目标检测之--mmdetection使用
1、构建环境
创建虚拟环境
conda create -n mmdetection python=3.7
进入虚拟环境
conda activate mmdetection
安装torch/torchvision
conda install pytorch torchvision -c pytorch
安装mim
pip install -U openmim
安装mmcv-full ## 注意本地环境的cuda与mmcv-full的版本对应
mim install mmcv-full
linux安装有git+网络畅通,可以直接下载mmdetection
git clone -b [version] https://github.com/open-mmlab/mmdetection .git
or 没网的情况 则下载对应的.zip包进行解压
进入mmdetection
cd mmdetection
pip install -v -e. or python setup.py develop
如果缺陷包,可以安装requirement.txt里面的对应包
pip install -r requirement.txt
按照上述步骤可搭建完成mmdetection 的conda基础环境,可使用该环境进行测试和训练
2、制作数据集
- 下载并安装labelimg
可使用以下链接进行下载,github官方labelimg下载地址 - 将labelimg添加到pycharm
通过将labelimg添加为pycharm的外部工具,可以更加方便的使用
如下,在file->settings->tools->external tools 点击+号,将下载下来的labelimg文件夹下的labelimg.exe链接叫你去即可
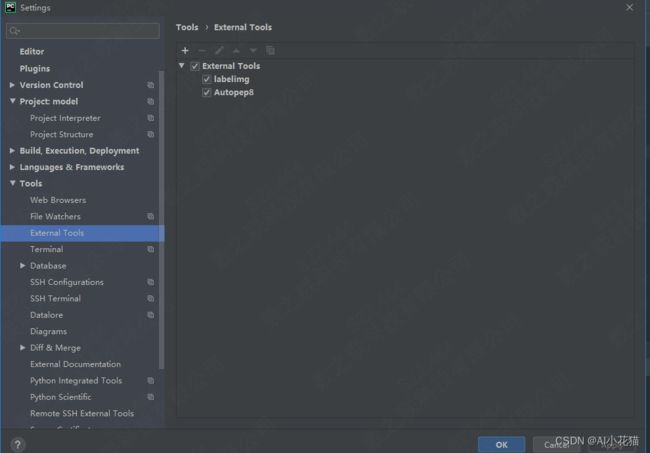
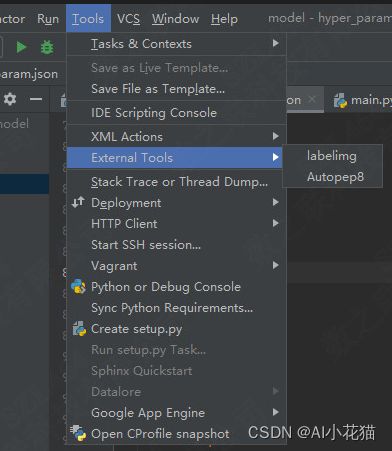
然后每次打开pycharm,可以通过如下方式进行打开labelimg:tools->external tools->labelimg打开
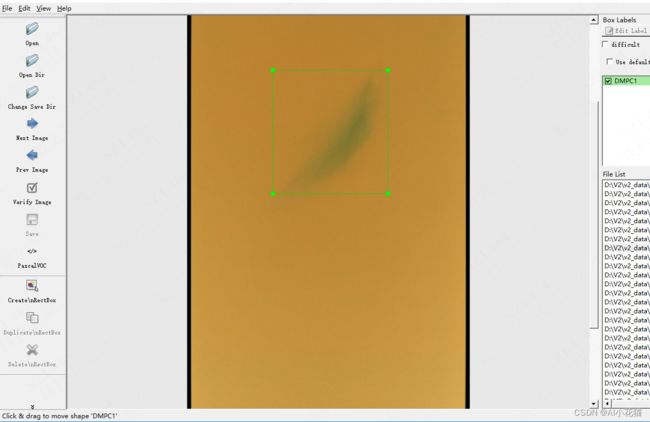
- 标注数据
打开labelimg标注软件,选择PascalVOC模式,标注所需数据,如下所示:
- 利用标注数据生成coco数据集
使用如下脚本
from sklearn.model_selection import train_test_split
import xml.etree.ElementTree as ET
import os, json
from utils import file_name_ext
import argparse
class pascalVoc2Coco(object):
def __init__(self, sample_root, xml_img_in_same_folder=True):
self.sample_root = sample_root
self.xml_img_in_same_folder = xml_img_in_same_folder
self.img_relative_paths = []
self.xml_relative_paths = []
self.get_img_relative_paths()
self.get_xml_relative_paths()
self.image_labels = [item.split('/')[0] for item in self.xml_relative_paths]
def get_img_relative_paths(self):
for root, dirs, files in os.walk(self.sample_root):
for file in files:
if file.split('.')[-1] not in ['jpg','jpeg','JPG','png','PNG']:
continue
filepath = os.path.join(root, file)
file_rel_path = os.path.relpath(filepath, self.sample_root)
self.img_relative_paths.append(file_rel_path)
def get_xml_relative_paths(self):
can_used_img_rel_path = []
for jpg_rel_path in self.img_relative_paths:
xml_rel_path = os.path.splitext(jpg_rel_path)[0] + '.xml'
if not self.xml_img_in_same_folder:
xml_rel_path = xml_rel_path.replace('images', 'labels')
if os.path.exists(os.path.join(self.sample_root, xml_rel_path)):
self.xml_relative_paths.append(xml_rel_path)
can_used_img_rel_path.append(jpg_rel_path)
else:
print('no xml for img-> {}'.format(jpg_rel_path))
self.img_relative_paths = can_used_img_rel_path
image_id = 10000000
bounding_box_id = 10000000
@staticmethod
def get_current_image_id():
pascalVoc2Coco.image_id += 1
return pascalVoc2Coco.image_id
@staticmethod
def get_current_annotation_id():
pascalVoc2Coco.bounding_box_id += 1
return pascalVoc2Coco.bounding_box_id
