实战营笔记 - day 2
图像分类与基础视觉模型
图像分类 (识别给定图像中的物体)
1.传统算法:设置维度巨大的特征向量,通过对特征向量的学习(特征工程),进行分类。
【但错误率较高,> 20%】
2. 深度学习:通过迭代特征提取的过程(可学习的特征提取),获得最合适的特征进行分类
【错误率低】
这种可学习的特征提取中较为突出的:
1)卷积神经网络(CNN)中的卷积核,不同卷积核可以获得不同的特征图。

2)Transformer中的多头注意力

卷积神经网络(CNN)
AlexNet使用了5个卷积层,3个全连接层,并使用了RELU激活函数提高了精度。

VGG使用了更小的卷积核(3x3)和1像素的边界填充(padding)
GoogleNet使用单层全连接层用做最后的分类,节省了大量参数。
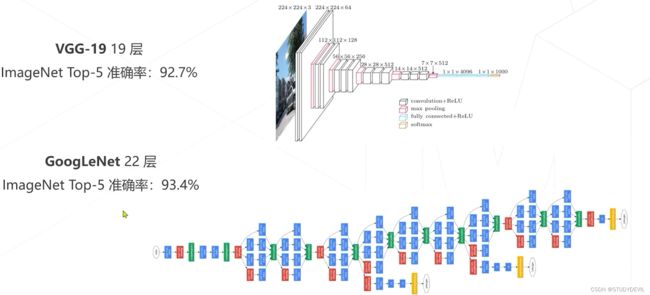
残差网络(ResNet):由于在实验中发现卷积层并非越多越好,一些参数可能会让模型准确率下降,因此开发出残差网络。(如果使用某些卷积层后精度下降,则舍去这些卷积层)

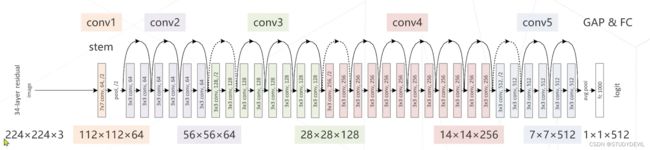

ResNet后续改进:
ResNet B/C/D 残差模块的局部改进
ResNeXt 使用了分组卷积,降低参数量
SEResNet 引入了注意力机制
更强的图像分类模型
神经结构搜索 (Neural Architecture Search)
NASNet (2017)、MnasNet (2018)、EfficientNet (2019) 、RegNet (2020)

Vision Transformers

ConvNeXt (将 Swin Transformer 的模型元素迁移到卷积网络中,性能反超 Transformer)

轻量化卷积神经网络
卷积的参数量:所有卷积核的所有权重参数+所有偏置参数
卷积的计算量:输出层总参数 x 卷积核的参数
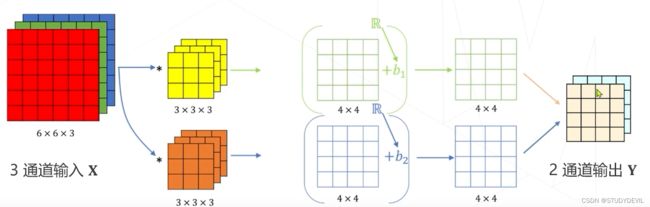
降低模型参数量和计算量的方法:
1)降低通道数:ResNet 中的bottleneck使用1x1卷积将256个通道转为64个通道来减少计算量。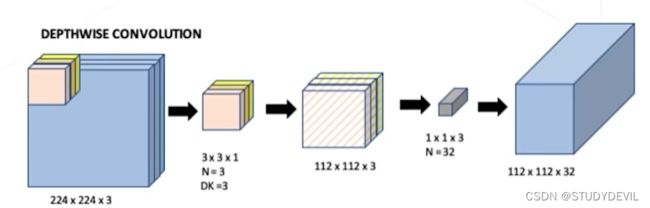

2)减小卷积核的尺寸:GoogleNet使用不同大小的卷积核(文章认为部分卷积核无需3x3那么大)

