从EM算法到高斯混合模型(GMM)与K-means算法(理论分析+仿真分析)
目录:
- EM算法
- GMM模型
- K-means算法
EM算法
基本问题
首先介绍一下EM算法要解决的基本问题。EM算法通常解决的是不同分布下的参数估计问题,属于参数估计理论的一种。在另一个角度,EM算法也可以看作是极大似然估计的加强版。
由于极大似然估计要求采样数据属于同一个分布,因为只能估计同一个分布下的参数。
举个例子:在学校随机地选取100个男生,可以通过极大似然估计来得到男生的平均身高。倘若随机选取100个未知性别的学生(有男有女),这时,这100个人的平均身高既不代表男生也不代表女生。
此时,正确地做法应该是先把女生和男生分开,然后分别用极大似然估计,最后分别得到了男生和女生的平均身高。
数学描述
若样本 X = { X 1 , X 2 . . . . X n } X=\{X_1,X_2....X_n \} X={X1,X2....Xn},一共有 N N N个不同的样本,其中样本 X i X_i Xi属于 K ( k = 1 , 2... K ) K(k=1,2...K) K(k=1,2...K)个不同的分布。即 X i ∼ p ( x ∣ θ k ) X_i \sim p(x|\theta_k) Xi∼p(x∣θk), X i X_i Xi是从第 k k k个分布里面抽取出来的样本。现在的问题是需要得到 p ( x ∣ θ k ) p(x|\theta_k) p(x∣θk)。下面就是EM算法要解决的问题了,做法很简单,思想确实很精巧。
1.极大似然估计
EM算法还是从极大似然出发的,前面说过,这玩意就是极大似然的加强版本。首先写出样本 X = { X 1 , X 2 . . . . X n } X=\{X_1,X_2....X_n \} X={X1,X2....Xn}的似然函数:
L ( θ ) = ∏ i = 1 N p ( x i ∣ θ k ) (1) L(\theta)=\prod_{i=1}^Np(x_i|\theta_k)\tag{1} L(θ)=i=1∏Np(xi∣θk)(1)
观察 ( 1 ) (1) (1)式子可以看出似然函数中含有 θ k \theta_k θk, k k k是未知的,所以这里引入一个叫隐变量的东西。首先隐变量有几个特点(个人理解):
- 隐变量是一个随机变量
- 每个样本 X i X_i Xi都对应一个隐变量值 Z j Z_j Zj,但是不意味隐变量可以取 N N N个值,同一分布内(同一类)的样本对应隐变量的值是一样的。
- 隐变量描述的是 X i X_i Xi归属于哪个分布的现象。
主要解释一下后面两点,想想最开始提到的100个学生,其实每个学生我们不仅仅能测量他的身高,我们还应该知道他的性别。所以,完整地描述一个人的身高应该是 ( X i , Z j ) (X_i,Z_j) (Xi,Zj),前者表示升高,后者表示性别。
利用隐变量,对 ( 1 ) (1) (1)式进行改写:
L ( θ ) = ∏ i = 1 N ∑ k = 1 K p ( x i ∣ θ k ) (2) L(\theta)=\prod_{i=1}^N \sum_{k=1}^Kp(x_i|\theta_k)\tag{2} L(θ)=i=1∏Nk=1∑Kp(xi∣θk)(2)
这里的解释是既然不知道每个样本 X i X_i Xi所对应的分布 p ( x ∣ θ k ) p(x|\theta_k) p(x∣θk),那么干脆下面主要处理
X i ∼ ∑ k = 1 K p ( x i ∣ θ k ) X_i\sim\sum_{k=1}^Kp(x_i|\theta_k) Xi∼k=1∑Kp(xi∣θk)
这个其实是代表这每个分布都对 X i X_i Xi有贡献,只是大小不一样,那么就直接求和取最大就好了。
