【超分辨率】(RDN)Residual Dense Network for Image Super-Resolution论文翻译
机翻,我尽量调整了公式和图片的排版
发现机翻根本看不了,自己人工翻译了下,其中摘要、网络部分(第三节)为人工翻译。
自己翻译过程中难免会出错,希望各位海涵,同时也欢迎各位提出翻译过程中的错误
之后的部分我也会自己翻译,但还需要一些时间
实验结果部分进行了重新翻译
论文地址:https://arxiv.org/pdf/1802.08797.pdf
摘要
一种非常深的卷积神经网络(CNN)最近在图像超分辨率(SR)方向取得了巨大的成功,并提供了分层特征。然而,大多数基于深度CNN的SR模型没有充分利用原始低分辨率(LR)图像的层次特征,因此取得了相对较低的性能。在本文中,我们提出了一种新的残差密集网络(RDN)来解决在图像超分辨率中的这一问题,我们充分利用了所有卷积层的层次性特征。具体来说,我们提出了残差密集块(RDB),该模块通过密集连接的卷积层提取丰富的局部特征。(这是在一个RDB模块的内部)RDB模块还允许将上一个RDB模块的输出直接连接到当前RDB的所有卷积层,从而形成一个连续存储/记忆(CM)机制。(这里补存一段CM的含义:Contiguous memory 意思就是dense connection,连续的连接保证了连续的低级高级信息存储和记忆)所以我在后文将CM翻译为连续存储机制然后利用RDB中的局部特征融合,从已有局部特征的和当前的局部特征中自适应地学习更有效的特征,稳定更宽网络的训练。在充分获取密集的局部特征后,利用全局特征融合,整体地联合自适应地学习全局层次特征。在具有不同退化模型的基准数据集上的实验表明,我们的RDN与最先进的方法相比取得了良好的性能。
1. 介绍
单幅图像超分辨率(SISR)旨在从其降级的低分辨率(LR)测量中生成视觉愉悦的高分辨率(HR)图像。SISR用于各种计算机视觉任务,如安全和监视成像[42]、医疗成像[23]和图像生成[9]。而图像SR是一个病态逆过程,因为对于任何LR输入都存在大量的解。为了解决这个逆问题,人们提出了许多图像SR算法,包括基于插值的[40]、基于重建的[37]和基于学习的方法[28,29,20,2,21,8,10,31,39]。
其中,Dong等人[2]首次引入一个三层卷积神经网络(CNN)应用到图像SR中,取得了较传统方法明显的改进。Kim等人利用梯度裁剪、跳跃连接或递归监督等方法增加了VDSR[10]和DRCN[11]中的网络深度,以缓解深度网络训练的困难。通过使用有效的构建模块,进一步使图像SR网络更深入、更广泛、性能更好。Lim等人使用残余块(图1(a))构建了一个非常宽的网络EDSR[17],其中残余尺度[24]和一个非常深的网络MDSR[17]。Tai等人提出内存块构建MemNet[26]。随着网络深度的增加,每个卷积层中的特征将具有不同的接受域。然而,这些方法忽略了充分利用每一卷积层的信息。虽然在记忆块中提出了门单元来控制短时记忆[26],但局部卷积层不能直接访问后续层。因此,很难说内存块充分利用了来自它内部所有层的信息。
此外,图像中的物体具有不同的比例、视角和纵横比。从一个非常深入的网络中提取的层次特征将为重建提供更多线索。然而,大多数基于深度学习(DL)的方法(如VDSR[10]、LapSRN[13]和EDSR[17])忽略了使用层次特征进行重构。尽管记忆块同时也将先前记忆块中的信息作为输入,不从原始LR图像中提取多层次特征。MemNet将原始LR图像插值到所需的大小,以形成输入。这一预处理步骤不仅使计算复杂度成倍增加,而且会丢失原始LR图像的一些细节。Tong等人针对生长速率相对较低的图像SR引入了密集块(图1(b))。根据我们的实验(见5.2节),更高的增长率可以进一步提高网络的性能。然而,在图1(b)中,用密集的块训练更广泛的网络是很困难的。
为了解决这些缺点,我们提出残差密集网络(RDN)(图2),用我们提出的残差密集块(图1©)充分利用来自原始LR图像的所有层次特征。对于一个非常深入的网络来说,直接提取LR空间中每个卷积层的输出是非常困难和不切实际的。我们提出残差密集块(RDB)作为RDN的构建模块。