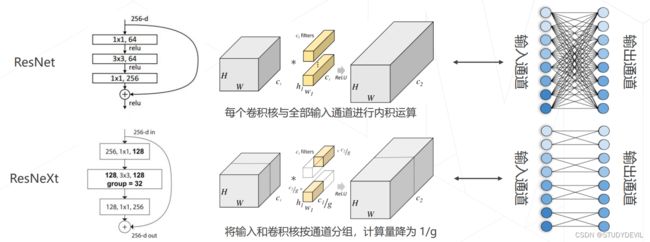
3)分组卷积ResNeXt
传统的输出层是全连接,参数很多;ResNeXt是组内全连接,参数较少
Vision Transformers
注意力机制(attention mechanism)
与卷积的相同点:
后层特征是空间领域内的前层特征的加权求和;权重越大,对应位置的特征就越重要
与卷积的不同点:
卷积:权重是可学习的参数,但与输入无关;
【只能通过多层卷积才能实现远距离关系,否则只能建模局部关系】
注意力机制:权重是输入的函数
【可以不局限于邻域,显式建模远距离关系】

注意力机制的实现
Q 代表输入层(x,y)位置的变量
K 代表输入层的全部关键信息
weight 通过Q·K获得(x,y)位置在输入图片的权重
V 代表输入层的全部信息
Output 是通过 weight·V 获得的(x,y)位置在整个输入层中的特征值

多头注意力机制 Multi-head (Self-)Attention
即使用多组Q K V来获得输出的特征值矩阵


缺点:由于输入图片一般都很大,所以此方法计算量十分巨大
Swin Transformer
Vision Transformer 的特征图是是直接下采样 16 倍得到的,后面的特征图也是维持这个下采样率不变, 缺少了传统卷积神经网络里不同尺寸特征图的层次化结构。所以,Swin Transformer 提出了分层结构 (金字塔结构)Hierarchical Transformer。
同时,相对于 Vision Transformer 中直接对整个特征图使用多头注意力机制 Multi-Head Self-Attention,Swin Transformer 将特征图划分成了多个不相交的区域 (Window),将 Multi-Head Self-Attention 计算限制在窗口内,这样能够减少计算量的,尤其是在浅层特征图很大的时候
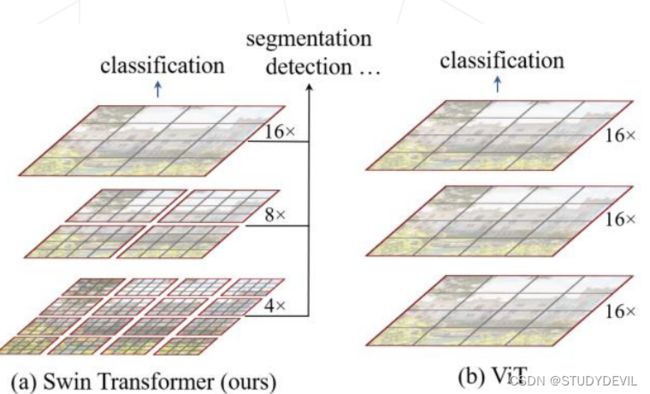
由于将 Multi-Head Self-Attention 计算限制在窗口内,窗口与窗口之间无法进行信息传递。所以, Swin Transformer 又提出了 Shifted Windows Multi-Head Self-Attention (SW-MSA) 的概念,即第 + 1 层的窗 口分别向右侧和下方各偏移了半个窗口的位置。那么,这就让信息能够跨窗口传递。

模型学习
1. 监督学习:标注 → 定义损失函数 → 训练模型 【标注的代价很高】
2. 自监督学习:设计辅助任务自学习特征 → 训练模型
监督学习(重点概要)

内层循环:黑色虚线内循环直至Mini Batch计算完
外层循环:依次采样直至全部计算完
初始化策略:即权重和偏置的初始化
1)随机初始化

2)用训练好的模型进行初始化,只需替换预训练模型的分类头进行微调训练 (finetune)
学习率和优化器:适当的选择可以有效提高准确率
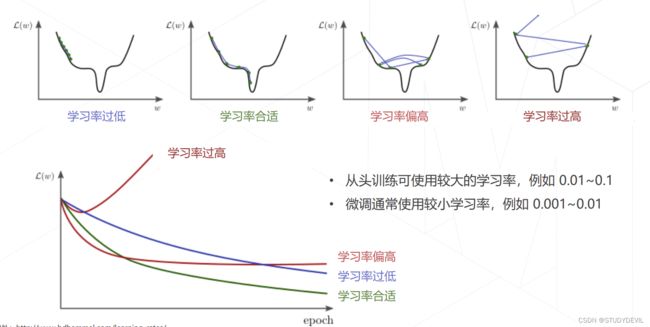
学习率策略:
1. 学习率退火Annealing :在训练初始阶段使用较大的学习率,损失函数稳定后下降学习率
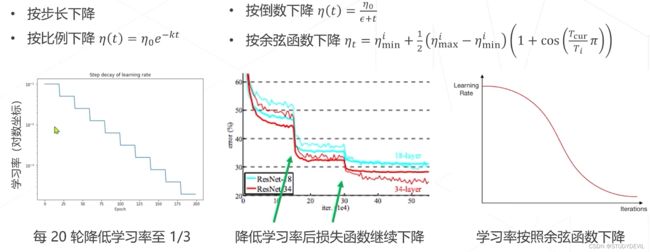
2. 学习率升温 Warmup:在训练前几轮学习率逐渐上升,直到预设的学习率,以稳定训练的初始阶段

