Defending Substitution-Based Profile Pollution Attacks on SequentialRecommenders
摘要
虽然序列推荐系统在捕获用户动态方面取得了显著的改进,但我们认为序列推荐系统对基于替代的轮廓污染攻击是脆弱的。为了证明我们的假设,我们提出了一种基于替代的对抗性攻击算法,该算法通过选择某些脆弱元素并用对抗性项目替换它们来修改输入序列。在非目标和目标攻击场景中,我们观察到使用所提出的轮廓污染算法的性能显著下降。基于这些观察结果,我们设计了一种有效的对抗性防御方法,称为狄利克雷邻域抽样(Dirichlet neighborhood sampling)。具体地说,我们从一个由多跳邻居构造的凸包中采样项嵌入,以替换输入序列中的原始项。在采样过程中,使用狄利克雷分布来近似邻域内的概率分布,使推荐者学习对抗局部扰动。此外,我们还设计了一种针对顺序推荐系统的对抗性训练方法。特别地,我们用单热编码表示选定的项目,并对编码执行梯度上升,以在训练中搜索项目嵌入的最坏情况线性组合。因此,嵌入函数学习鲁棒的项目表示,训练的推荐者对测试时间对抗的例子具有抵抗力。大量的实验表明了我们的攻击和防御方法的有效性,它们在模型架构和数据集上始终显著优于基线。
1介绍
顺序推荐将用户交互历史作为输入,并生成用户[15,18,40]可能感兴趣的潜在项目。与传统的推荐者不同,顺序推荐可以通过将项目转换模式视为时间序列来捕获用户的演化动态。因此,各种最近的顺序推荐器(例如,Locker[13])始终优于以前的最先进的模型。
然而,已知在对抗性扰动[9,36,41]下,推荐系统的可靠性会恶化。虽然基于梯度的方法不能直接应用于推荐者来搜索项目空间中的扰动,但某些启发式方法可以用于执行对抗性攻击[25,34]。在此方法的基础上,采用轮廓污染1进行特定用户的对抗性攻击[34,36]。为了执行此类攻击,恶意软件可以用来访问用户配置文件和交互(例如,跨站点请求伪造(CSRF)或后门攻击)[16,26,37]。
我们认为,顺序推荐针对基于替代的配置文件污染攻击具有独特的漏洞。基于替代的对抗性攻击在以前或正在进行的交互中操纵易受攻击的项目,以破坏推荐(即非目标攻击)或操纵推荐的项目(即目标攻击)[16,20,26,37]。以往关于轮廓污染研究攻击算法的研究有以下局限性:(1)现有的为传统推荐者设计的方法不能应用,或者不是为顺序推荐者[32,34,43]量身定制;(2)以前的方法没有探索基于替代的攻击,而是专注于注入对抗项[36,43];和(3)对抗防御方法没有讨论[24,32,34,36,43]。
在自然语言处理(NLP)[5]中也可以找到类似的顺序设置。NLP对抗性攻击主要研究单词级替换,其中一小部分输入词被替换[1,17,27]。为了在NLP中找到敌对的例子,一种可能的方法是在同义词中迭代搜索[1]。另一种常见的方法是选择脆弱的单词,用对抗的词汇[17,27]代替。尽管NLP和顺序推荐相似,但很难使用类似的技术为推荐者建立对立的例子。原因有两方面:(1)在推荐系统中,项目空间太大,在没有同义词信息的情况下无法枚举;(2)现有的NLP攻击算法没有利用基于梯度的方法来提高攻击性能。
本文设计了一种基于替代的轮廓污染攻击的梯度引导算法。我们的攻击算法通过选择有限数量的脆弱元素来修改输入序列,并用精心选择的对抗项替换输入序列。根据设计,基于替换的攻击可以按顺序执行替换攻击,也可以将恶意项目注入到用户交互中(通过插入和攻击项目,如在[36]中)。为了防止被识别为恶意输入,我们施加了两个约束:(1)我们限制每个序列中的最大替换数;(2)对于替代项,我们另外要求与原始项目相似。我们的实验结果表明,在非目标场景和目标场景下,性能都显著下降,这表明所提出的基于替代的攻击对顺序推荐者构成了严重威胁。
基于防御方法的研究差距,我们另外提出了两种针对顺序推荐的防御方法。为了有效地训练鲁棒推荐器,提出了狄利克雷邻域抽样的方法。具体地说,我们利用嵌入矩阵构造多跳邻域,并通过狄利克雷分布构造样本增广项嵌入来进行随机替换。此外,我们还为顺序推荐设计了一种对抗性训练方法。特别地,我们用一个one-hot编码来表示项目,并更新编码以搜索最坏情况的增强。通过对虚拟输入进行训练,将推荐器的鲁棒性扩展到更大的邻域。我们的评估结果表明,所提出的防御方法显著降低了轮廓污染攻击下的多个真实数据集的性能变化50%以上。
2个相关工作
2.1推荐系统中的对抗性攻击
对推荐系统的对抗性攻击可以分为两类:(1)数据中毒和(2)配置文件污染。数据中毒攻击伪造的用户配置文件,并将这些配置文件注入训练数据,在部署[4,6,14,29,32,42]时导致有偏差的推荐结果。与中毒攻击不同,配置文件污染攻击会改变现有的用户配置文件(即用户交互),以操作推荐的项[22,33,34,36,43]。配置文件污染可以通过网络注入、CSRF攻击或恶意软件[16,26,37,43]等安全漏洞来执行。
