DETR:使用transformer进行端到端目标检测
论文地址:https://arxiv.org/pdf/2005.12872.pdf
目录
0、摘要
1、引言
2、相关工作
2.1、集合预测
2.2、transformers和并行解码
2.3、目标检测
基于集合的损失:
循环检测器:
3、DETR模型
3.1、目标检测集合预测损失
3.2、DETR架构
4、实验
5、总结
0、摘要
提出了一种新的目标检测方法,将其视为直接的集合预测问题。所提方法简化了检测pipeline,有效地移除了对手工设计组件的依赖,如NMS、Anchor生成等对任务相关的先验知识显示编码的程序。新框架的主要成分被称作DEtection TRansformer或者DETR,包括一个用于强制one-to-one预测的基于集合的全局损失,以及一个编解码结构的transformer。给定一小组固定的目标queries,DETR推理出目标之间的关系以及图像的全局上下文,直接并行地输出最终的预测集。该新模型概念简单,且不像其他检测器那样需要一些特殊的库。DETR在准确率和运行时性能方面,在COCO目标检测数据集上,与成熟、高度优化的Faster-RCNN baseline相当。此外,DETR还可以很容易泛化,以统一的方式产生全景分割,并优于一些有竞争力的baseline。
1、引言
目标检测的目的是为没一个感兴趣目标预测一组边框和类别标签。当前检测器通常使用一种检测的方式来定位这些集合预测任务:在一个proposals、anchors或者中心点的大集合中定义代理回归和分类问题,它们的性能明显会受到对大量相似预测去重的后处理、anchor集的设计以及启发式地将目标框分配给anchor等方法所影响。为了简化这些pipeline,提出了一种直接的集合预测方法来绕过这些代理任务。这种端到端的理念在很多复杂结构预测任务,如机器翻译、语音识别上有了重大进步,但在目标检测领域尚无。先前的一些端到端尝试,要么增加了其他形式的先验知识,要么在有挑战的基准集上没有明显优势。本文的目的就是弥补这种差距。
本文通过将目标检测视为一种直接的集合预测问题,简化了训练pipeline。使用了一种基于transformer的encoder-decoder结构,而transformer在序列预测方面非常流行。transformer中的self-attention机制明确地对序列中所有元素对的相关性进行建模,这使得这些结构非常适合对集合预测进行特殊约束,如重复预测的去重。
所提出的DETR,结构如图1所示,一次性预测出所有目标,而且使用一个集合损失函数进行端到端训练,该损失函数在预测和GT目标之间执行双边匹配。DETR通过去掉很多手工设计用于编码先验知识的组件,如空间anchors或者NMS等,来简化目标检测的pipeline。与现有的大多数目标检测模型不同,DETR不需要任何自定义的layers,因此可以在任何包含标准CNN和transformer分类的的框架中轻松移植。
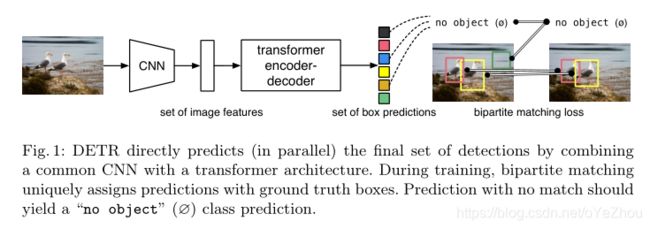
与先前大多数的直接集合预测研究不同,DETR是双边匹配损失和并行解码(非自回归)的transformer的结合。相反的,先前工作聚焦于带有RNNs的自回归解码。DETR的匹配损失函数将一个预测和一个GT唯一匹配,并且预测对象之间的排列是不变的,所以可以并行计算。
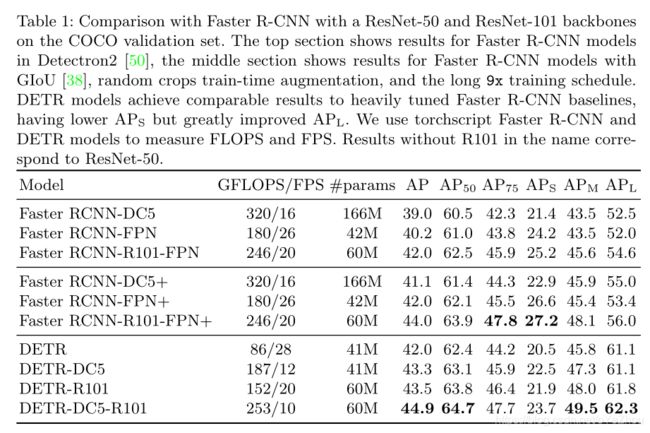
作者在COCO上对DETR进行了评估,与热门的Faster RCNN进行了对比。Faster RCNN历经多次迭代,其性能已远超原始版本。实验表明,DETR可以达到与Faster RCNN同等性能。更准确地说,DETR在大型物体上表现出明显更好的性能,这可能与transformer的non-local计算有关;但是,在小目标上性能却稍差。希望未来的工作能够利用FPN等方式改进这个不足。
DETR的训练方式在很多方面不同于标准的目标检测器,其需要超长的训练计划,并需要利用transformer中的辅助解码。作者彻底探索了哪些组件对性能是至关重要的。
DETR的设计精神很容易扩展到更复杂的任务。在我们的实验中,我们证明了在预先训练的DETR之上训练的简单分割头优于全景分割的竞争基线,这是最近获得流行的具有挑战性的像素级识别任务。