优化策略:
1. Linear Scaling Rule:
经验性结论:针对同一个训练任务,当 batch size 扩大 倍时,学习率也应对应扩大 倍
直观理解:这样做可以保证平均每个样本带来的梯度下降步长相同
2. 自适应梯度算法: 不同的参数需要不同的学习率,根据梯度的历史幅度自动调整学习率
3. 正则化与权重衰减 Weight Decay:在损失函数中引入正则化项,以鼓励训练出相对简单的模型
4. 早停 Early Stopping:将训练数据集划分为训练集和验证集,在训练集上训练,周期性在验证集上测试分类精度;当验证集的分类精度 达到最值时,停止训练,防止过拟合
5. 模型权重平均 EMA:基础假设:模型在优化末期会在极小值周围"转动";因此平均后的参数更接近极小值点
6. 模型权重平均 Stochastic Weight Averaging:原理同 EMA,但在训练末期使用较高的学习率,在损失平面的平坦区域上做更多的探索,最后平均模型
数据增强 Data Augmentation
训练泛化性好的模型,需要大量多样化的数据, 而数据的采集标注是有成本的 图像可以通过简单的变换产生一系列"副本",扩充训练数据集 数据增强操作可以组合,生成变化更复杂的图像

组合数据增强 AutoAugment & RandAugment

组合图像 Mixup & CutMix

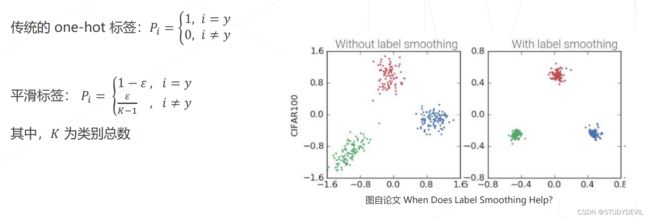
标签平滑 Label Smoothing
动机:类别标注可能错误或不准确,让模型最大限度拟合标注类别可能会有碍于泛化性
做法:引入平滑参数 ,降低标签的"自信程度"
模型相关策略
丢弃层 Dropout:神经网络在训练时会出现共适应现象 (co-adaption),神经元之间产生高度关联,导致过拟合。训练时随机丢弃一些连接,破坏神经元之间的关联,鼓励学习独立的特征。推理(分类)时使用全连接;此策略常用于全连接神经网络,通常不与 BN 混用
随机深度 Stochastic Depth:利用不同的深度训练,最终相当于潜在地融合了多个不同深度的网络,提升了性能
自监督学习

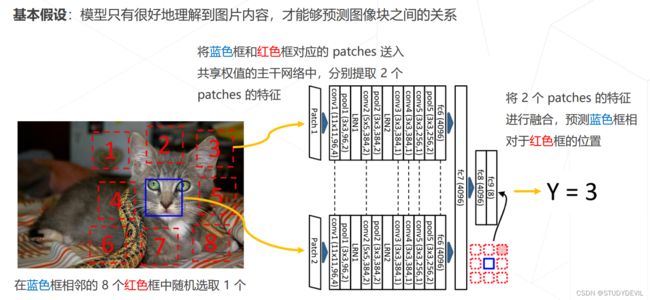
Relative Location
SimCLR

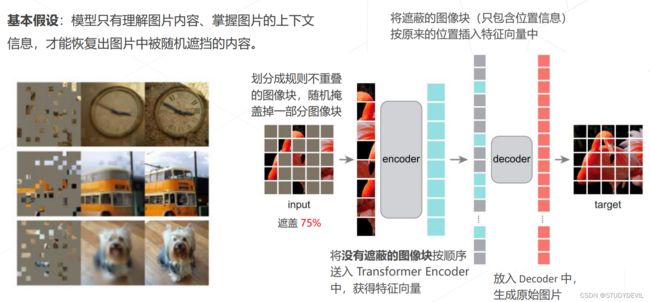
Masked autoencoders
此笔记基于OpenMMLab 实战训练营课程,仅用于学习。