轻量级网络 ESPNetv2
ESPNetv2: A Light-weight, Power Efficient, and General Purpose Convolutional Neural Network
[CVPR2019]
[GitHub]
Abstract
We introduce a light-weight, power efficient, and general purpose convolutional neural network, ESPNetv2, for modeling visual and sequential data. Our network uses group point-wise and depth-wise dilated separable convolutions to learn representations from a large effective receptive field with fewer FLOPs and parameters. The performance of our network is evaluated on four different tasks: (1) object classification, (2) semantic segmentation, (3) object detection, and (4) language modeling. Experiments on these tasks, including image classification on the ImageNet and language modeling on the PenTree bank dataset, demonstrate the superior performance of our method over the state-of-the-art methods. Our network outperforms ESPNet by 4-5% and has 2−4× fewer FLOPs on the PASCAL VOC and the Cityscapes dataset. Compared to YOLOv2 on the MS-COCO object detection, ESPNetv2 delivers 4.4% higher accuracy with 6× fewer FLOPs. Our experiments show that ESPNetv2 is much more power efficient than existing state-of-the-art efficient methods including ShuffleNets and MobileNets.
本文介绍了一种轻量级、节能和通用的卷积神经网络ESPNetv2。
该网络使用 point-wise 和 depth-wise 膨胀可分离卷积(point-wise and depth-wise dilated separable convolutions),以较少的 FLOPs 和参数从一个较大的有效感受野学习表示。
该网络在四个不同的任务上进行了性能评估:(1) 物体分类,(2) 语义分割,(3) 物体检测,(4) 语言建模。在这些任务上的实验,包括在 ImageNet 上的图像分类和在 PenTree bank 数据集上的语言建模,证明了该方法比目前最先进的方法更优越的性能。
各实验表明,ESPNetv2 比现有的最先进的高效方法 (包括 shufflenet 和 mobilenet) 更节能。
Introduction
The increasing programmability and computational power of GPUs have accelerated the growth of deep convolutional neural networks (CNNs) for modeling visual data [16, 22, 34]. CNNs are being used in real-world visual recognition applications such as visual scene understanding [62] and bio-medical image analysis [42]. Many of these real-world applications, such as self-driving cars and robots, run on resource-constrained edge devices and demand online processing of data with low latency.
Existing CNN-based visual recognition systems require large amounts of computational resources, including memory and power. While they achieve high performance on high-end GPU-based machines (e.g. with NVIDIA TitanX), they are often too expensive for resource constrained edge devices such as cell phones and embedded compute platforms. As an example, ResNet-50 [16], one of the most well known CNN architecture for image classification, has 25.56 million parameters (98 MB of memory) and performs 2.8 billion high precision operations to classify an image. These numbers are even higher for deeper CNNs, e.g. ResNet101. These models quickly overtax the limited resources, including compute capabilities, memory, and battery, available on edge devices. Therefore, CNNs for real-world applications running on edge devices should be light-weight and efficient while delivering high accuracy.
Recent efforts for building light-weight networks can be broadly classified as:
(1) Network compression-based methods remove redundancies in a pre-trained model in order to be more efficient. These models are usually implemented by different parameter pruning techniques [24, 55].
(2) Low-bit representation-based methods represent learned weights using few bits instead of high precision floating points [20, 39, 47]. These models usually do not change the structure of the network and the convolutional operations could be implemented using logical gates to enable fast processing on CPUs.
(3) Light-weight CNNs improve the efficiency of a network by factoring computationally expensive convolution operation [17,18,29,32,44,60]. These models are computationally efficient by their design i.e. the underlying model structure learns fewer parameters and has fewer floating point operations (FLOPs).
In this paper, we introduce a light-weight architecture, ESPNetv2, that can be easily deployed on edge devices. The main contributions of our paper are:
(1) A general purpose architecture for modeling both visual and sequential data efficiently. We demonstrate the performance of our network across different tasks, ranging from object classification to language modeling.
(2) Our proposed architecture, ESPNetv2, extends ESPNet [32], a dilated convolutionbased segmentation network, with depth-wise separable convolutions; an efficient form of convolutions that are used in state-of-art efficient networks including MobileNets [17, 44] and ShuffleNets [29, 60]. Depth-wise dilated separable convolutions improves the accuracy of ESPNetv2 by 1.4% in comparison to depth-wise separable convolutions. We note that ESPNetv2 achieves better accuracy (72.1 with 284 MFLOPs) with fewer FLOPs than dilated convolutions in the ESPNet [32] (69.2 with 426 MFLOPs).