对 ( 2 ) (2) (2)式取对数,有:
l o g [ L ( θ ) ] = ∑ i = 1 N l o g ∑ k = 1 K p ( x i ∣ θ k ) (3) log[L(\theta)]=\sum_{i=1}^N log\sum_{k=1}^Kp(x_i|\theta_k)\tag{3} log[L(θ)]=i=1∑Nlogk=1∑Kp(xi∣θk)(3)
按照极大似然的做法,接下来要对 ( 3 ) (3) (3)式求导了,由于对数内求和再求导,将会无比复杂,所以不能求导。这里需要用到一个不等式。
2.琴声不等式
对于一个凹函数有以下不等式成立:
f ( E ( x ) ) ≥ E ( f ( x ) ) f(E(x))\ge E(f(x)) f(E(x))≥E(f(x))
如果 x x x是离散的随机变量,那么有:
f ( ∑ x p ( x ) ) ≥ ∑ f ( x ) p ( x ) f(\sum xp(x))\ge \sum f(x)p(x) f(∑xp(x))≥∑f(x)p(x)
前面提到,每个样本 Z i Z_i Zi对于一个隐变量的取值 Z j Z_j Zj,设隐变量 Z j Z_j Zj对应的概率密度值为 Q ( Z j ) Q(Z_j) Q(Zj), ( 3 ) (3) (3)式可写成如下形式:
l o g [ L ( θ ) ] = ∑ i = 1 N l o g ∑ k = 1 K Q ( Z j ) p ( x i ∣ θ k ) Q ( Z j ) (4) log[L(\theta)]=\sum_{i=1}^N log\sum_{k=1}^KQ(Z_j)\frac{p(x_i|\theta_k)}{Q(Z_j)}\tag{4} log[L(θ)]=i=1∑Nlogk=1∑KQ(Zj)Q(Zj)p(xi∣θk)(4)
对 ( 4 ) (4) (4)应用琴声不等式。
f − − − > l o g f--->log f−−−>log
x − − − > p ( x i ∣ θ k ) Q ( Z j ) x--->\frac{p(x_i|\theta_k)}{Q(Z_j)} x−−−>Q(Zj)p(xi∣θk)
p ( x ) − − − > Q ( Z j ) p(x)--->Q(Z_j) p(x)−−−>Q(Zj)
所以有:
∑ i = 1 N l o g ∑ k = 1 K Q ( Z j ) p ( x i ∣ θ k ) Q ( Z j ) ≥ ∑ i = 1 N ∑ k = 1 K l o g ( p ( x i ∣ θ k ) Q ( Z j ) ) Q ( Z j ) = J ( Z , θ ) (5) \sum_{i=1}^N log\sum_{k=1}^KQ(Z_j)\frac{p(x_i|\theta_k)}{Q(Z_j)} \ge\sum_{i=1}^N\sum_{k=1}^Klog(\frac{p(x_i|\theta_k)}{Q(Z_j)})Q(Z_j)=J(Z,\theta)\tag{5} i=1∑Nlogk=1∑KQ(Zj)Q(Zj)p(xi∣θk)≥i=1∑Nk=1∑Klog(Q(Zj)p(xi∣θk))Q(Zj)=J(Z,θ)(5)
由 ( 5 ) (5) (5)式可以看出 l o g L ( θ ) ≥ J ( Z , θ ) logL(\theta)\ge J(Z,\theta) logL(θ)≥J(Z,θ),显然 J ( Z , θ ) J(Z,\theta) J(Z,θ)是似然函数的下界,只要不断提高 J ( Z , θ ) J(Z,\theta) J(Z,θ),就能不断提高 l o g L ( θ ) logL(\theta) logL(θ)。这里有个问题:
- 如何提高 J ( Z , θ ) J(Z,\theta) J(Z,θ)???
