matlab三维体绘制,基于GPU的医学图像三维重建体绘制技术综述
1 前言
随着医学图像三维重建体绘制技术的发展及其研究的深入,医生对数据的分析不再局限于简单的观察输出结果,还要求能对结果进行友好交互,使最终结果更能满足其特定的观察需求。然而由于医学数据通常较大,对所有数据的重建和交互计算量非常大,目前能达到重建速度快、重建效果好、交互流畅的技术一般都是在专业的图形工作站上实现。但这些设备通常较为昂贵,一定程度上阻碍了三维重建体绘制技术在医学领域的普及。最近几年随着图形处理器GPU(Graphics Processing Unit)的高速发展,普通PC(Personal Computer)图形硬件可编程性能得到很大提高,具有可编程管线的GPU可灵活实现各种图形算法,进行硬件加速。因此利用图形硬件可编程单元对体绘制算法进行加速处理,已成为体绘制研究的一个热点。
2 体绘制技术
体绘制方法是指直接将体数据中的体素投影到屏幕上,其相对于面绘制的最大区别就是体绘制时体数据中的全部体素都参与了最终图像的渲染,体数据是对局部空间内的数据进行采样,这些采样值代表这个点上一个或多个物理特性。一般数据场空间都是以有限多个采样来描述,所以体数据包含物体内部的信息是真正的三维实体。
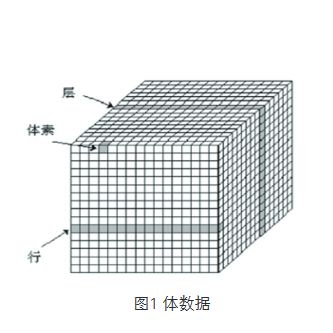
通常情况下,在逻辑上体数据表示为一个三维的数组空间(见图1),在图中每个元素称为体素,体素也是体数据最小的单位,每个体素都在图中对应着相应的行号、列号和层号。因为是规则数据场,所以认为所有体数据都是平均分布在x,y,z三个方向上,体素之间的距离是相等的。
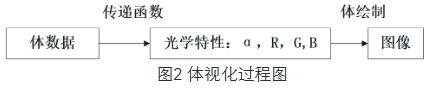
如图2所示,传递函数的设计是体绘制算法的关键步骤之一,传递函数的功能是将一个体数据映射成颜色、不透明度等光学属性或映射成Phong光照模型的ka、kd、ks等光学模型参数。
注意:上图图2中的的传递函数是十分重要的一步,因为在直接体绘制中,需要通过传递函数将三维数据的采样点映射成光学参数。传递函数的选择直接决定了绘制的效果,成为体绘制研究的关键。
然而传递函数的设计比较复杂,现有的算法存在盲目性、用户界面不直观、参数调节复杂等问题。近来对传递函数的研究进展包括高维传递函数,基于特征的传递函数等方法的提出,用于更有效地提高绘制的效果。近来非真实感绘制(Non-photorealistic Rendering)的方法也被用于体绘制。
这类方法通过边界增强(Boundary Enhancement),剪影(Silhouettes),网点模式(Stipple Patterns)等方法,强调关注的特征,利用艺术化的方法,获得特殊的可视化效果。
因为在整个体绘制过程中一直用到不透明度和颜色值,所以如何设计高性能的传递函数也是三维重建研究的主要问题之一。
体绘制的算法很多,具体实现过程也有所区别,但其基本流程大致相同,包括体数据的预处理、分类光照及最终的图像合成(见图3)。

直接体绘制的代表算法主要包括:
①光线投射法(Ray Casting);
②最大强度投影算法(Maximum Intensity Projection);
③抛雪球法(Splatting);
④剪切曲变法(Shear-Warp)等。
2.1 光线投射法(Ray Casting)
