【动手学深度学习v2李沐】学习笔记05:多层感知机、详细代码实现
前文回顾:Softmax回归、损失函数、图片分类数据集、详细代码实现
文章目录
- 一、感知机
-
- 1.1 单层感知机
- 1.2 训练感知机
- 1.3 收敛定理
- 1.4 XOR问题
- 1.5 总结
- 二、多层感知机
-
- 2.1 解决XOR问题
- 2.2 激活函数
-
- 2.2.1 Sigmoid激活函数
- 2.2.2 Tanh激活函数
- 2.2.3 ReLU激活函数
- 2.3 单隐藏层
-
- 2.3.1 单分类问题
- 2.3.2 多分类问题
- 2.4 多隐藏层
- 2.5 总结
- 三、代码实现
-
- 3.1 从零开始实现
-
- 3.1.1 导入库和加载数据集
- 3.1.2 单隐藏层多层感知机
- 3.1.3 激活函数
- 3.1.4 模型和损失函数
- 3.1.5 训练
- 3.2 简洁实现
-
- 3.2.1 导入库
- 3.2.2 模型
- 3.2.3 训练
一、感知机
1.1 单层感知机
给定输入 x ⃗ \vec{x} x,权重 w ⃗ \vec{w} w和偏移 b b b,感知机输出:
o = σ ( ⟨ w ⃗ , x ⃗ ⟩ + b ) σ ( x ) = { 1 x > 0 0 o t h e r w i s e o=\sigma(\langle \vec{w}, \vec{x} \rangle + b) \qquad \qquad \sigma(x)=\begin{cases}1 \quad x > 0 \\ 0 \quad otherwise\end{cases} o=σ(⟨w,x⟩+b)σ(x)={1x>00otherwise

单层感知机实际是个二分类的问题,返回-1或者是1。
1.2 训练感知机
训练感知机的伪代码:
initialize w = 0 w=0 w=0 and b = 0 b=0 b=0
repeat
\qquad if y i [ ⟨ w , x i ⟩ + b ] ≤ 0 y_i[\langle w, x_i \rangle + b] \leq 0 yi[⟨w,xi⟩+b]≤0 then
\qquad w ← w + y i x i \qquad w\leftarrow w+y_ix_i w←w+yixi and b ← b + y i b\leftarrow b + y_i b←b+yi
\qquad end if
until all classified correctly
上述伪代码中的 y i [ ⟨ w , x i ⟩ + b ] ≤ 0 y_i[\langle w, x_i \rangle + b] \leq 0 yi[⟨w,xi⟩+b]≤0 ,是在判断真实值与预测值的乘积是否为正数:若为正数,说明预测正确;若为负数,说明预测错误,需要修改参数。这里实际上是个同或问题。感知机会不断进行这样的判断,并且不断地更新参数,直至对所有的类别均预测正确。
这段伪代码等价于使用批量大小为1的梯度下降,并使用如下的损失函数:
l ( y , x ⃗ , w ⃗ ) = m a x ( 0 , − y ⟨ w ⃗ , x ⃗ ⟩ ) l(y, \vec{x}, \vec{w})=max(0, -y \langle \vec{w}, \vec{x} \rangle) l(y,x,w)=max(0,−y⟨w,x⟩)
1.3 收敛定理
- 我们假设所有数据都在半径 r r r 内
- 假设可以用余量 ρ \rho ρ 将所有的数据分类成两类
y ( x ⃗ T w ⃗ + b ) ≥ ρ y(\vec{x}^T\vec{w} + b)\geq \rho y(xTw+b)≥ρ对于 ∣ ∣ w ⃗ ∣ ∣ 2 + b 2 ≤ 1 ||\vec{w}||^2+b^2 \leq 1 ∣∣w∣∣2+b2≤1 - 感知机保证在 r 2 + 1 ρ 2 \frac{r^2+1}{\rho ^2} ρ2r2+1 步后收敛。