RDB由密集连接层和局部特征融合(LFF)和局部残余学习(LRL)组成。我们的RDB还支持RDB之间的连续内存。一个RDB的输出可以直接访问下一个RDB的每一层,从而产生连续的状态传递。RDB中的每个卷积层都可以访问所有后续层,并传递需要保存的信息[7]。LFF将前一层RDB的状态与当前RDB中所有前一层的状态连接起来,通过自适应保留信息提取局部致密特征。此外,LFF通过稳定更广泛网络的训练,允许非常高的增长率。在提取多层次局部密集特征后,进一步进行全局特征融合(GFF),以全局的方式自适应地保留分层特征。如图2和图3所示,每一层直接访问原始LR输入,导致隐式深度监督[15]。



总之,我们的主要贡献有三个方面:
- 针对不同退化模型的高质量图像SR,提出了一种统一的框架残差密集网络(RDN)。该网络充分利用了原始LR图像的所有层次特征。
- 我们提出了剩余密集块(RDB),它不仅可以通过连续内存(CM)机制从前面的RDB中读取状态,还可以通过局部密集连接充分利用RDB中的所有层。然后通过局部特征融合(LFF)自适应地保存累积的特征。
- 我们提出全局特征融合,自适应融合LR空间中所有rdb的层次特征。通过全局残差学习,我们将浅层特征和深层特征结合在一起,得到原始LR图像的全局密集特征。
2.相关工作
近年来,基于深度学习(DL)的方法在计算机视觉领域相对于传统方法取得了显著优势[36,35,34,16]。由于篇幅所限,我们只讨论了图像sr方面的一些工作。Dong等人提出了SRCNN[2],首次在插值后的LR图像与HR对应图像之间建立了端到端映射。然后,主要通过增加网络深度或共享网络权重进一步改进这一基线。VDSR[10]和IRCNN[38]通过使用残差学习叠加更多的卷积层来增加网络深度。DRCN[11]首次在一个非常深的网络中引入递归学习,实现参数共享。Tai等人在DRRN[25]中引入了递归块,在Memnet[26]中引入了内存块,用于更深层次的网络。所有这些方法都需要将原始LR图像插值到所需的大小,然后将它们应用到网络中。这一预处理步骤不仅使计算复杂度增加了2倍[4],而且使原始LR图像过度平滑和模糊,丢失了一些细节。结果是,这些方法从插值后的LR图像中提取特征,无法建立从原始LR到HR图像的端到端映射。
为了解决上述问题,Dong et al.[4]直接将原始LR图像作为输入,引入转置卷积层(也称为反卷积层)进行上采样到精细分辨率。Shi等人提出了ESPCN[22],其中引入了一个高效的亚像素卷积层,将最终的LR特征映射提升到HR输出中。然后在SRResNet[14]和EDSR[17]中采用有效的亚像素卷积层,利用了残差倾斜[6]。这些方法都是从LR空间中提取特征,并通过转置或亚像素卷积层对最终LR特征进行放大。通过这样做,这些网络既可以实现实时SR(如FSRCNN和ESPCN),也可以构建非常深/宽的网络(如SRResNet和EDSR)。然而,所有这些方法都以链式的方式将构建模块(如FSRCNN中的Conv层、SRResNet中的残块和EDSR)进行堆叠。他们忽视了充分利用每个Conv层的信息,只采用LR空间中最后一个Conv层的CNN特征进行升级。
最近,Huang等人提出了DenseNet,它允许在同一致密块[7]内的任意两层之间直接连接。使用本地密集连接,每一层从同一密集块中的所有前面的层读取信息。在内存块[26]和密集块[31]之间引入密集连接。DenseNet/SRDenseNet/MemNet和我们的RDN之间的更多区别将在第4节中讨论。
上述基于DL的图像SR方法较传统的图像SR方法取得了显著的改进,但都失去了一些来自原始低分辨图像的有用的层次特征由非常深的网络产生的分层特征对图像恢复任务(例如,图像SR)很有用。针对这种情况,我们提出了残差密集网络(RDN),从LR空间的所有层有效地提取和自适应融合特征。我们将在下一节中详细介绍RDN。
3.用于图像超分辨率的残差密集网络
3.1网络结构
如图2所示,我们的RDN主要由四部分组成:浅层特征提取网络(SFENet),残差密集模块(RDBs),密集特征融合(DFF),最后是上采样网络(UPNet)。我们将 I L R I_{LR} ILR和 I S R I_{SR} ISR表示为RDN的输入和输出。具体来说,我们使用两个Conv层来提取浅层特征。第一个Conv层从LR输入中提取特征 F − 1 F_{-1} F−1。