2、相关工作
DETR建立在很多其他领域的研究内容:集合预测中的双边匹配损失、基于transformer的encoder-decoder结构、并行解码、目标检测方法。
2.1、集合预测
没有典型的深度学习模型可以直接预测集合。基础的集合预测任务是多标签分类,这种one-to-rest的方法是不适合应用于诸如目标检测这类元素之间是潜在结构关系的问题的。大多现有检测器,都是通过NMS之类的方法来对重复预测去重,而直接的集合预测是无后处理的,可以通过对所有预测元素之间的交互进行建模的全局推理机制来避免冗余。对于常数大小的集合预测,密集全连接网络足以,但是很昂贵。一个通用的方法是,使用自回归序列模型,如RNNs。在所有情况下,损失函数应该是预测元素排序不变的。通常的解决方案是基于匈牙利算法设计一个损失函数,以找到预测结果和GT之间的双边匹配。这强制使得排列不变,并保证了每个目标元素有唯一匹配。作者沿用了双边匹配损失的方法。然而,与之前的大多数工作相比,本文不再使用自回归模型,而是使用带有并行解码的transformer。
2.2、transformers和并行解码
transformers是在机器翻译领域作为基于注意力的构造块被提出的。注意力机制是从整个输入序列中聚合信息的神经网络层。transformers引入了自注意力层,这种层类似于Non-local,都是扫描序列中的每个元素,并通过从整个序列中聚合信息来对元素进行更新。这种基于注意力的模型的一个优势是其全局计算和完全记忆,这使得它们更加适用于长序列的RNNs。transformers现在已经替代RNNs,成了NLP、语音识别和CV中很多任务的解决方案。
transformers首次应用在自回归模型中,沿着早期的序列到序列模型,一对一地生成输出tokens。然而,在音频、机器翻译、词表示学习以及最近的语音识别领域,由于前置推理代价过高(与输出长度正相关,且很难批处理),因此并行序列生成得以发展。作者结合transformers和并行解码,以便在计算成本和执行集预测所需的全局计算能力之间进行适当的权衡。
2.3、目标检测
当代大多数目标检测方法都是依据一些初步猜测来做预测的。两阶段检测器预测关于proposals的boxes,单阶段检测器预测anchors或者一个可能物体中心的网格。近期的工作证明了,这些系统的最终性能在很大程度上取决于这些初始猜测的准确设置方式。本文方法有能力通过使用唯一box来预测对应的输入图像而不是anchor直接预测检测集合,来去掉这些手工设计的组件,并简化检测过程。
基于集合的损失:
一些目标检测器使用了双边匹配损失,然而,这些早期的深度学习模型中,预测结果中不同元素之间的关系是仅通过卷积或者全连接层进行建模的,而且手工设计的NMS后处理可以提高其性能。近期的检测器都是在GT换个预测结果之间使用非唯一分配规则,然后再接一个NMS。
可学习的NMS和关系网络使用注意力显式建模了不同预测结果之间的关系。由于使用了直接的集合损失,它们可以不需要任何后处理。然而,这些方法利用了额外的手工设计的上下文特征,如proposal box坐标,来有效的建模检测之间的关系,而本文所寻找的解决方案是能够降低将先验知识编码进网络中的。
循环检测器:
最接近本文方法的是端到端集合预测的目标检测方法和实例分割。它们基于CNN结构,使用了具有encoder-decoder结构的双边匹配损失,来直接生成一个边框集合。然而,这些方法仅仅在一些小的数据集上进行了评估,并不能与当前的baselines相抗衡。特别地,它们是基于自回归模型(精确来说就是RNNs)的,所以它们没能利用最近的带有并行解码的transformers。
3、DETR模型
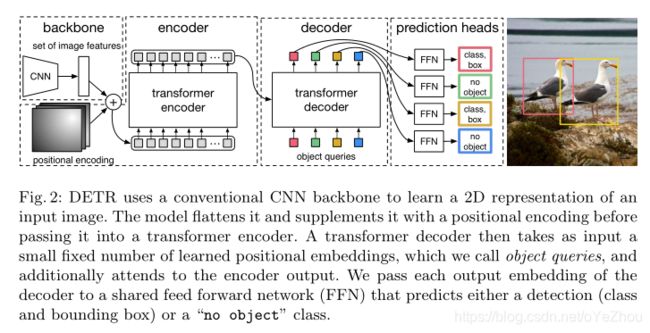
目标检测中,进行直接的集合预测有两个必不可少的成分:(1)一个集合预测损失,用于在预测和GT之间进行强制性的唯一匹配;(2)一个能够一次性预测对象集合并建模其关系的架构。DETR的架构如图2:
3.1、目标检测集合预测损失
DETR在一次性通过解码器时,推导出一个尺寸固定的具有N个预测结果的集合,N是一个远远超出一个图像中常见目标个数的值。训练的主要困难之一是根据GT对预测结果(类别、位置、尺寸)评分。所提出的损失在预测结果和GTs之间产生了一个最优的双边匹配,然后优化具体目标(边框)的损失。