J ( Z , θ ) = ∑ i = 1 N ∑ k = 1 K l o g ( p ( x i ∣ θ k ) Q ( Z j ) ) Q ( Z j ) J(Z,\theta)=\sum_{i=1}^N\sum_{k=1}^Klog(\frac{p(x_i|\theta_k)}{Q(Z_j)})Q(Z_j) J(Z,θ)=i=1∑Nk=1∑Klog(Q(Zj)p(xi∣θk))Q(Zj)
显然需要把 Q ( z j ) Q(z_j) Q(zj)先求出来(EM算法的E步),然后求导估计 θ k \theta_k θk(EM算法的M步)。
3.E步
因为 Z Z Z是隐变量,也是一个随机变量,所以有:
∑ z Q ( Z j ) = 1 \sum_{z}Q(Z_j)=1 z∑Q(Zj)=1
当琴声不等式取"="号时,有:
p ( x i ∣ θ k ) Q ( Z j ) = c = ∑ k = 1 K p ( x i ∣ θ k ) ∑ z Q ( Z j ) = ∑ k = 1 K p ( x i ∣ θ k ) \frac{p(x_i|\theta_k)}{Q(Z_j)}=c=\frac{\sum_{k=1}^Kp(x_i|\theta_k)}{\sum_{z}Q(Z_j)}=\sum_{k=1}^Kp(x_i|\theta_k) Q(Zj)p(xi∣θk)=c=∑zQ(Zj)∑k=1Kp(xi∣θk)=k=1∑Kp(xi∣θk)
所以 Q ( Z j ) = p ( x i ∣ θ k ) ∑ k = 1 K p ( x i ∣ θ k ) Q(Z_j)=\frac{p(x_i|\theta_k)}{\sum_{k=1}^Kp(x_i|\theta_k)} Q(Zj)=∑k=1Kp(xi∣θk)p(xi∣θk)
从这里可以看出,如果 p ( x i ∣ θ k ) = p ( x i + 1 ∣ θ k ) p(x_i|\theta_k)=p(x_{i+1}|\theta_k) p(xi∣θk)=p(xi+1∣θk),那么 Q ( Z j ) = Q ( Z j + 1 ) Q(Z_j)=Q(Z_{j+1}) Q(Zj)=Q(Zj+1)。即对于同分布的样本,其隐变量取值相同的概率是一样的。
通过初始化 θ k \theta_k θk,那么就可先估计出 Q ( Z j ) Q(Z_j) Q(Zj)。这是E步。
4.M步
当 Q ( Z j ) Q(Z_j) Q(Zj)已知,带入 J ( Z , θ ) J(Z,\theta) J(Z,θ),令 d J ( z , θ ) d θ = 0 \frac{dJ(z,\theta)}{d{\theta}}=0 dθdJ(z,θ)=0,估计 θ \theta θ。
重复E步与M步,直到算法收敛,这就是EM算法啦~
高斯混合模型(GMM)
高斯混合模型是利用多个高斯分布对任意的分布进行拟合。最大的问题也是参数估计,用的方法也是EM算法。
1.极大似然估计
设有样本 X = { X 1 , X 2 . . . . X n } X=\{X_1,X_2....X_n\} X={X1,X2....Xn},对样本 X i X_i Xi
X i ∼ ∑ k = 1 K π k N ( μ k , Σ k ) X_i\sim\sum_{k=1}^K\pi_kN(\mu_k,\Sigma_k) Xi∼k=1∑KπkN(μk,Σk)
即利用 K K K个高斯分布进行拟合。
对于样本 X i X_i Xi引入 K K K维隐变量 Z j = [ z j 1 z j 2 ⋮ z j k ] Z_j=\begin{bmatrix} z_{j1} \\ z_{j2}\\\vdots \\z_{jk}\end{bmatrix} Zj=⎣⎢⎢⎢⎡zj1zj2⋮zjk⎦⎥⎥⎥⎤,其中 ∑ k = 1 K z j k = 1 \sum_{k=1}^Kz_{jk}=1 ∑k=1Kzjk=1,且只有一个分量能等于 1 1 1,代表该高斯分量的概率最大。