F − 1 = H S F E 1 ( I L R ) , ( 1 ) F_{-1}=H_{S F E 1}\left(I_{L R}\right), \quad\quad\quad\quad\quad\quad\quad\quad\quad (1) F−1=HSFE1(ILR),(1)
其中, H S F E 1 ( ⋅ ) H_{S F E 1}(\cdot) HSFE1(⋅)表示卷积运算。然后利用 F − 1 F_{-1} F−1进一步进行浅层特征提取和全局残差学习。所以我们可以更进一步表示该过程为:
F 0 = H S F E 2 ( F − 1 ) , ( 2 ) F_{0}=H_{S F E 2}\left(F_{-1}\right), \quad\quad\quad\quad\quad\quad\quad\quad\quad (2) F0=HSFE2(F−1),(2)
其中, H S F E 2 ( ⋅ ) H_{S F E 2}(\cdot) HSFE2(⋅)表示第二个浅层特征提取层的卷积运算,其输出 F 0 F_0 F0用作残差密集模块的输入。假设我们有 D D D个残差密集模块,第 D D D个RDB的输出 F d F_d Fd可由下式表示:
F d = H R D B , d ( F d − 1 ) = H R D B , d ( H R D B , d − 1 ( ⋯ ( H R D B , 1 ( F 0 ) ) ⋯ ) ) ( 3 ) \begin{aligned} F_{d} &=H_{R D B, d}\left(F_{d-1}\right) \\ &=H_{R D B, d}\left(H_{R D B, d-1}\left(\cdots\left(H_{R D B, 1}\left(F_{0}\right)\right) \cdots\right)\right) \end{aligned} \quad\quad\quad\quad\quad (3) Fd=HRDB,d(Fd−1)=HRDB,d(HRDB,d−1(⋯(HRDB,1(F0))⋯))(3)
式中 H R D B , d ( ⋅ ) H_{R D B, d}(\cdot) HRDB,d(⋅)表示第 d d d个RDB模块的操作。 H R D B , d ( ⋅ ) H_{R D B, d}(\cdot) HRDB,d(⋅)可以是复合函数运算,如卷积和整流线性单位(ReLU)[5]。由于 F d F_d Fd是由第 d d d个RDB模块充分利用模块内的每个卷积层产生的,所以我们可以将 F d F_d Fd视为局部特征。关于RDB模块的更多细节将在第3.2节中进行描述。
用一组RDBs提取层次特征之后,我们进一步进行密集特征融合(DFF),它包括全局特征融合(GFF)和全局残余学习(GRL)。密集特征融合(DFF)充分利用了前面所有层的特征,可以表示为下式:
F D F = H D F F ( F − 1 , F 0 , F 1 , ⋯ , F D ) , ( 4 ) F_{D F}=H_{D F F}\left(F_{-1}, F_{0}, F_{1}, \cdots, F_{D}\right) \text {, } \quad\quad\quad\quad\quad\quad\quad\quad\quad (4) FDF=HDFF(F−1,F0,F1,⋯,FD), (4)
其中 F D F F_{DF} FDF是密集特征融合(DFF)的输出特征图,通过利用复合函数 H D F F H_{DFF} HDFF得到。关于密集特征融合(DFF)的更多细节将在第3.3节中进行描述。
在LR空间中提取局部和全局特征后,我们在HR空间中堆叠一个上采样网络(UPNet)。受[17]的启发,我们在上采样网络(UPNet)中使用ESPCN网络[22],之后紧跟一个卷积层(ESPCN在前,卷积层在后)。RDN的输出可以通过下式表示:
I S R = H R D N ( I L R ) , ( 5 ) I_{S R}=H_{R D N}\left(I_{L R}\right) \text {, } \quad\quad\quad\quad\quad\quad\quad\quad\quad (5) ISR=HRDN(ILR), (5)