1.4 XOR问题
感知机不能拟合XOR函数,它只能产生线性分割面。
由于感知机是一个线性模型,当两个不同类别的数据分布呈现异或的特征时,感知机无法对其进行分类。

1.5 总结
- 感知机是一个二分类问题,是最早的AI模型之一。
- 它的求解算法等价于使用批量大小为1的梯度下降。
- 它不能拟合XOR函数,导致第一次AI寒冬。
二、多层感知机
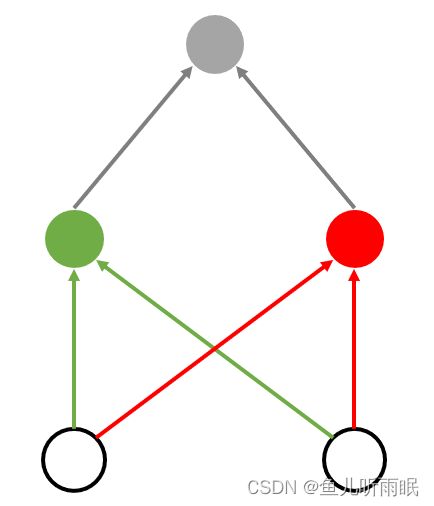
2.1 解决XOR问题
我们可以通过分多步来解决XOR问题,如下例所示。
- 首先,我们通过对x是否大于0训练绿色的线。
- 之后再通过对y是否大于0来训练红色的线。
- 最后,我们对两次训练的结果进行同或运算。

| 步骤\点 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 绿色线 | + | - | + | - |
| 红色线 | + | + | - | - |
| 同或 | + | - | - | + |
有了绿色分类器和红色分类器,我们就可以解决XOR问题了。上例中的分类器可以表示为由绿色分类器、红色分类器和同或分类器构成的多层分类器:
2.2 激活函数
2.2.1 Sigmoid激活函数
Sigmoid函数会将输入投影到 ( 0 , 1 ) (0, 1) (0,1) 区间之中,它可以看做是软的 σ ( x ) = { 1 x > 0 0 o t h e r w i s e \sigma (x) = \begin{cases}1 \qquad x > 0 \\ 0 \qquad otherwise \end{cases} σ(x)={1x>00otherwise
s i g m i o d ( x ) = 1 1 + e − x sigmiod(x) = \frac{1}{1+e^{-x}} sigmiod(x)=1+e−x1
2.2.2 Tanh激活函数
这个函数和Sigmoid函数很像,区别是Tanh函数将输入投影到 ( − 1 , 1 ) (-1, 1) (−1,1) 区间中:
t a n h ( x ) = 1 − e − 2 x 1 + e − 2 x tanh(x)=\frac{1-e^{-2x}}{1+e^{-2x}} tanh(x)=1+e−2x1−e−2x
2.2.3 ReLU激活函数
ReLU激活函数是个很常用的函数:
R e L U ( x ) = max ( x , 0 ) ReLU(x) = \max (x, 0) ReLU(x)=max(x,0)
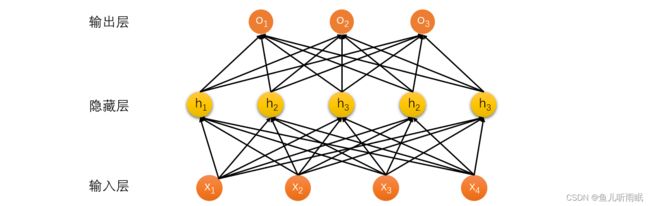
2.3 单隐藏层
多层感知机相当于加入了一个隐藏层的网络,隐藏层大小是超参数。
2.3.1 单分类问题
对于单分类问题,多层感知机的网络模型如下:
- 输入: x ⃗ ∈ R n \vec{x} \in R^n x∈Rn
- 隐藏层: W 1 ∈ R m × n , b ⃗ 1 ∈ R m W_1 \in R^{m \times n}, \quad \vec{b}_1 \in R^m W1∈Rm×n,b1∈Rm
- 输出层: w ⃗ 2 ∈ R m , b 2 ∈ R \vec{w}_2 \in R^m, \quad b_2 \in R w2∈Rm,b2∈R
该模型相当于输入 x ⃗ \vec{x} x 经过线性变换与激活函数 σ ( ) \sigma () σ() 转变为隐藏层的 h ⃗ \vec{h} h。之后,又经过一个线性变换从输出层输出。
h ⃗ = σ ( W 1 x ⃗ + b ⃗ 1 ) o = w ⃗ 2 T h ⃗ + b 2 \vec{h}=\sigma (W_1\vec{x} + \vec{b}_1) \\ o=\vec{w}_2^T \vec{h} + b_2 h=σ(W1x+b1)o=w2Th+b2这里, σ \sigma σ 是按元素的激活函数。
问题: 为什么需要非线性激活函数?