其中光线投射法(Ray Casting)是图像空间的经典绘制算法,它从投影平面的每个点发出投射光线,穿过三维数据场,通过光线方程计算衰减后的光线强度并绘制成图像。其绘制质量最高,但速度较慢。
2.2 最大强度投影算法(Maximum Intensity Projection, MIP)
最大强度投影算法(Maximum Intensity Projection, MIP)将数据场内沿着视线方向上的采样的最大值作为绘制图像相应位置处的像素值,主要用于对体数据中高灰度值的结构进行可视化,常用于CT或MRI图像的可视化。通常最大强度投影算法不计算明暗信息和深度信息,从而导致难以区分投影方向,消除这类错觉的通用办法是动画显示,在观察过程中动态改变视角。
2.3 抛雪球法(Splatting)
抛雪球法(Splatting)也被称为足迹表法(Footprint Method),它模仿了雪球被抛到墙壁上所留下的扩散状痕迹的现象。该方法以物体空间为序,计算每一体素投影的高斯函数定义强度分布的影响范围(即足迹,Footprint),并加以合成,形成最后的图像。该方法可以只选取与图像相关的体素进行投射和显示,减少体数据的存取数量,且适合并行操作。
2.4 剪切曲变法(Shear-Warp)
剪切曲变法(Shear-Warp)由Cameron和Undrill最先提出,经P. Lacroute和M. Levoy推广,原理是将三维数据场的投影变换分解为①三维数据场平行于切面方向的错切(Shear)变换和②二维图像的曲变(Warp)这两步来实现,从而将三维空间的重采样过程转换为二维平面的过程,大大减少了计算量,目前被认为是CPU上速度最快的一种体绘制算法。在预处理时,体素经过不透明度分类和编码,可以在遍历体素和图像的同时略去不透明的图像区域和透明的体素,进一步提高效率。
提高体绘制效率的原则是尽量减少不必要的体素渲染数量。近来发展的技术包括体绘制空区间跳跃(Empty Space Skipping),早期光线终止(Early Ray Termination),八叉树和BSP空间分割(Octree and BSP Space Subdivision),自适应多分辨率(Multiple and Adaptive Resolution),预积分体绘制(Pre-integrated Volume Rendering)等。目前的直接体绘制广泛地采用了图形硬件加速,将三维体数据场中的数值(以及对应的颜色值或光照强度)视作纹理,装载入容量足够大的图形硬件内存,利用硬件实现线性插值及图像合成的并行运算,从而提高体绘制效率。早期的图形硬件只支持二维纹理,因此相应的硬件加速体绘制算法相当于二维纹理切片的堆栈合成,采样时利用二维纹理的双线性插值。这类方法需要在三个坐标方向建立三个对应的片层堆栈。进行绘制时,选择与观察方向最垂直的那个片层堆栈以获得好的绘制质量。这种方法内存消耗大,采样困难,而且由于缺乏层间插值导致绘制图像的质量不高。基于图形硬件三维纹理功能的体绘制技术,主要利用硬件的三线性过滤插值能力,通过渲染许多个与视线垂直的面片来重建整个三维结构,每个面片利用三维纹理来决定颜色与透明度。这种方法得到的效果从本质上讲与光线投射的效果相同。更新的方法可以直接利用三维纹理在图形硬件上实现光线投射的算法。
3 GPU简介
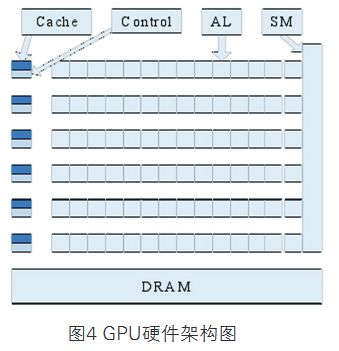