其中 H R D N H_{RDN} HRDN表示我们的RDN的函数。
3.2残差密集块

现在我们在图3中展示我们提出的残差密集模块(RDB)的细节。我们的RDB包含密集连接层、局部特征融合(LFF)和局部残余学习,从而形成了连续存储(CM)机制。
Contiguous memory: 连续存储机制是通过将前一个RDB的状态(输出)传递到当前RDB的每一层来实现的。设 F d − 1 F_{d-1} Fd−1和 F d F_d Fd分别为第d个RDB的输入和输出,它们都具有 G 0 G_0 G0个特征图。第d个RDB的第c个Conv层的输出可表示为:
F d , c = σ ( W d , c [ F d − 1 , F d , 1 , ⋯ , F d , c − 1 ] ) , ( 6 ) F_{d, c}=\sigma\left(W_{d, c}\left[F_{d-1}, F_{d, 1}, \cdots, F_{d, c-1}\right]\right) \text {, } \quad\quad\quad\quad\quad\quad(6) Fd,c=σ(Wd,c[Fd−1,Fd,1,⋯,Fd,c−1]), (6)
其中σ为ReLU[5]激活函数。 W d , c W_{d,c} Wd,c是第c个Conv层的权值,其中为了简单起见省略了偏置。我们假设 F d , c F_{d,c} Fd,c由G个(也称为增长率[7],也就是卷积核的个数)特征图组成。 [ F d − 1 , F d , 1 , ⋯ , F d , c − 1 ] \left[F_{d-1}, F_{d, 1}, \cdots, F_{d, c-1}\right] [Fd−1,Fd,1,⋯,Fd,c−1]是指将第(d - 1)个RDB模块的特征图和第d个RDB模块中的卷积层1,···,(c−1)产生的特征映射进行拼接,得到 G 0 + ( c − 1 ) × G G_0+(c−1)×G G0+(c−1)×G个特征图(该拼接得到的特征图作为第d个RDB模块中第c个卷积层的输入,从而产生 G 0 G_0 G0个特征图)。前一个RDB模块的输出和当前RDB模块中的每一个卷积层的输出都与后面所有卷积层直接连接(这里的后面所有的卷积层仍然是在当前RDB模块内部),既保留了前馈特性,又提取了局部密集特征。
Local feature fusion:然后采用局部特征融合的方法,自适应地融合来自上一个RDB模块和当前RDB模块中的所有Conv层的状态(特征)。如上所述,将第(d−1)个RDB模块的特征图以拼接的方式直接引入到第d个RDB模块中,这对于减少特征数量来说是必要的。另一方面,受MemNet[26]的启发,我们引入了1 × 1卷积层来自适应控制输出信息。我们将这种操作称为局部特征融合(LFF),并公式化为:
F d , L F = H L F F d ( [ F d − 1 , F d , 1 , ⋯ , F d , c , ⋯ , F d , C ] ) , ( 7 ) F_{d, L F}=H_{L F F}^{d}\left(\left[F_{d-1}, F_{d, 1}, \cdots, F_{d, c}, \cdots, F_{d, C}\right]\right), \quad\quad\quad\quad\quad(7) Fd,LF=HLFFd([Fd−1,Fd,1,⋯,Fd,c,⋯,Fd,C]),(7)
其中 H L F F d H_{L F F}^{d} HLFFd表示第d个RDB中的1 × 1 Conv层操作。我们还发现,随着增长率G的增大,没有局部特征融合(LFF)的非常深的密集网络将很难训练。(这也是为什么在摘要里说,可以稳定更宽网络的训练)
Local residual learning:由于一个RDB中有多个卷积层,为了进一步改善信息流,所以在RDB模块中引入了局部剩余学习。第d个RDB的最终输出可以通过如下式子表示:
F d = F d − 1 + F d , L F . ( 8 ) F_{d}=F_{d-1}+F_{d, L F} . \quad\quad\quad\quad\quad\quad\quad\quad\quad (8) Fd=Fd−1+Fd,LF.(8)