我们假设激活函数为线性函数: σ ( x ) = x \sigma (x)=x σ(x)=x
网络模型变为:
h ⃗ = W 1 x ⃗ + b ⃗ 1 o = w ⃗ 2 T h ⃗ + b 2 \vec{h}=W_1\vec{x} + \vec{b}_1 \\ o=\vec{w}_2^T \vec{h} + b_2 h=W1x+b1o=w2Th+b2 则输出将会变为: o = w ⃗ 2 T W 1 x ⃗ + b ′ o = \vec{w}_2^T W_1 \vec{x} + b' o=w2TW1x+b′
此时,输出 o o o 仍然为线性函数,模型仍然是个线性模型。该感知机仍然等于单层感知机。
2.3.2 多分类问题
多层感知机解决多类分类问题相当于在Softmax回归的基础上,增加了一层隐藏层。
网络模型如下:
- 输入: x ⃗ ∈ R n \vec{x} \in R^n x∈Rn
- 隐藏层: W 1 ∈ R m × n , b ⃗ 1 ∈ R m W_1 \in R^{m \times n}, \vec{b}_1 \in R^m W1∈Rm×n,b1∈Rm
- 输出层: W 2 ∈ R m × k , b ⃗ 2 ∈ R k W_2 \in R^{m \times k}, \vec{b}_2 \in R^k W2∈Rm×k,b2∈Rk
h ⃗ = σ ( W 1 x ⃗ + b ⃗ 1 ) o ⃗ = W 2 T h ⃗ + b ⃗ 2 y ⃗ = s o f t m a x ( o ⃗ ) \vec{h}=\sigma (W_1 \vec{x} + \vec{b}_1) \\ \vec{o}=W_2^T \vec{h} + \vec{b}_2 \\ \vec{y} = \mathop{softmax}(\vec{o}) h=σ(W1x+b1)o=W2Th+b2y=softmax(o)
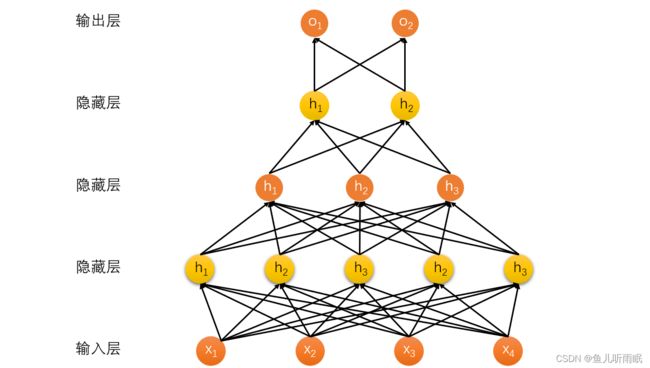
2.4 多隐藏层
我们在单隐藏层模型的基础上可以构造多隐藏层模型。例如:
h ⃗ 1 = σ ( W 1 x ⃗ + b ⃗ 1 ) h ⃗ 2 = σ ( W 2 h ⃗ 1 ⃗ + b ⃗ 2 ) h ⃗ 3 = σ ( W 3 h ⃗ 2 ⃗ + b ⃗ 3 ) o ⃗ = W 4 h ⃗ 3 + b ⃗ 4 \vec{h}_1 = \sigma (W_1 \vec{x} + \vec{b}_1) \\ \vec{h}_2 = \sigma (W_2 \vec{\vec{h}_1} + \vec{b}_2) \\ \vec{h}_3 = \sigma (W_3 \vec{\vec{h}_2} + \vec{b}_3) \\ \vec{o} = W_4 \vec{h}_3 + \vec{b}_4 h1=σ(W1x+b1)h2=σ(W2h1+b2)h3=σ(W3h2+b3)o=W4h3+b4多隐藏层的每一层都有一个激活函数 σ ( ) \sigma () σ() 和一个偏移 b i b_i bi
多隐藏层的超参数有:
- 隐藏层数
- 每层隐藏层的大小
输入数据的复杂度应当和模型的复杂度相匹配。如果输入数据比较复杂,我们有两个选择:
- 采用单隐藏层,并且设置比较大的隐藏层大小。
- 采用多隐藏层,采用较小的隐藏层大小以及更深层次的网络。
2.5 总结
- 多层感知机使用隐藏层和激活函数来得到非线性模型。
- 常用激活函数是Sigmoid、Tanh和ReLU。
- 使用Softmax来处理多类分类问题。
- 超参数为隐藏层数和各隐藏层大小。
三、代码实现
3.1 从零开始实现
3.1.1 导入库和加载数据集
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
3.1.2 单隐藏层多层感知机
我们实现一个具有单隐藏层的多层感知机,它处理的输入数据大小为784,输出为10个类别,包含256个隐藏单元。我们将每一层的权重随机初始化,并将偏移初始化为0。
# 实现一个多层感知机
# 输入 输出 隐藏层
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True))
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True))
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
3.1.3 激活函数
我们实现ReLU激活函数
# 实现ReLU激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
3.1.4 模型和损失函数
实现我们的模型以及损失函数
# 实现我们的模型
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ W1 + b1) # 这里的@是矩阵乘法,相当于matmul()
return (H @ W2 + b2)
# 损失函数
loss = nn.CrossEntropyLoss(reduction='none')
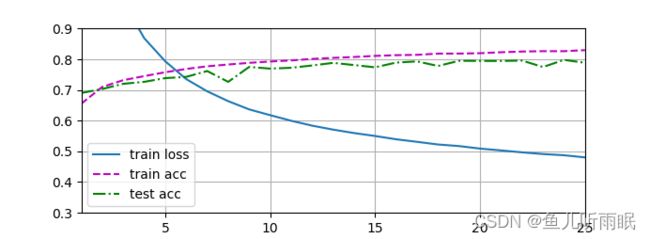
3.1.5 训练
多层感知机的训练过程与softmax回归的训练过程完全相同。
# 训练过程
num_epochs, lr = 25, 0.2
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
训练结果如下图所示:
3.2 简洁实现
3.2.1 导入库
import torch
from torch import nn
from d2l import torch as d2l
3.2.2 模型
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
net.apply(init_weights)
3.2.3 训练
# 训练过程
batch_size, lr, nums_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, nums_epochs, updater=trainer)
训练的结果如下图所示:

下一篇:【动手学深度学习v2李沐】学习笔记06:模型选择、欠拟合和过拟合、代码实现