@staticmethod
def get_and_check(root, name, length):
"""
:param root: the element of ElementTree
:param name: the name of sub-element
:param length: the number of sub-element with name as parameter name
:return:
"""
var_lst = root.findall(name)
if len(var_lst) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if (length > 0) and (len(var_lst) != length):
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (
name, length, len(var_lst)))
if length == 1:
var_lst = var_lst[0]
return var_lst
def convert(self, img_idxes, json_file, categories=None):
"""
convert the voc format into coco format.
:param img_idxes: list of index for image in self.img_relative_paths
:param categories: the category list, that we want to train model with
:param json_file: the name of saved coco json file
:return:
"""
json_dict = {"images": [], "type": "instances", "annotations": [],
"categories": []}
if categories is None:
categories = list(set(self.image_labels))
categories=sorted(categories)
for idx in img_idxes:
xml_file = os.path.join(self.sample_root, self.xml_relative_paths[idx])
try:
tree = ET.parse(xml_file)
root = tree.getroot()
image_id = self.get_current_image_id()
size = self.get_and_check(root, 'size', 1)
width = int(self.get_and_check(size, 'width', 1).text)
height = int(self.get_and_check(size, 'height', 1).text)
image = {'file_name': self.img_relative_paths[idx], 'height': height, 'width': width,
'id': image_id}
for obj in root.findall('object'):
category = self.get_and_check(obj, 'name', 1).text
if category not in categories:
print('skip annotation {}'.format(category))
continue
if image not in json_dict['images']:
json_dict['images'].append(image)
category_id = categories.index(category) + 1
bndbox = self.get_and_check(obj, 'bndbox', 1)
xmin = int(self.get_and_check(bndbox, 'xmin', 1).text)
ymin = int(self.get_and_check(bndbox, 'ymin', 1).text)
xmax = int(self.get_and_check(bndbox, 'xmax', 1).text)
ymax = int(self.get_and_check(bndbox, 'ymax', 1).text)
if (xmax <= xmin) or (ymax <= ymin):
print('{} error'.format(xml_file))
continue
o_width = (xmax - xmin) + 1
o_height = (ymax - ymin) + 1
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id': image_id,
'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': self.get_current_annotation_id(), 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
except NotImplementedError:
print('xml {} file error!'.format(self.xml_relative_paths[idx]))
for cid, cate in enumerate(categories):
cat = {'supercategory': 'mm', 'id': cid + 1, 'name': cate}
json_dict['categories'].append(cat)
json_file = os.path.join(self.sample_root, json_file)
with open(json_file, 'w') as f:
json.dump(json_dict, f, indent=4)