图形处理器芯片、显示芯片和图像处理芯片都可以称为图形处理器(GPU)(见图4),是计算机硬件中显卡的关键部件,其好坏直接影响显卡的性能和档次。过去几年,GPU以大大超过摩尔定律的速度高速发展,极大提高了计算机图形处理的速度和质量,不但促进了图像处理、虚拟现实、计算机仿真等相关应用领域的快速发展,也为人们利用GPU进行图形处理以外的通用计算提供了良好的运算平台。
3.1 GPU计算的优点
高效的并行性。这一功能主要是通过GPU多条绘制流水线的并行计算来体现。在目前主流的GPU中,多条流水线既可在单一控制部件的集中控制下运行,也可独立运行。GPU的顶点处理流水线使用MIMD方式控制,片段处理流水线使用SIMD结构。相对于并行机而言,GPU提供的并行性在十分廉价的基础上为很多适合在GPU上进行处理的应用提供了很好的并行方案。高密集的运算。GPU通常具有较大内存位宽,因此在计算密集型应用方面具有很好的性能。完善的图形流水线。GPU图形流水线的设计以吞吐量的最大化为目标,因此作为数据流并行处理机,在对大规模的数据流并行处理方面具有明显优势。
3.2 GPU的工作原理
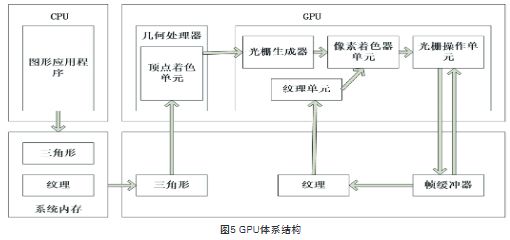
高效的并行性、高密集的运算能力和完善的图形流水线是GPU的优势,尤其高度并行运算能力和快速浮点运算能力是GPU的显著特征。这些特征是由其内部微架构决定的(见图5),GPU在计算时可以将数据分成若干独立的模块,这些模块内部的数据没有逻辑上的关系,每个模块可以独立进行运算,形成大量运算的线程。不同型号的GPU内部有不同数量各自独立的单元,每个单元都能独立处理数据,这些单元使GPU具有并行运算的特征。
4 一种基于GPU的体绘制技术
目前常用的体绘制算法有很多,主要包括光线投影算法、错切变形法、基于硬件3D纹理映射算法等,其中以光线投影算法最为经典,也是最常用的算法。本文主要阐述一种基于GPU的光线投影算法,其计算流程如下(见图6)。
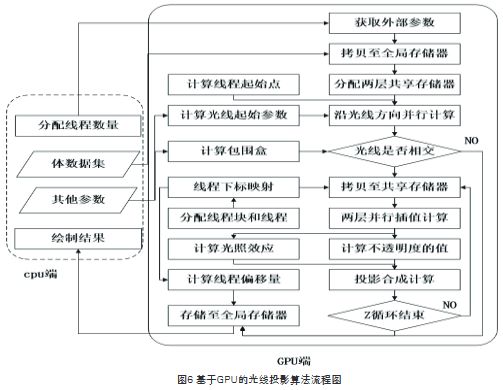
步骤1:计算投影方向上体数据的包围盒,并把体数据由内存拷至全局存储器。
步骤2:按照投影空间大小分配线程,将体数据集分割为若干线程块,每一线程块包含若干线程。建立线程和光线投射方程之间的映射关系,其中每一个线程将沿一条光线路径进行合成计算。
步骤3:沿光线方向循环进行合成计算,其中每一条光线将在独立线程下并行处理。每次循环时,在每个线程块内部分配两个二维共享存储器,分别存储当前层和下一层的数据。首先判断光线是否穿过物体,如是则将两层体数据从全局存储器拷贝到共享存储器,然后使用三线性插值计算出两层数据间所需的采样值,并将其值代入数据场分类函数中计算出该点的不透明度。最后,根据光线投射方程进行合成计算。
步骤4:根据映射关系将生成的数据存储至图像空间的全局存储器,拷贝回内存并进行显示。
5 总结与展望
GPU是专门为图形而诞生的处理器,拥有独特的存储结构和数据存取方式。其高度并行的计算能力以及与CPU相比价格方面的合理性,使得GPU在医学图像三维重建方面有很大的用武之地。目前,基于GPU的体绘制算法能很好地提高重建的速度和质量,在实现实时渲染方面也有很好的效果。但是与此同时,由于体绘制光线投影绘制算法具有生成图像质量高计算量大的特点,即使采用了高性能的GPU进行硬件加速优化,在体数据规模较大时仍难以取得较好的实时性,所以后期还需要各种软件加速的方法去优化性能,在加速方法的选择以及传递函数的设计方面都有待进一步研究。