下面要混合高斯分布写成包含隐变量的形式,需要用到概率公式。
对于 Q ( z j k ) Q(z_{jk}) Q(zjk)
Q ( z j k ) = π k , z j k = 1 Q(z_{jk})=\pi_k,z_{jk}=1 Q(zjk)=πk,zjk=1
Q ( z j k ) = 1 , z j k = 0 Q(z_{jk})=1,z_{jk}=0 Q(zjk)=1,zjk=0
所以 Q ( z j k ) = π k z j k (6) Q(z_{jk})=\pi_k^{z_{jk}}\tag{6} Q(zjk)=πkzjk(6)
对于 p ( X i , Z j ) p(X_i,Z_j) p(Xi,Zj)有:
p ( X i , Z j ) = ∏ k = 1 K p ( X i ∣ z j k ) Q ( z j k ) (7) p(X_i,Z_j)=\prod_{k=1}^Kp(X_i|z_{jk})Q(z_{jk})\tag{7} p(Xi,Zj)=k=1∏Kp(Xi∣zjk)Q(zjk)(7)
( 7 ) (7) (7)式用到了全概率公式,且:
p ( X i ∣ z j k ) = N ( X i ∣ μ k , Σ k ) z j k (8) p(X_i|z_{jk})=N(X_i|\mu_k,\Sigma_k)^{z_{jk}}\tag{8} p(Xi∣zjk)=N(Xi∣μk,Σk)zjk(8)
把 ( 6 ) ( 7 ) (6)(7) (6)(7)代入 ( 8 ) (8) (8),带隐变量的GMM分布为:
p ( X i , Z j ) = ∏ k = 1 K N ( X i ∣ μ k , Σ k ) z j k π k z j k (9) p(X_i,Z_j)=\prod_{k=1}^KN(X_i|\mu_k,\Sigma_k)^{z_{jk}}\pi_k^{z_{jk}}\tag{9} p(Xi,Zj)=k=1∏KN(Xi∣μk,Σk)zjkπkzjk(9)
带隐变量的似然函数为:
L ( X , Z , μ , Σ ) = ∏ i = 1 N ∏ k = 1 K N ( X i ∣ μ k , Σ k ) z j k π k z j k (10) L(X,Z,\mu,\Sigma)=\prod_{i=1}^N\prod_{k=1}^KN(X_i|\mu_k,\Sigma_k)^{z_{jk}}\pi_k^{z_{jk}}\tag{10} L(X,Z,μ,Σ)=i=1∏Nk=1∏KN(Xi∣μk,Σk)zjkπkzjk(10)
取对数得:
l n ( L ( X , Z , μ , Σ ) ) = ∑ k = 1 K ( ∑ j = 1 N z j k ) l n ( π k ) + ∑ i = 1 N z j k l n ( N ( X i ∣ μ k , Σ k ) ) (11) ln(L(X,Z,\mu,\Sigma))=\sum_{k=1}^K(\sum_{j=1}^Nz_{jk})ln(\pi_k)+\sum_{i=1}^Nz_{jk}ln(N(X_i|\mu_k,\Sigma_k))\tag{11} ln(L(X,Z,μ,Σ))=k=1∑K(j=1∑Nzjk)ln(πk)+i=1∑Nzjkln(N(Xi∣μk,Σk))(11)
2.E步
估计 Z j Z_j Zj,根据EM算法的E步有:
E ( Z j ) = Q ( Z j ) Z j = π k N ( X i ) ∑ k = 1 k π k N ( X i ) E(Z_j)=Q(Z_j)Z_j=\frac{\pi_kN(X_i)}{\sum_{k=1}^k\pi_kN(X_i)} E(Zj)=Q(Zj)Zj=∑k=1kπkN(Xi)πkN(Xi)
其中, E ( Z j ) E(Z_j) E(Zj)是一个 K K K维的向量。这个式子可以直接根据EM算法导出,也可以根据概率公式进行计算。
2.M步
