pandas 删除列_Python之Pandas使用系列(六):读写各种外部文件之CSV文件

介绍:
我们将学习如何在Pandas中使用逗号分隔的CSV文件。我们将介绍如何使用Pandas将CSV加载到Dataframe以及如何将Dataframe写入CSV文件。
Pandas从硬盘导入CSV
在此Pandas阅读CSV教程的第一个示例中,我们将仅使用read_csv将CSV加载到与脚本位于同一目录中的Dataframe。如果文件在另一个目录中,则必须记住将完整路径添加到文件中。
这是第一个非常简单的Pandas read_csv示例:
df = pd.read_csv('amis.csv')df.head()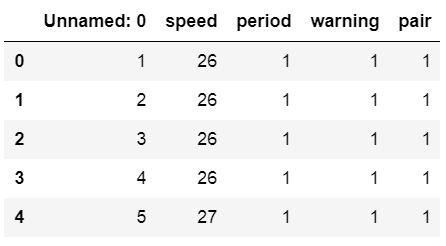
可以在此处下载数据,但在以下示例中,我们将使用Pandas read_csv从URL加载数据。
Pandas从URL读取CSV
我们可以使用Pandas从URL导入CSV文件,我们只需将URL作为read_csv方法中的第一个参数:
url_csv = 'https://vincentarelbundock.github.io/Rdatasets/csv/boot/amis.csv'df = pd.read_csv(url_csv)df.head()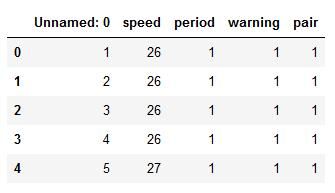
在上图中,我们可以看到我们得到了名为"Unnamed:0"的列。此外,我们可以看到它包含数字。因此,当使用Pandas read_csv方法时,我们可以将此列用作索引列。在下一个代码示例中,我们将使用Pandas read_csv和index_col参数。
此参数可以采用整数或序列。在我们的例子中,我们将使用整数0,我们将获得更好的Dataframe:
df = pd.read_csv(url_csv, index_col=0)df.head()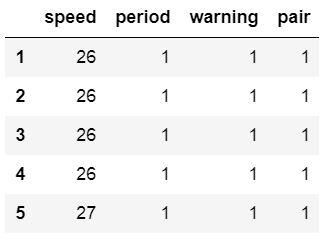
index_col参数也可以将字符串作为输入,我们现在将使用其他数据文件。在下一个示例中,我们将CSV读取到Pandas Dataframe中,并使用idNum列作为Index。
csv_url = 'http://vincentarelbundock.github.io/Rdatasets/csv/carData/MplsStops.csv'df = pd.read_csv(csv_url, index_col='idNum')df.iloc[:, 0:6].head() # 选择前7行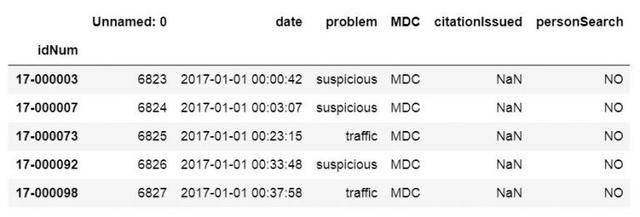
注意,要获得上述输出,我们使用了Pandas iloc选择前7行。这样做是为了获得可以更容易说明的输出。就是说,我们现在继续下一节,我们将从CSV文件中读取某些列到Dataframe。
Pandas读取CSV,使用usecols参数读取特定列
在某些情况下,我们不想解析CSV文件中的每一列。为了只读取某些列,我们可以使用参数usecols。请注意,如果我们希望第一列为索引列,并且要解析前三个列,则需要一个包含4个元素的列表:
cols = [0, 1, 2, 3]df = pd.read_csv(url_csv, index_col=0, usecols=cols)df.head()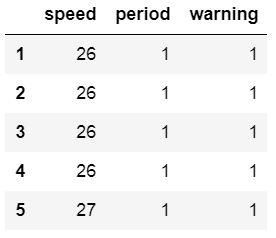