def get_train_test_json(self, test_size=0.1, random_state=666, categories=None):
train_idxes, test_idxes = train_test_split(
list(range(len(self.img_relative_paths))), test_size=test_size, random_state=random_state,
stratify=self.image_labels)
self.convert(train_idxes, 'coco_train.json', categories)
self.convert(test_idxes, 'coco_test.json', categories)
# all samples train
self.convert(list(range(len(self.img_relative_paths))), 'coco.json', categories)
def parse_args():
parser = argparse.ArgumentParser(description='pocvoc2coco')
parser.add_argument('--img_path',help='img root path')
parser.add_argument('test_ration','help'='test size of img')
args = parser.parse_args()
return args
def read_txt(file):
with open(file,'r')as f:
content = f.read().splitlines()
return content
def read_json(file):
with open(file, 'r') as f:
content = json.load(f)
return content
def json2class(json_path, save_path):
data = read_json(json_path)
cate = data['categories']
with open(save_path, 'w+', encoding='utf_8') as f:
for i, c in enumerate(cate):
f.writelines(c['name']+'\n')
if __name__ == '__main__':
args = parse_args()
sample_root = args.img_path
test_ratio = args.test_ratio
data_convert = pascalVoc2Coco(sample_root)
data_convert.get_train_test_json(test_size = test_ratio,random_state=42)
json2class(os.path.join(sample_root, 'coco_train.json'), os.path.join(sample_root, 'classes.txt'))
文件夹摆放位置如下所示:
sample_root
--A
--1.jpg
--1.xml
--B
--2.jpg
--2.xml
利用如上的脚本可以生成对应的json文件和对应的class文件
3、模型训练
本文以faster_rcnn为例进行讲解,主要分为如下步骤:
- resnet50.pth预训练模型下载
from torch.hub import load_state_dict_from_url
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
state_dict = load_state_dict_from_url(model_urls ['resnet50'], model_dir=r'd\pre_trained')
print('finished load pre_trained models')
可以直接运行上述脚本,下载预训练模型到你的目录下,也可以直接复制上述网址直接下载
- faster-rcnn对应的config修改
(1)预训练模型地址更新

(2)RPN中的anchor_scales/anchor_ratios更新
mmdetectionv1.x和2.x存在命名上的区别,但是不影响结果,此处更新你的scales以及自己计算的anchor的长宽比
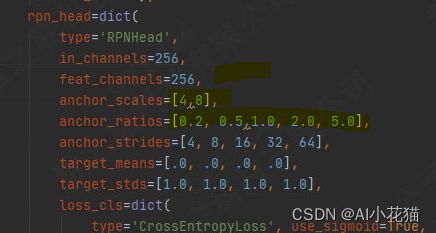
(3)类别数目更新
mmdetectionv1.x和2.x设定内别数量存在一定的区别,对于V1.X版本需要加上背景类,因此你的num_classes的数量需要多加1,V2.X版本不要如此操作,有几个类填写几。
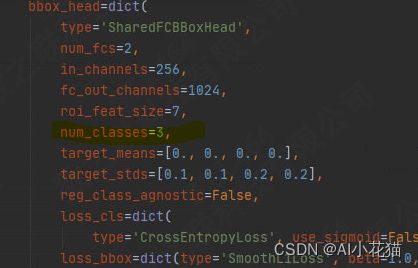
(4)训练集地址
将data_root 的地址更新为你的数据地址

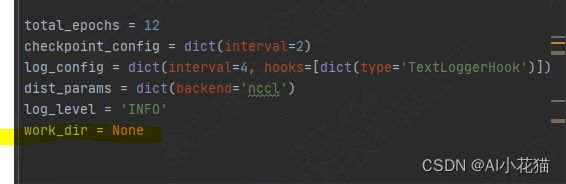
(5)存放结果的路径
修改work_dir的路径为你的路径,用以存放你的模型训练结果
- 模型训练
cd mmdetection
CUDA_VISIBLE_DEVICES='1,2' bash /tools/dist_train.py [your config] [GPU nums]
4、模型测试
测试之前可以更改你的config里面的测试数据的json文件,这样可以测试更多的数据,不仅限于数据集2-8分的数据集
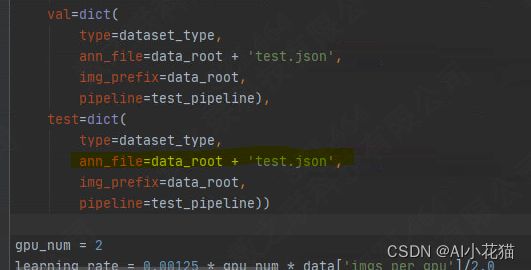
可按照如下脚本进行测试
cd mmdetection
python tools/test.py [your config path] [your checkpoint/model path] --out [result path] --eval bbox
测试结果如下图所示
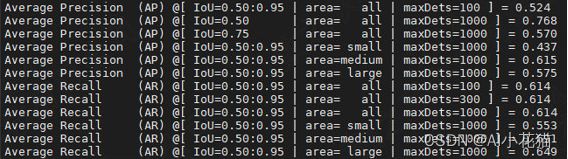
–END–
如有问题,敬请指正!