需要注意的是,LRL还可以进一步提高网络表示能力,从而获得更好的性能。我们将在第5节介绍更多关于LRL的结果。由于密集连接特性和局部残差学习的特点,我们将这种块体系结构称为残差密集块(RDB)。RDB模块和原始密集模块[7]之间的更多区别将在第4节中总结。
3.3 密集的特征融合
使用一组RDBs模块提取局部密集特征后,我们进一步提出了密集特征融合(DFF),以全局的方式利用分层特征。密集特征融合(DFF)由全局特征融合(GFF)和全局残余学习两部分组成。
Global feature fusion:全局特征融合是通过融合所有RDBs中的特征来提取全局特征 F G F F_{GF} FGF:
F G F = H G F F ( [ F 1 , ⋯ , F D ] ) , ( 9 ) F_{G F}=H_{G F F}\left(\left[F_{1}, \cdots, F_{D}\right]\right), \quad\quad\quad\quad\quad\quad\quad\quad\quad (9) FGF=HGFF([F1,⋯,FD]),(9)
其中 [ F 1 , ⋯ , F D ] \left[F_{1}, \cdots, F_{D}\right] [F1,⋯,FD]表示残差密集模块(RDB)1,···,d产生的特征图的拼接。 H G F F H_{GF F} HGFF是1 × 1和3 × 3卷积的复合函数。1 × 1卷积层用于自适应融合一系列不同层次的特征。随后引入3 × 3卷积层进一步提取特征为了进行全局残差学习,该方法在[14]中已被证明是有效的。
Global residual learning :然后利用全局残差学习获取特征图,再通过下式进行up-scaling:
F D F = F − 1 + F G F ( 10 ) F_{D F}=F_{-1}+F_{G F} \quad\quad\quad\quad\quad\quad\quad\quad\quad (10) FDF=F−1+FGF(10)
其中 F − 1 F_{−1} F−1为浅层特征图。在全局特征融合之前的所有其他层都被我们提出的残差密集模块(RDBs)充分利用。RDBs产生多层次的局部密集特征,进一步自适应融合形成 F G F F_{GF} FGF。经过全局残差学习,得到密集特征 F D F F_{DF} FDF。
需要注意的是,Tai 等人[26]利用MemNet中的长期密集连接来恢复更多的高频信息。然而,在memory block[26]中,前面的层不能直接访问所有后面的层。局部特征信息没有得到充分利用,限制了长期连接的能力。此外,MemNet提取了HR空间中的特征,增加了计算复杂度。而受到[4,22,13,17]的启发,我们在LR空间中提取局部和全局特征。我们的残差密集网络和MemNet之间的更多区别将在第4节中进行描述。我们还将在第5节中演示全局特征融合的有效性。
3.4实现细节
在我们提出的RDN中,我们将所有卷积层的大小设置为3 × 3,除了在局部和全局特征融合中,其内核大小为1 × 1。对于核大小为3 × 3的卷积层,我们进行零填充,以保持特征图的尺寸大小固定。浅层特征提取层、局部和全局特征融合层具有 G 0 G_0 G0=64个滤波器。每个RDB中的其他层有G个滤波器,卷积操作之后是ReLU层[5]。与[17]相同,我们在UPNet中使用ESPCNN[22]将粗粒度分辨率特征转换为细粒度分辨率特征。最后的Conv层有3个输出通道,因为我们输出彩色HR图像。然而,该网络也可以处理灰度图像。
4.讨论
Difference to DenseNet: 受到DenseNet[7]的启发,我们采用局部密集连接到我们提出的残差密集模块(RDB)中。一般来说,DenseNet广泛应用于高级计算机视觉任务(例如,物体识别)。而RDN是为图像SR而设计的。此外,我们去掉了批归一化(BN)层,它与卷积层消耗相同的GPU内存,增加了计算复杂度,并影响了网络的性能。我们还删除了池化层,这可能会丢弃一些像素级信息。此外,过渡层被放置到DenseNet中相邻的两个密集模块中。而在RDN中,我们通过使用局部残差学习将密集连接的层与局部特征融合(LFF)结合起来,这将在第5节中证明是有效的。因此,第 ( d − 1 ) (d−1) (d−1)个RDB的输出直接连接到第 ( d ) (d) (d)个 RDB中的每一层,并贡献于第(d + 1)个RDB的输入。最后,我们采用全局特征融合,充分利用了DenseNet中被忽略的分层特征。