当然,如果我们有一个包含更多列的CSV文件,那么使用read_csv usecols更有意义。我们也可以将Pandas read_csv usecols与字符串列表一起使用。在下一个示例中,我们返回之前使用的较大文件:
csv_url = 'http://vincentarelbundock.github.io/Rdatasets/csv/carData/MplsStops.csv'df = pd.read_csv(csv_url, index_col='idNum', usecols=['idNum', 'date', 'problem', 'MDC'])df.head()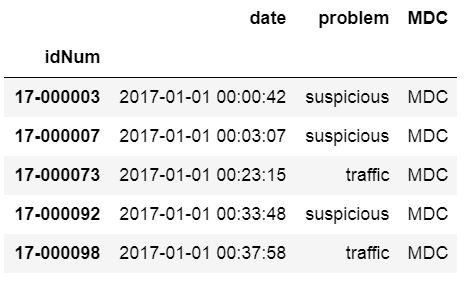
Pandas读取CSV:删除未命名列
在前面的read_csv示例中,我们获得了一个unnamed的列,通过将此列设置为索引或使用usecols从CSV文件中选择特定列。但是,由于某些原因,我们可能不想这样做。这是一个有关如何使用Pandas read_csv消除" Unnamed:0"列的示例:
csv_url = 'http://vincentarelbundock.github.io/Rdatasets/csv/carData/MplsStops.csv'cols = pd.read_csv(csv_url, nrows=1).columnsdf = pd.read_csv(csv_url, usecols=cols[1:])df.iloc[:, 0:6].head()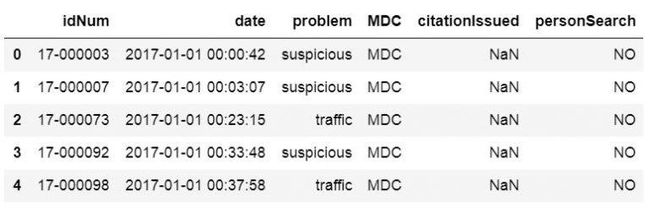
如何从Pandas Dataframe中删除列
当然,也可以在将CSV加载到Dataframe后删除未命名的列。要删除未命名的列,我们可以使用两种不同的方法。定位以及其他PandasDataframe方法。使用drop方法时,我们可以使用inplace参数并获取不包含未命名列的Dataframe。
df.drop(df.columns[df.columns.str.contains('unnamed', case=False)], axis=1, inplace=True)# The following line will give us the same result as the line above# df = df.loc[:, ~df.columns.str.contains('unnamed', case=False)]df.iloc[:, 0:7].head()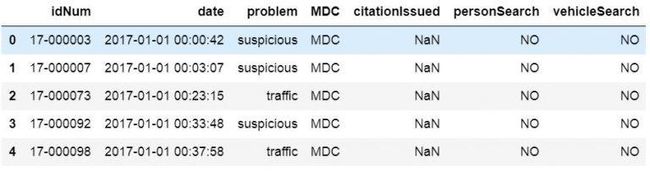
解释上面的代码示例;我们选择没有包含字符串"未命名"的列的列。此外,我们使用了case参数,以便contains方法不区分大小写。因此,我们将获得名为"未命名"和"未命名"的列。在第一行中,使用Pandas drop,我们还使用了inplace参数,以便它更改Dataframe。的轴参数,但是,用于删除的,而不是索引(即,行)的列。
· 学习一些使用Python和Pandas的数据处理技术。
Pandas读取CSV和缺少值
在本节中,我们将学习如何处理PandasDataframe中的缺失值。如果我们的CSV文件中缺少数据,并且编码方式使得Pandas无法找到它们,则可以使用参数na_values。在下面的示例中,amis.csv文件已更改,并且有些单元格的字符串为" Not Available"。
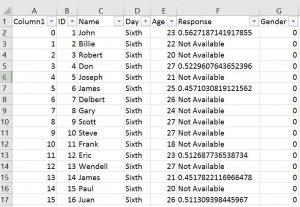
读取CSV和跳过行
