长的上下文,最终发现这样的做法能提升整体的表现。
3. (d) 对于一些任务,比如说 QA,需要通过 question 去找 document 里的答案,因此局部注意力在这种情况下就不适用。因此,作者就在一些预先选择的位置上添加了全局注意力。在这些位置上,会对整个序列做 attention。这些位置根据具体任务而定,比如在分类任务上,这个 global attention 就落在 [CLS] 标签上,在 QA 任务上,就在整个问句上计算 global attention。global attention 是视具体任务而定的,显然是引入了 inductive bias,换个任务可能之前的做法就不适用了,但作者认为,这仍然比现有的 trunk 或者 shorten 的做法要简单很多。
3.3 Experiments
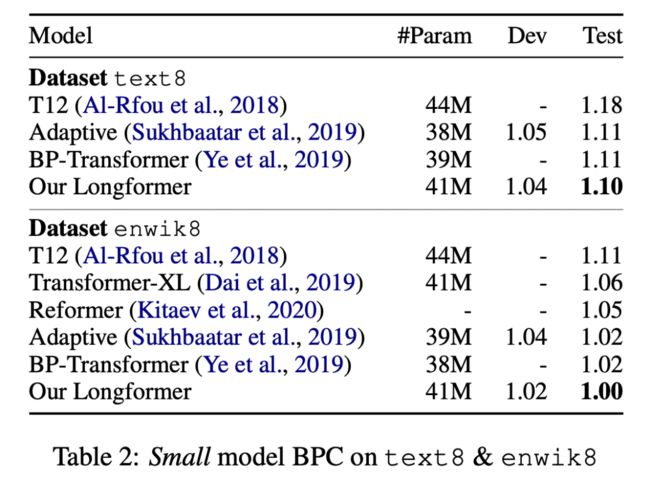
对于 LM 任务,作者选择了 text8 和 enwik8 两个数据集,在小的模型上,long former 比其他模型都要好。这也证明了这个模型的有效性。在大的模型上,比 18 层的 transformerxl 要好,跟第二个和第三个齐平,不如第四、五两个。但作者说明,这两个模型并不适用于 pretrain-finetune 的模式。

首先来看一下这几种不同的 attention paradigm 效果如何,如下图所示递增窗口大小的表现最好,递减窗口大小表现最差,使用固定窗口的表现介于两者之间。表格的下半部分展示了使不使用空洞窗口的区别,可以看出对两个 head 增加一些空洞比完全不使用空洞窗口表现要好一些。

作者从 RoBERTa 的 checkpoints 开始进行训练,具体实施就不贴了,最终再 NLP 的多种 task 上都击败了前者。


Big Bird

论文标题:
Big Bird: Transformers for Longer Sequences
收录会议:
NeurIPS 2020
论文链接:
https://arxiv.org/abs/2007.14062
代码链接:
https://github.com/google-research/bigbird
当 graph 遇到 attention 会发生什么?这篇文章将注意力机制使用图来建模,然后使用图上的稀疏化技术将注意力机制的时空复杂度与输入序列长度的依赖降到线性,与以往的工作不同,本文还给出了理论上的支撑。
4.1 BIG BIRD架构
往简单来说,big bird 的注意力机制主要包含三部分:

个可以做全局注意力的 token(c)
所有的 token 可以访问其两边长度为 的窗口内的所有 token(b)
所有 token 可以访问任意 个随机位置的 token(a)
我们都可以从直观上想到这样的方法,那有没有一些观察告诉我们为什么选择这些方式呢?这就不得不说 big bird 有趣的建模了。
给定输入序列 ,我们可以用图来描述一个注意力机制。这个图的点即序列中的每个 token,因此点集 ,图中的边其实就是 attention weight,用 表示 token 可以访问的所有 token 的集合,那么 经过 attention 之后的输出我们可以定义为:

其中 是注意力头的数目, 即我们注意力机制的参数矩阵。 是 softmax 或者 hardmax。注意到这里计算 key 的集合 并不是全体 token,而是 可以访问的邻居节点。
对一个图,我们可以用邻接矩阵 来表示每个点的连接状况,当 是全一矩阵的时候其实这就是传统的 attention。使用图的方式对注意力机制进行建模允许我们图上稀疏化的方法来优化这一过程,接下来我们挨个本文为什么需要上述三种局部信息的获取方式:
1. 随机图可以在很多不同情况下近似完全图,而且它邻接矩阵的二阶特征值比一阶特征值小得多,这个性质表明信息可以在任何一对节点之间快速流动。根据这一理论,作者也提出了一种完全随机的稀疏关注,即一个 query 可以随机的访问 个任意位置的 key。
2. 现在 NLP 社区越来越多的人关注局部性这一性质,基于固定窗口的 attention 上文也讲过,不过作者给出了局部性,相邻节点在语言学,图中的重要性。
3. 全局注意力的重要性是作者从理论分析中得到的,这里作者使用了两种方法指定一部分 token 做全局注意力:1) internal transformer construction (ITC):在所有 token 中随机的选一个子集 ,允许他们访问其他所有 token;2) extended transformer construction (ETC):像 BERT 一样手工添加 个类似于 CLS 这样的 token 用于获取全局信息。
理论部分比较长,这里就不列出来了。
4.2 Experiments
本文同样创建了 base,large 两个版本的模型,从 RoBERTa 的 checkpoint 开始进行预训练。
在 QA 数据集上,big bird_base 超过相应的 base model:Roberta 以及 longformer,只是 ITC 和 ETC 两种产生全局 token 的方式各有强弱。

虽然作者将 BIGBIRD-ETC 与当前以下数据集的 top 3 进行了比较:

计算效率的上升意味着处理长文本的能力得以增强,这类应用最典型的就要属 Summarization了。可以看到,在各个数据集上 Big Bird 都取得了巨大的性能提升。

总结一下,越来越多的文章聚焦在局部/全局信息的 tradeoff 上,虽然大家得出的结论不全相同,但是如何更好地利用 attention map 的稀疏性来提高计算和存储效率依然是一个热点问题。随着 transformer 应用在 image 上,这个问题变得更加多样化。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