Difference to SRDenseNet: SRDenseNet[31]和我们的RDN之间有三个主要区别。第一个是基础构件模块的设计。SRDenseNet引入了来自DenseNet[7]的基础密集模块。我们的残差密集块(RDB)从三个方面进行了改进:(1)我们引入了连续存储(CM)机制,使上一层RDB的状态(输出)可以直接访问(连接到)当前RDB中的每一层。(2)通过利用局部特征融合(LFF),我们的RDB允许更大的增长率,LFF能够稳定更宽网络的训练过程。(3)在RDB中利用局部残差学习(LRL)进一步鼓励信息和梯度的流动。二是RDB之间没有密集的连接。我们使用全局特征融合(GFF)和全局残差学习来提取全局特征,因为我们的RDBs具有连续存储机制,在局部已经完全提取了特征。如第5.2和5.3节所示,所有这些组件都显著提高了性能。第三个是SRDenseNet使用L2损失函数。而我们使用L1损失函数,它已被证明对性能和收敛[17]更强大。因此,我们提出的RDN实现了比SRDenseNet更好的性能。
Difference to MemNet.:除了损失函数的选择不同(MemNet[26]中的L2),我们主要总结了MemNet和我们的RDN的另外三个不同点:首先,MemNet需要使用双三次插值对原始LR图像进行上采样,使其达到所需的尺寸大小。该过程实现了在HR空间中的特征提取和重构。而RDN从原始LR图像中提取分层特征,大大降低了计算复杂度,提高了性能。其次,MemNet中的存储/记忆模块包含递归单元和门单元。一个递归单元中的大多数层不会从它们的前面层或存储/记忆模块中接收信息。而在我们提出的RDN中,RDB的输出可以直接访问下一个RDB的每一层。在一个RDB模块中的每个卷积层的信息也会流入所有的后续层(仍然是在该RDB模块内部)。此外,RDB中的局部残差学习改善了信息和梯度的流动以及性能,这将在第5节中演示。第三,如上所述,当前存储/记忆模块并没有充分利用上一个模块及其网络层的输出信息。MemNet虽然采用了HR空间中存储/记忆模块之间的密集连接,但无法从原始LR输入中充分提取层次特征。而我们的RDN在用RDBs提取局部密集特征后,进一步在LR空间中采用全局的方式融合了前面所有层的分层特征。
5.实验结果
该方法的源代码可以在https://github.com/yulunzhang/RDN下载。
5.1设置
Datasets and Metrics.:最近,Timofte等人发布了一个用于图像恢复应用[27]的高质量(2K分辨率)数据集DIV2K。DIV2K由800张训练图像、100张验证图像和100张测试图像组成。我们用800张训练图像训练所有的模型,在训练过程中使用5张验证图像。为了进行测试,我们使用5个标准基准测试数据集:Set5[1]、Set14[33]、B100[18]、Urban100[8]和Manga109[19]。利用变换后YCbCr空间中的Y通道(即亮度)上的PSNR和SSIM[32]对SR结果进行评估。
Degradation Models. :为了充分展示我们提出的RDN的有效性,我们使用三种退化模型来模拟LR图像。第一种方法是双三次插值下采样(简称BI),通过采用Matlab中带有bicubic选项的imresize函数实现。我们使用BI模型模拟具有比例因子×2, ×3和×4的LR图像。第二种方法与[38]相似,使用大小为7×7,标准差为1.6的高斯核对HR图像进行模糊处理。然后用比例因子×3(简称BD)对模糊图像进行下采样。我们进一步以更具挑战性的方式生产LR图像。我们首先对具有比例因子×3的HR图像进行双三次下采样,然后添加噪声级别为30的高斯噪声(简称DN)(这里就应该是第三种模型)。
Training Setting.:按照[17]的设置,在每个训练批次中,我们随机抽取16个LR RGB patch,每个patch大小为32 × 32。我们随机对补丁进行水平或垂直翻转以及旋转90°的数据增强。一千次反向传播迭代构成了一个epoch。我们用Torch7框架实现我们的RDN,并用Adam优化器[12]更新它。所有层的学习率初始化为 1 0 − 4 10 ^{- 4} 10−4,每200个epoch降低一半。使用Titan Xp GPU训练一个RDN模型200个epoch大约需要1天的时间。