如果我们的数据文件包含前x行的信息并且使用Pandasread_csv时需要跳过行怎么办?例如,我们如何跳过文件中的前三行,如下所示:
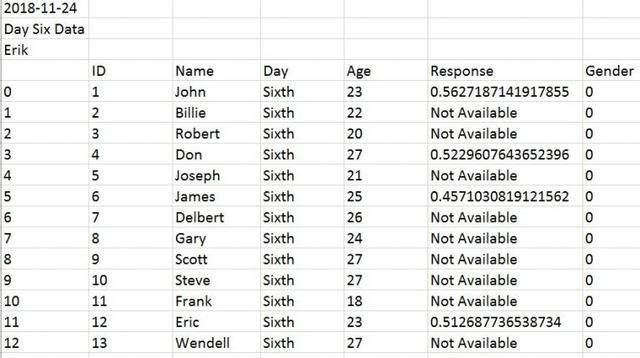
我们只使用skiprows参数。在以下示例中,我们使用read_csv和skiprows = 3跳过前3行。
df = pd.read_csv('Simdata/skiprow.csv', index_col=0, skiprows=3)df.head()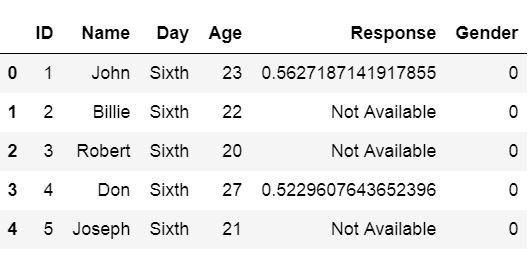
注意,我们可以使用header参数获得与上述相同的结果(即data = pd.read_csv('Simdata / skiprow.csv',header = 3))。
如何使用Pandas读取某些行
如果我们不想读取CSV文件中的每一行,则可以使用参数nrows。在下一个示例中,我们读取CSV文件的前8行。
df = pd.read_csv(url_csv, nrows=8)df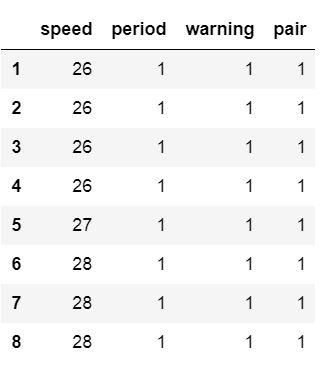
Pandasread_csv dtype
我们还可以设置列的数据类型。尽管在amis数据集中所有列都包含整数,但我们可以将其中一些设置为字符串数据类型。:
url_csv = 'https://vincentarelbundock.github.io/Rdatasets/csv/boot/amis.csv'df = pd.read_csv(url_csv, dtype={'speed':int, 'period':str, 'warning':str, 'pair':int})df.info()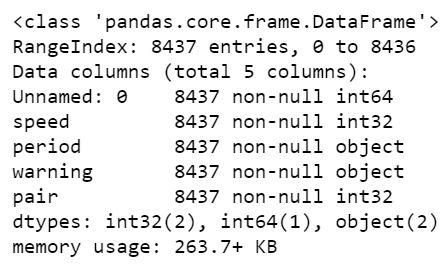
当然,可以强制使用其他数据类型,例如整数和浮点数。例如,我们要做的就是将str更改为float(当然,假设该列中有十进制数字)。
将多个文件加载到Dataframe
如果我们从许多来源(例如实验参与者)获得数据,我们可能会将它们保存在多个CSV文件中。如果要将来自不同CSV文件的数据一起分析,则可能需要将它们全部加载到一个Dataframe中。在下面的示例中,我们将使用Pandas read_csv读取多个文件。
首先,我们将使用Python os和fnmatch在目录" SimData"中列出文件类型为CSV的单词" Day"的所有文件。接下来,我们使用Python列表推导将CSV文件加载到Dataframe中(存储在列表中,请参见type(dfs)输出)。
import os, fnmatchcsv_files = fnmatch.filter(os.listdir('./SimData'), '*Day*.csv')dfs = [pd.read_csv('SimData/' + os.sep + csv_file) for csv_file in csv_files]type(dfs)# Output: list最后,我们使用concat方法来连接列表中的Dataframe。在示例文件中,有一列称为"天",因此每一天(即CSV文件)都是唯一的。
df = pd.concat(dfs, sort=False)df.Day.unique()我们将要使用的第二种方法要简单一些。使用Python glob。如果我们比较这两种方法(os + fnmatch和glob),我们可以看到在列表理解中我们不必放置路径。这是因为glob将具有我们文件的完整路径。便利!