定义 是GTs,
是GTs,![]() 为N个预测结果。假设N是超过图像中的目标个数的值,将也视为长度为N并使用
为N个预测结果。假设N是超过图像中的目标个数的值,将也视为长度为N并使用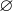 进行padding(填充了的位置视为no object)的集合。为了找了这两个集合之间的双边匹配,需要寻找
进行padding(填充了的位置视为no object)的集合。为了找了这两个集合之间的双边匹配,需要寻找![]() 这N个元素的一个排列,使其代价最低:
这N个元素的一个排列,使其代价最低:
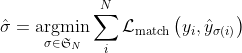 (1)
(1)
其中,![]() 是一个成对的关于GT和预测结果的匹配损失。该优化任务,使用匈牙利算法进行计算时高效的。
是一个成对的关于GT和预测结果的匹配损失。该优化任务,使用匈牙利算法进行计算时高效的。
上述匹配损失![]() ,既考虑了类别预测,又考虑了GTs和预测结果之间boxes的相似性。GTs中每个元素
,既考虑了类别预测,又考虑了GTs和预测结果之间boxes的相似性。GTs中每个元素 可以被视为
可以被视为![]() ,其中
,其中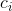 代表目标类别标签(可能为),
代表目标类别标签(可能为),![]() 是一个向量,代表了GT box归一化的中心点和宽高坐标,也即其格式为xywh。对于第
是一个向量,代表了GT box归一化的中心点和宽高坐标,也即其格式为xywh。对于第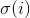 个预测结果,定义的预测概率为
个预测结果,定义的预测概率为![]() ,定义预测box为
,定义预测box为![]() 。基于上述定义的符号,定义
。基于上述定义的符号,定义![]() 为:
为:![]() 。
。
这种寻找匹配的过程与现代检测器中用于匹配proposals或anchors到GTs对象的启发式分配规则起着相同的作用。主要区别在于,我们需要寻找一个一对一没有冗余的直接集合预测。
第二步,就是计算损失函数了,也就是计算上一步得到的所有匹配对之间的匈牙利损失。 我们将损失函数定义为与常见目标检测器相似的形式,也即,一个用于类别预测的负对数似然和一个边框损失的线性组合:
(2)
其中,![]() 是公式(1)中计算得到的优化分配。在实际使用时,我们对
是公式(1)中计算得到的优化分配。在实际使用时,我们对![]() 时的对数-概率项进行10倍降权,以保证类别平衡,这与Faster RCNN中通过二次采样进行正负样本平衡的训练方式类似。注意,对象与∅的匹配代价不依赖于预测,在这种情况下代价为常数。在匹配代价中,我们使用概率
时的对数-概率项进行10倍降权,以保证类别平衡,这与Faster RCNN中通过二次采样进行正负样本平衡的训练方式类似。注意,对象与∅的匹配代价不依赖于预测,在这种情况下代价为常数。在匹配代价中,我们使用概率![]() 来代替对数概率。这使得类预测项可以与
来代替对数概率。这使得类预测项可以与![]() 公约(如下所述),并且经过观察能得到更好的经验性能。
公约(如下所述),并且经过观察能得到更好的经验性能。
Bounding box loss:匹配代价和匈牙利损失的第二部分是![]() ,其用于给边框打分。与很多其他检测器基于一些初始猜测来做边框预测不同,我们的box预测是直接的。虽然这种方法简化了其应用,但是带来了损失的相对缩放的问题。常用的L1损失在不同大小的boxes之间具有不同的规模,即使其相对误差较小。为了缓解该问题,我们使用L1损失和尺度不变的广义IOU损失进行线性组合。总体来说,我们的box损失
,其用于给边框打分。与很多其他检测器基于一些初始猜测来做边框预测不同,我们的box预测是直接的。虽然这种方法简化了其应用,但是带来了损失的相对缩放的问题。常用的L1损失在不同大小的boxes之间具有不同的规模,即使其相对误差较小。为了缓解该问题,我们使用L1损失和尺度不变的广义IOU损失进行线性组合。总体来说,我们的box损失![]() 定义为:
定义为:![]() ,其中
,其中![]() 属于超参。这两种损失通过一个batch中目标的数量进行归一化。
属于超参。这两种损失通过一个batch中目标的数量进行归一化。
3.2、DETR架构
DETR的整体架构如图2,其包括三个主要组件:一个CNN的backbone用于提取紧凑的特征表示,一个encoder-decoder transformer,以及一个简单的前馈网络(FFN)用于做最终的检测预测。
与很多其他的当代检测器不同,DETR可以应用于很多深度学习框架中,仅仅需要几百行代码。在Pytorch中使用DETR,只需不到50行代码。
Backbone:从一个初始的图像![]() 开始,送入一个CNN的backbone生成一个低分辨率的激活map
开始,送入一个CNN的backbone生成一个低分辨率的激活map ![]() ,这里设为:
,这里设为:![]() 。
。
Transformer encoder:首先使用一个1*1卷积对高级激活map![]() 进行通道降维,从C到一个小的值d,得到一个新的feature map
进行通道降维,从C到一个小的值d,得到一个新的feature map ![]() 。encoder期望的输入是一个序列,因此,我们将
。encoder期望的输入是一个序列,因此,我们将![]() 的空间维度(宽高)压缩为一维,也即得到一个
的空间维度(宽高)压缩为一维,也即得到一个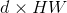 的feature map。每个编码器层都有一个标准架构,由一个多头自注意模块和一个前馈网络(FFN)组成。由于transformer体系结构是排列不变的,我们用固定位置编码来补充它,这些编码被添加到每个注意力层的输入中。
的feature map。每个编码器层都有一个标准架构,由一个多头自注意模块和一个前馈网络(FFN)组成。由于transformer体系结构是排列不变的,我们用固定位置编码来补充它,这些编码被添加到每个注意力层的输入中。
Transformer decoder:解码器也遵循了transformer的标准结构,利用多头自注意机制和编码器-解码器注意机制对尺寸为d的N个嵌入进行转换。与原来的转换器不同的是,我们的模型在每个解码器层并行解码N个对象,而非自回归模型。由于解码器也是排列不变的,因此N个输入嵌入必须不同才能产生不同的结果。这些输入嵌入是学习到的位置编码,我们称之为对象查询,类似于编码器,我们将它们添加到每个注意层的输入。N个对象查询被转换成由解码器嵌入的输出。然后通过前馈网络FFN将它们独立解码为框坐标和类标签,从而产生N个最终预测。由于使用了自注意力、 encoder-decoder,该模型使用所有对象之间的成对关系来对所有对象进行全局推理,同时能够使用整个图像作为上下文。
FFNS:最终的预测是由一个带有ReLU激活函数和隐藏维数d的3层感知器和一个线性投影层来计算的。FFN预测归一化的中心坐标、输入图像框的高度和宽度,线性层使用softmax函数预测类标签。由于我们预测的边框个数固定为N,而N又是远大于实际的目标个数的值,因此就多了一个额外的类别,表示无目标。这个类在标准的对象检测方法中扮演类似于“background”类的角色。
Auxiliary decoding losses:在训练过程中,我们发现在解码器中使用辅助损失是很有帮助的,特别是帮助模型输出正确的每类的目标个数。我们在每一层decoder之后增加了预测FFN和匈牙利损失,所有FFN共享参数。并使用了一个额外的共享层来归一化来自不同decoder层的送入FFN的输入。
4、实验
5、总结
本文主要是基于transformers和双边匹配损失设计了一种新的目标检测范式——DETR,可以直接进行one-to-one预测。在COCO数据集上,DETR与高度优化的Faster RCNN性能相当。DETR应用简单,且拥有固定结构,可方便的扩展到全景分割等领域,并能达到不错的效果。此外,在大型目标的效果上, 是由于Faster RCNN的,这可能是因为DETR中的大量自注意力机制的应用使得模型能够捕获全局上下文信息,从而对大目标友好。
但是,DETR同样也面临挑战,其在训练、优化以及小目标检测方面还有待提高。鉴于其刚开始研究,后续应该会有各种改进方法来解决这些问题。