(3) Our empirical results show that ESPNetv2 delivers similar or better performance with fewer FLOPS on different visual recognition tasks. On the ImageNet classification task [43], our model outperforms all of the previous efficient model designs in terms of efficiency and accuracy, especially under small computational budgets. For example, our model outperforms MobileNetv2 [44] by 2% at a computational budget of 28 MFLOPs. For semantic segmentation on the PASCAL VOC and the Cityscapes dataset, ESPNetv2 outperforms ESPNet [32] by 4-5% and has 2 − 4× fewer FLOPs. For object detection, ESPNetv2 outperforms YOLOv2 by 4.4% and has 6× fewer FLOPs. We also study a cyclic learning rate scheduler with warm restarts. Our results suggests that this scheduler is more effective than the standard fixed learning rate scheduler.
Introduction 部分这么大几段,只介绍了三点:
1,真实边缘设备应用中,网络是需要轻量级的、低延时的、高效的。现有的好网络,如 ResNet 并不适合部署在边缘设备中。
2,现在有很多工作开始考虑这些因素,包括三类:网络压缩,低比特量化,和轻量级 CNN。
3,但本文提出了一种更好的网络,FLOPS 低,且在很多任务上 performance 好。
ESPNetv2
Depth-wise dilated separable convolution
卷积分解(Convolution factorization)是许多高效架构所使用的关键原理。其基本思想是用因数分解的版本替换完整的卷积运算,如 depth-wise separable 卷积[17]或 group 卷积[22]。本节将描述深度扩张可分离卷积,并与其他类似的有效卷积形式进行比较。
标准卷积将输入 与卷积核 进行卷积,通过从 n×n 的有效感受野学习 参数,产生输出 。
与标准卷积相比,深度扩展可分离卷积应用轻量级滤波,通过将标准卷积分解为两层:
1) 每个输入通道的深度膨胀卷积,膨胀率为 r;使卷积的有效感受野为 ,其中 ;
2) point-wise 卷积学习输入的线性组合。
这种分解(factorization)减少了  的计算成本。表 1 提供了不同类型卷积的比较。
的计算成本。表 1 提供了不同类型卷积的比较。
深度膨胀可分离卷积(Depth-wise dilated separable convolutions)是有效的,可以从大的有效感受野学习表征。

EESP unit
利用深度膨胀可分卷积和 point-wise 卷积的优点,本文引入了一种新的单元 EESP,即极高效空间金字塔的深度膨胀可分卷积(Extremely Efficient Spatial Pyramid of Depth-wise Dilated Separable Convolutions),专门用于边缘设备。
ESPNet
该网络设计的动机是 ESPNet 架构 [32]。ESPNet 架构的基本构建模块是 ESP 模块,如图 1 (a) 所示。它基于减少-分裂-转换-合并(reduce-split-transform-merge)策略。ESP 单元首先使用 point-wise 卷积将高维输入特征映射投影到低维空间,然后使用不同膨胀率的膨胀卷积并行学习表示。每个分支的不同膨胀速率允许 ESP 单元从一个大的有效感受野学习表征。这种分解,尤其是在低维空间中学习表示,使 ESP 单元变得高效。