有了E步,即知道了 Z j Z_j Zj,那么可以直接对 ( 11 ) (11) (11)式子求导了,具体的求导运算不写了,直接给结果吧。
μ k = ∑ i = 1 N z j k X i ∑ i = 1 N z j k \mu_k=\frac{\sum_{i=1}^Nz_{jk}X_i}{\sum_{i=1}^Nz_{jk}} μk=∑i=1Nzjk∑i=1NzjkXi
Σ k = ∑ i = 1 N z j k ( X i − μ k ) T ( X i − μ k ) ∑ i = 1 N z j k \Sigma_k=\frac{\sum_{i=1}^Nz_{jk}(X_i-\mu_k)^T(X_i-\mu_k)}{\sum_{i=1}^Nz_{jk}} Σk=∑i=1Nzjk∑i=1Nzjk(Xi−μk)T(Xi−μk)
π k = ∑ i = 1 N z j k N \pi_k=\frac{\sum_{i=1}^Nz_{jk}}{N} πk=N∑i=1Nzjk
3.matlab仿真
clear;%%以下用GMM模型进行聚类
%首先产生数据,%%产生了80个数据点,均服从二维高斯分布
X1=normrnd(3,1,[100 2]);
X2=normrnd(6,1.5,[40 2]);
X=[X1',X2'];
%初始化相应的参数;
N=length(X);
beta=0.001;%正则化因子
% Pai=0.5*ones(2,1);%%这是混合GMM的分量
Pai(1)=0.2;Pai(2)=0.8;
mu_1=rand(1)*ones(2,1);%产生均值矩阵
mu_2=rand(1)*ones(2,1);
Var_1=rand(1)*eye(2);%产生协方差矩阵
Var_2=rand(1)*eye(2);
for iter=1:20
%E步
for i=1:N
N_x_1=mvnpdf(X(:,i),mu_1,Var_1);%对应概率密度的值
N_x_2=mvnpdf(X(:,i),mu_2,Var_2);
EZ(1,i)=Pai(1)*N_x_1/(Pai(1)*N_x_1+Pai(2)*N_x_2); %估计隐变量
EZ(2,i)=Pai(2)*N_x_2/(Pai(1)*N_x_1+Pai(2)*N_x_2);
end
%M步
%1)更新均值向量
N_k1=sum(EZ(1,:));
N_k2=sum(EZ(2,:)); %隐变量对于分量的和
m1=0;m2=0;
for i=1:N
m1=m1+EZ(1,i)*X(:,i);
m2=m2+EZ(2,i)*X(:,i);
end
mu_1=m1/N_k1;
mu_2=m2/N_k2;
%2)更新协方差矩阵
V1=0;V2=0; %代表临时的方差矩阵
for i=1:N
V1=V1+EZ(1,i)*(X(:,i)-mu_1)*(X(:,i)-mu_1)';
V2=V2+EZ(2,i)*(X(:,i)-mu_2)*(X(:,i)-mu_2)'; %%更新方差矩阵
end
Var_1=V1/N_k1+beta*eye(2);
Var_2=V2/N_k2+beta*eye(2);
%3)更新pai值
Pai(1)=N_k1/N;
Pai(2)=N_k2/N;
end
%%看看效果
for i=1:N
if(EZ(1,i)>=EZ(2,i))
rx1(:,i)=X(:,i);
else
rx2(:,i)=X(:,i);
end
end
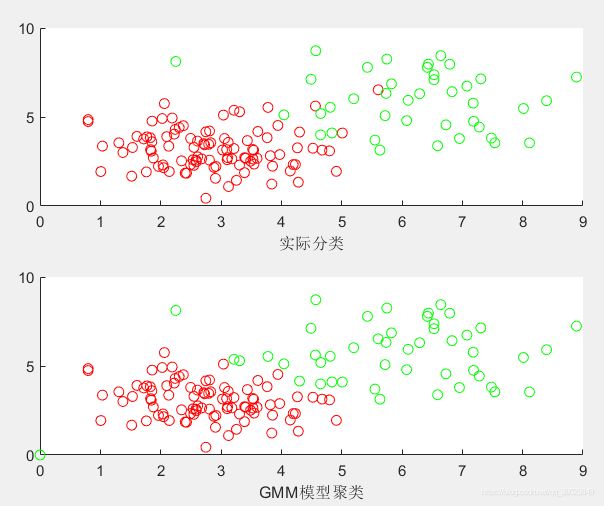
subplot(2,1,1);
scatter(X1(:,1),X1(:,2),'r');
hold on;
scatter(X2(:,1),X2(:,2),'g');
xlabel('实际分类');
hold off;
subplot(2,1,2);
scatter(rx1(1,:),rx1(2,:),'r');
hold on;
scatter(rx2(1,:),rx2(2,:),'g');
xlabel('GMM模型聚类')
hold off;