5.2 D, C, G的研究。
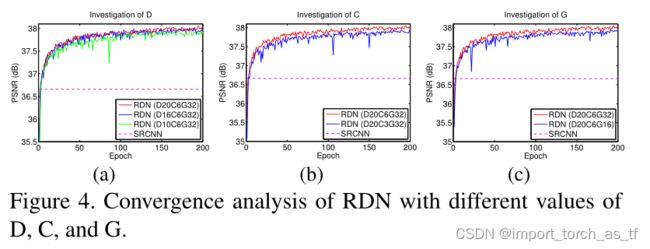
在本小节中,我们研究了基本的网络参数:RDB的数量(表示为D),每个RDB中的Conv层的数量(表示为C),以及增长率(表示为G)。我们以SRCNN[3]的性能为参考。如图4(a)和4(b)所示,D或C越大,性能越好。这主要是因为随着D或C的增大,网络变得更深。由于我们提出的局部特征融合(LFF)允许更大的G,我们也观察到更大的G(见图4©)有助于更好的性能。另一方面,具有较小D、C或G的RND在训练中会出现一些性能下降,但RDN仍然会优于SRCNN[3]。更重要的是,我们的RDN允许更深和更宽的网络,从中提取更多的层次特征,以获得更高的性能。
5.3 消融研究

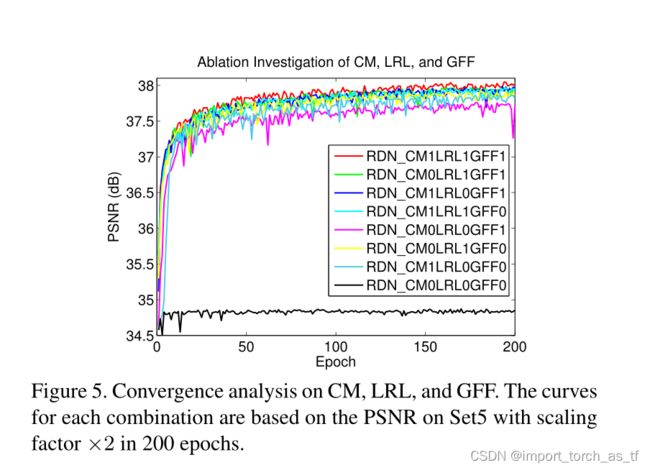
表1显示了对连续存储(CM)、局部残余学习(LRL)和全局特征融合(GFF)效果的消融研究。消融研究中的8个网络具有相同的RDB数(D = 20)、每个RDB中的Conv层数(C = 6)和增长率(G = 32)。我们发现本地特征融合(LFF)是训练这些网络的必要条件,因此LFF在默认情况下不会被移除。基线模型(表示为RDN_CM0LRL0GFF0)是在没有CM、LRL或GFF的情况下获得的,性能非常差(PSNR = 34.87 dB)。这是由于训练[3]困难造成的,也证明了在一个非常深的网络中堆叠许多基本的密集模块[7]不会产生更好的性能。
然后我们将CM、LRL或GFF中的一个添加到基线模型中,结果分别是RDN _CM1LRL0GFF0、RDN_CM0LRL1GFF0和RDN_CM0LRL0GFF1(从表1中的第2到第4个)。我们可以验证每个组件都可以有效地提高基线模型的性能。这主要是因为每个组件都有助于信息和梯度的流动。
我们进一步在基线模型上同时添加两个组件,分别得到RDN_CM1LRL1GFF0、RDN _CM1LRL0GFF1和RDN_CM0LRL1GFF1(从表1中的第5个到第7个)。可以看出,同时添加两个组件的性能优于添加一个组件。当我们同时使用这三个组件(表示为RDN_CM1LRL1GFF1)时,可以看到类似的现象。使用三个组件的RDN性能最好。
我们还可以在图5中看到这8种组合(网络)的收敛过程。收敛曲线与上述分析一致,表明CM、LRL和GFF可以进一步稳定训练过程而不会有明显的性能下降。这些定量和可视化分析证明了我们提出的CM、LRL和GFF的有效性和效益。
5.4 BI退化模型的结果
利用BI退化模型模拟LR图像被广泛应用于图像SR设置中。对于BI退化模型,我们将我们的RDN与其他6种最先进的图像SR方法进行比较,这些方法分别是:SRCNN[3]、LapSRN[13]、DRRN[25]、SRDenseNet[31]、MemNet[26]和MDSR[17]。与[30,17]类似,我们也采用了自集成策略[17]来进一步改进我们的RDN,并将自集成RDN表示为RDN+。如上所述,更深更宽的RDN会带来更好的性能。另一方面,由于大多数比较方法在每个Conv层只使用大约64个滤波器,为了比较的公平,我们使用D = 16, C = 8, G = 64来报告RDN的结果。这里跳过EDSR[17],因为它每个Conv层使用更多的过滤器(例如,256),导致了非常宽的网络和大量的参数。然而,我们的RDN也可以达到与EDSR[17]相当甚至更好的结果。