EESP-A
为了提高 ESP 模块的计算效率,本文首先将 point-wise 卷积替换为 group point-wise 卷积。
然后,将计算昂贵的(computationally expensive) 3 × 3 膨胀卷积替换为经济的(economical)深度膨胀可分离卷积。
为了消除膨胀卷积造成的网格伪影(gridding artifacts),本文使用计算效率高的层次特征融合 (HFF,hierarchical feature fusion) 方法融合特征映射。该方法将利用膨胀卷积学习到的特征映射以层次化的方式进行叠加融合;来自具有最低感受野的分支的特征映射与具有下一级感受野的分支的特征映射相结合。经此得到的网络单元如图 1 (b) 所示。
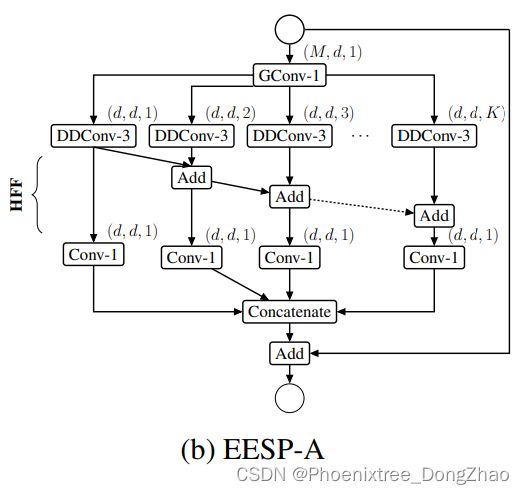
通过 group point-wise 和 depth-wise dilated separable 卷积,ESP 块的总复杂度降低了 ,其中 K 为 group point-wise 卷积的并行分支数,g 为 group point-wise 卷积的 group 数。例如,当 M=240, g=K=4, d= M/K= 60 时,ESP 单元学习的参数比 ESP 单元少 7×。
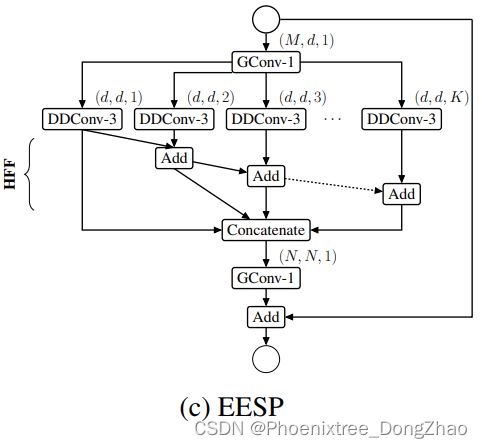
EESP
注意到,单独计算图 1 (b) 中的 K 个 point-wise 卷积 (即 1 × 1),在复杂度上等价于 K 个组的单组point-wise 卷积;然而,group point-wise 卷积在实现方面更有效,因为它启动一个卷积核,而不是 K 个 point-wise 卷积核。因此,本文将这 K 个point-wise 卷积替换为一个 group point-wise 卷积,如图 1(c) 所示。并将把这个单元称为 EESP。
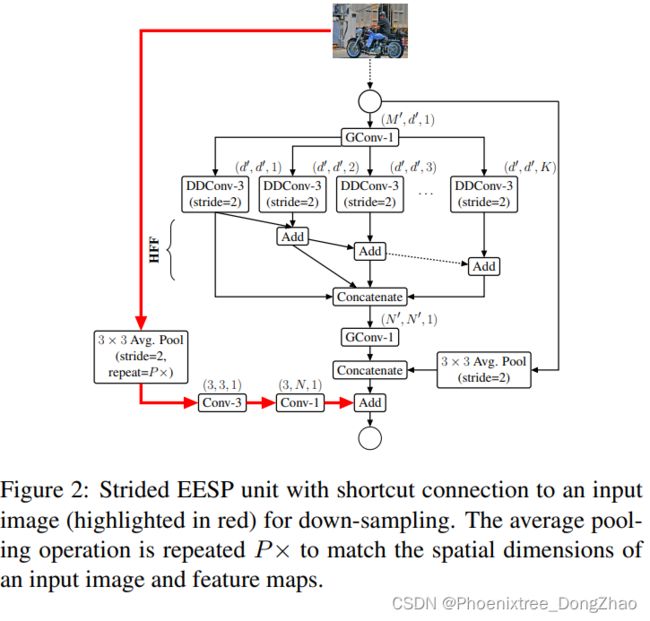
Strided EESP with shortcut connection to an input image
为了在多个尺度上高效地学习表示,本文对图 1(c) 中的 EESP 块做了如下改进:
1) 深度膨胀卷积被 strided 卷积替换,
2) 添加平均池化操作,而不是恒等连接(identity connection),
3) concatenation 替代元素加法操作,这有助于高效地扩展特征映射的维度。
在降采样和卷积 (滤波) 操作期间,空间信息会丢失。为了更好地编码空间关系和有效地学习表示,本文在输入图像和当前下采样单元之间添加了一个高效的远程快捷连接(long-range shortcut connection)。该连接首先对图像进行下采样,使其与特征映射的大小相同,然后使用两个卷积的堆栈学习表示。第一个卷积是标准的 3 × 3 卷积,学习空间表示,而第二个卷积是 point 卷积,学习输入之间的线性组合,并将其投射到高维空间。最终的 EESP 单元具有远程快捷连接到输入端,如图 2 所示。
Network architecture
ESPNetv2 网络采用 EESP 单元构建。在每个空间层次上,ESPNetv2 重复多次 EESP 单元,以增加网络的深度。在 EESP 单元中 (图 1(c)),在每个卷积层后使用批归一化和 PReLU,最后一个组卷积层例外——最后一层在元素求和操作后应用 PReLU。为了在每个空间层面上保持相同的计算复杂度,每进行一次降采样操作后,特征映射将加倍 [16,46]。
在实验中,设置膨胀率 r 与EESP 单元的分支数量 (K)成正比。EESP 单元的有效接收野随K增长。一些核,特别是在低空间水平,如 7 × 7,可能有一个比特征图的大小更大的有效感受野。
因此,这样的内核可能对学习没有帮助。为了得到有意义的核,本文用空间维度  限制每个空间层次l上的有效感受野:
限制每个空间层次l上的有效感受野:
与有效感受野 (nd ×nd) 对应的最低空间水平(即 7×7)为 5×5。
在实验中设置 K = 4。此外,设置 group point-wise 卷积中的组数等于并行分支的数量 (g = K)。不同计算复杂度下的总体 ESPNetv2 架构如表 2 所示。