结果:
K-means算法
K-means只是GMM模型的退化,弄明白了EM和GMM算法,K-means很容易理解。
1.理论分析
目标函数如下:
J = ∑ i = 1 N ∑ k = 1 K ∣ ∣ ( X i − μ k ) ∣ ∣ J=\sum_{i=1}^N \sum_{k=1}^K||(X_i-\mu_k)|| J=i=1∑Nk=1∑K∣∣(Xi−μk)∣∣
E步,经过初始后,先大概分类:
d k = ∣ ∣ X i − μ k ∣ ∣ d_k=||X_i-\mu_k|| dk=∣∣Xi−μk∣∣
对于 X i X_i Xi, d k d_k dk最大,则划分为第 k k k类,这个过程也可以用GMM模型中的隐变量表示。
M步,估计 μ k \mu_k μk
μ k = ∑ k = 1 N k X k N k \mu_k=\frac{\sum_{k=1}^{N_k}{X_k}}{N_k} μk=Nk∑k=1NkXk
表达了对所以的 k k k类数据求取均值。
2.matlab仿真
clear;%%以下用K-means模型进行聚类
%首先产生数据,%%产生了80个数据点,均服从二维高斯分布
X1=normrnd(3,1,[100 2]);
X2=normrnd(6,1.5,[100 2]);
X=[X1',X2'];
%初始化相应的参数;
N=length(X);
iter=20;
x1_=[0,2]';
x2_=[3,3]'; %均值(质心的初始值)
for j=1:iter
%E步
for i=1:N
d_1=norm(X(:,i)-x1_);
d_2=norm(X(:,i)-x2_);
if(d_1<d_2)
z(:,i)=[1;0];
else
z(:,i)=[0;1];
end
end
%M步
%分别计算更新后的x1_,x2_
tmp_1=0;tmp_2=0;
N_1=0;N_2=0;
for(i=1:N)
if( z(:,i)==[1;0])
tmp_1=tmp_1+X(:,i);
N_1=N_1+1;
else
tmp_2=tmp_2+X(:,i);
N_2=N_2+1;
end
end
x1_=tmp_1/N_1;
x2_=tmp_2/N_2;
%%看看误差
e(j)=0;
for(i=1:N)
e(j)=e(j)+norm(X(:,i)-x1_)+norm(X(:,i)-x2_);
end
end
%画图
%%看看效果
for i=1:N
if(z(:,i)==[1,0]')
rx1(:,i)=X(:,i);
else
rx2(:,i)=X(:,i);
end
end
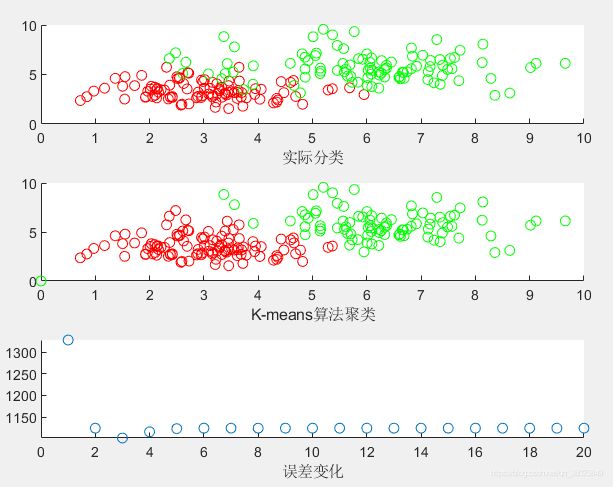
subplot(3,1,1);
scatter(X1(:,1),X1(:,2),'r');
hold on;
scatter(X2(:,1),X2(:,2),'g');
xlabel('实际分类');
hold off;
subplot(3,1,2);
scatter(rx1(1,:),rx1(2,:),'r');
hold on;
scatter(rx2(1,:),rx2(2,:),'g');
xlabel('K-means算法聚类');
hold off;
subplot(3,1,3)
m=1:1:iter;
scatter(m',e);
xlabel('误差变化');
最后要感谢几位大神的博客,受益匪浅!!
参考文献:
[1]https://blog.csdn.net/jinping_shi/article/details/59613054
[2]https://blog.csdn.net/lin_limin/article/details/81048411?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf
[3]https://blog.csdn.net/zouxy09/article/details/8537620