表2显示了×2, ×3和×4 SR的定量比较。SRDenseNet[31]的结果引用自他们的论文。与反复出现的CNN模型(SRDenseNet[31]和MemNet[26])相比,我们的RDN在所有比例因子下的所有数据集上表现最好。这表明我们的残差密集模块(RDB)比SRDensenet[31]中的密集模块和MemNet[26]中的存储/记忆模块更有效。与其他模型相比,我们的RDN在大多数数据集上也获得了最好的平均结果。具体来说,对于比例因子×2,我们的RDN在所有数据集上表现最好。当比例因子变得更大(例如,×3和×4), RDN将无法保持与MDSR[17]类似的优势。这种情况主要有三个原因。第一,MDSR更深(160 vs . 128),大约有160层来提取LR空间中的特征。第二,MDSR利用多尺度输入,就像VDSR所做的[10]一样。第三,MDSR使用更大的输入补丁尺寸大小(65 vs . 32)进行训练。由于Urban100中的大多数图像都包含自相似结构,在训练时,更大的训练输入补丁尺寸可以让一个非常深的网络更好地利用大的感受野来获取更多的信息。因为我们主要关注RDN的有效性和公平比较,所以我们没有使用更深的网络,多尺度的信息,或更大的输入补丁大小。此外,我们的RDN+可以通过自集成[17]实现进一步的改进。

在图6中,我们显示了×4尺度上的视觉比较。对于图像“119082”,我们观察到大多数比较方法都会产生明显的伪影和模糊的边缘。相比之下,我们的RDN可以恢复更锐利、更清晰的边缘,更接近ground truth。对于图像“’ img _043 '中的小线(红色箭头所指),所有比较方法都无法恢复它。而我们的RDN可以明显恢复。这主要是因为RDN通过密集特征融合使用了分层特征。
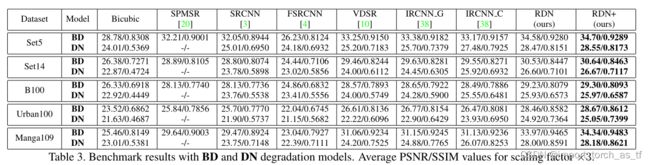
5.5 BD和DN退化模型的结果


与[38]一样,我们还展示了BD退化模型的SR结果,并进一步介绍了DN退化模型。我们的RDN与SPMSR[20]、SRCNN[3]、FSRCNN[4]、VDSR[10]、IRCNN_G[38]和IRCNN_C[38]进行比较。我们为每种退化模型重新训练SRCNN、FSRCNN和VDSR方法。表3给出了在Set5、Set14、B100、Urban100和Manga109数据集上比例因子×3时的平均PSNR和SSIM结果。我们的RDN和RDN+在所有具有BD和DN退化模型的数据集上表现最好。与其他最先进的方法相比,性能的提高与图7和图8中的可视化结果一致。
对于BD退化模型(图7),使用插值LR图像作为输入的方法会产生明显的伪影,无法去除模糊伪影。相比之下,我们的RDN抑制模糊伪影并恢复更尖锐的边缘。这一对比表明,从原始LR图像中提取层次特征可以减轻模糊伪影。同时也证明了RDN对BD退化模型的强大能力。
对于DN退化模型(图8),其中LR图像被噪声损坏,丢失了一些细节。我们观察到噪声细节很难用其他方法恢复[3,10,38]。然而,我们的RDN不仅可以有效地处理噪声,还可以恢复更多的细节。这一对比表明RDN适用于联合图像去噪和SR。这些与BD和DN退化模型的结果证明了我们的RDN模型的有效性和鲁棒性。
5.6 Super-Resolving真实的图片

我们还对两个具有代表性的真实世界图像“chip”(244×200像素)和“hatc”(133×174像素)[41]进行了SR实验。在这种情况下,原始HR图像不可用,退化模型也未知。我们将RND与VDSR[10]、LapSRN[13]和MemNet[26]进行比较。如图9所示,我们的RDN比其他最先进的方法恢复了更加锐利的边缘和更精细的细节。这些结果进一步说明了从原始输入图像中学习密集特征的好处。分层特征对不同或未知的退化模型表现稳健。
6.总结
在本文中,我们提出了一种非常深的残差密集网络(RDN)用于图像SR,其中残差密集块(RDB)作为基本构建模块。在每个RDB中,每个层之间的密集连接允许充分使用本地层(的层次特征)。局部特征融合(LFF)不仅能够稳定更宽网络的训练过程,而且能自适应地控制来自当前和之前RDBs模块中的信息保存。RDB进一步允许前面的RDB模块和当前RDB模块中的每一个卷积层之间直接连接,从而形成一个连续存储(CM)机制。局部残差学习(LRL)进一步改善了信息和梯度的流动。此外,我们提出了全局特征融合(GFF)来提取LR空间中的层次特征。通过充分利用局部和全局特征,我们的RDN实现了密集的特征融合和深度监督。我们使用相同的RDN结构来处理三种退化模型和真实世界的数据。大量的基准评估很好地证明了我们的RDN比现有的方法更有优势。
7.感谢
该研究部分由NSF IIS奖1651902、ONR Y yong研究员奖N00014-14-10484和美国陆军研究办公室奖W911NF-171-0367支持。