import globcsv_files = glob.glob('SimData/*Day*.csv')dfs = [pd.read_csv(csv_file) for csv_file in csv_files]df = pd.concat(dfs, sort=False)如果我们没有一列,则在每个CSV文件中,确定它是哪个数据集(例如,不同日期的数据),我们可以在每个Dataframe的新列中应用文件名:
import globcsv_files = glob.glob('SimData/*Day*.csv')dfs = []for csv_file in csv_files: temp_df = pd.read_csv(csv_file) temp_df['DataF'] = csv_file.split('')[1] dfs.append(temp_df)现在我们知道了如何导入多个CSV文件。
如何在Pandas中写入CSV文件
导入Pandas模块:
import pandas as pd使用一个字典创建Dataframe。键将是列名,值将是包含我们的数据的列表:
df = pd.DataFrame({'Names':['Andreas', 'George', 'Steve', 'Sarah', 'Joanna', 'Hanna'], 'Age':[21, 22, 20, 19, 18, 23]})df.head()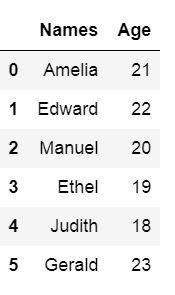
如何将Pandas保存为CSV
我们编写使用Pandas Dataframe到CSV文件to_csv方法。在下面的示例中,除了path_or_buf(在本例中为文件名)之外,我们不使用任何参数。
df.to_csv('NamesAndAges.csv')导出的Dataframe如下所示:
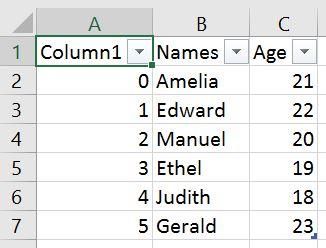
由于在图像中可以看到上面我们,当我们没有使用任何参数,得到一个新的列。该列是我们PandasDataframe的索引列。使用Pandas to_csv时,我们可以使用参数index并将其设置为False来消除此列。
df.to_csv('NamesAndAges.csv', index=False)如何将多个Dataframe写入一个CSV文件
当然,如果我们有许多Dataframe,并且希望将它们全部导出到相同的CSV文件中,则可以。在下面的Pandas to_csv示例中,我们有3个Dataframe。我们将使用Pandas concat和参数key和names。
这样做是为了创建两个新列,名为Group和Row Num。重要的部分是组,它将识别不同的Dataframe。在代码示例的最后一行,我们使用Pandas to_csv将Dataframe写入CSV。
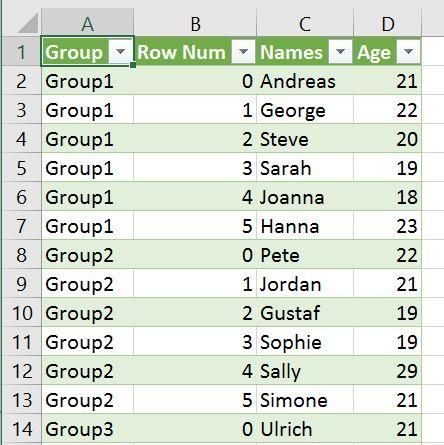
df1 = pd.DataFrame({'Names': ['Andreas', 'George', 'Steve', 'Sarah', 'Joanna', 'Hanna'], 'Age':[21, 22, 20, 19, 18, 23]})df2 = pd.DataFrame({'Names': ['Pete', 'Jordan', 'Gustaf', 'Sophie', 'Sally', 'Simone'], 'Age':[22, 21, 19, 19, 29, 21]})df3 = pd.DataFrame({'Names': ['Ulrich', 'Donald', 'Jon', 'Jessica', 'Elisabeth', 'Diana'], 'Age':[21, 21, 20, 19, 19, 22]})df = pd.concat([df1, df2, df3], keys =['Group1', 'Group2', 'Group3'], names=['Group', 'Row Num']).reset_index()df.to_csv('MultipleDfs.csv', index=False)在CSV文件中,我们有4列。带有列表的keys参数(['Group1','Group2','Group3'])将使我们能够识别所编写的不同Dataframe。我们还将获得"行数"列,其中将包含每个Dataframe的行号:
结论
在本文中,我们学习了如何将CSV文件导入Pandas Dataframe,如何将处理好的Dataframe 写入到CSV文件。
下期我们继续介绍《Python之Pandas使用系列(六):读写各种外部文件之Excel文件》
点击关注,如果发现任何不正确的地方,或者想分享有关上述主题的更多信息,欢迎反馈。