在这项工作中,我们关注配置文件污染,并执行特定于用户的攻击来操纵推荐结果[36]。CSRF攻击在黑箱设置[33]下操纵YouTube等网站的用户历史。恶意请求被利用,使网络广告偏向于付费价格更高的广告商[22]。有了对推荐者的知识,找到对抗性的例子可以表述为一个优化问题[34]。Web注射用于未受保护的网站来推广目标项目[43]。Yue等人[36]提出提取黑盒推荐者,并使用提取的模型计算对抗性示例。我们提出的轮廓污染算法与之前的方法有两个方面的不同之处:(1)我们将攻击范围扩展到全序列的替换;对对抗性例子施加(2)约束,以加强干净序列和对抗性序列之间的相似性。
2.2语言中的对抗性攻击
由于项目替代设置了轮廓污染,在各种NLP分类任务中也可以发现类似的场景,其中对抗性攻击是在词级替代上进行研究的。NLP替代攻击将一小部分的输入词替换为对抗性词,以实现攻击目标[1,17]。NLP对抗性的例子可以使用遗传算法生成,其中同义词被迭代和评估[1]。输入词的脆弱性可以通过重要性得分来评估,然后用最脆弱的词来构建对抗性的例子,直到模型被愚弄,[7,17,19,27]。尽管语言和顺序推荐相似,但由于推荐数据中缺乏同义词(即邻居项)的(1),很难将现有的NLP方法转移给推荐者;(2)是现有NLP方法对大规模或实时攻击的效率低下。与以往的方法不同,所提出的轮廓污染算法利用推荐模型中的梯度信息,构建多跳邻域,有效地计算对抗性替代品。
2.3对抗性防御方法
提出了各种防御方法来增强神经网络[9,10]的鲁棒性。对抗性训练和平滑方法在训练中加入了增强的例子,以增强对扰动[9,38,39]的鲁棒性。区间界传播正则化可处理的上界和下界,以保证鲁棒性[10]。对抗性训练对单词嵌入引入范数有界局部扰动来学习鲁棒特征[28,45]。最近,狄利克雷邻域集成利用同义词嵌入来构建鲁棒的词表示[44]。对于推荐系统,对抗性训练引入扰动来提高模型性能和泛化[3,12,35]。多媒体推荐器通过对抗性训练[31]来学习防御产品图像上的扰动。据我们所知,以往没有任何方法试图增强推荐系统对轮廓污染攻击的鲁棒性。因此,我们提出了两种针对顺序推荐者的新的防御方法,并表明了使用所提出的防御方法可以显著提高模型的鲁棒性。
3初步
3.1设置
3.1.1数据。我们的框架基于顺序输入,它将用户交互历史(按时间戳排序)作为输入。表示长度为的输入[1,2,...,],每个元素都表示在项范围I中(即∈I)。输入后的下一个项交互+1∈I被用作ground truth :(即=+1)。
3.1.2模型。我们用函数来表示顺序推荐。给定输入序列,预测项目范围i上的概率分布。由一个嵌入函数和一个序列模型组成,使用()=(())。对于数据对(,),理想情况下,预测的概率最高(即=arg max())。
3.1.3优化。序列推荐的学习是为了使输入时输出项的概率最大化。换句话说,我们最小化损失L的期望,w.r.t.覆盖于数据分布的区域X:

其中,L表示训练损失函数(即排序损失或交叉熵损失)。
3.2对抗性攻击和防御
3.2.1的假设。我们首先在攻击场景中引入我们的框架的假设,我们用以下假设将问题设置形式化,以定义我们的研究范围:
数据访问:攻击者可以访问评估数据X和项目范围I来执行攻击。
•白盒攻击:我们假设攻击者可以访问的权重来计算对抗性的例子。
•有限替换:在每个输入序列中,我们施加最大数量的替换,以在序列水平上加强原始和对抗性例子之间的相似性。
•对项目相似度的约束:为了避免被识别为离群值,我们在嵌入空间中的原始项目与对抗性项目之间施加了一个具有最小余弦相似度的相似度约束。
上述假设是为了对所提出的轮廓污染攻击算法进行直接和不受干扰的评估(即,不考虑模型提取等外部影响)。所构建的对抗性攻击也更具挑战性,因此,评估了所提出的防御方法在恶劣条件下的有效性。对于辩方的建议,我们假设了对数据和推荐模型的完全访问权。
3.2.2威胁模型。如前所述,我们采用轮廓污染攻击来构建对抗性的例子。我们调查非针对性攻击(即降级)和有针对性攻击(即升级)。我们在下面阐述这两种攻击。
•非目标攻击:构造非目标对抗性示例来最小化概率w.r.t.地面真相。根据我们所要求的假设:(1)替换的数量受到汉明距离的限制(即最多为的替换);(2)原始项和对抗项之间需要最小余弦相似度。我们用‘表示对抗性的例子,并将攻击表示为一个优化问题w.r.t.:

目标攻击:目标对抗性例子的目标是最大化概率w.r.t.目标项目。具体来说,我们最小化损失w.r.t.输入。对有针对性的攻击也设有类似的限制:
![]()
3.2.3对抗性训练。在轮廓污染攻击框架下,可以通过最小化扰动输入数据的预期损失(即对抗性训练)来建立一个鲁棒推荐器。也就是说,我们在优化中的模型参数和基于更新敌对数据之间交替寻找均衡。对抗性的例子是在训练过程中动态生成的,并用于最小化训练损失L,使模型被迫调整参数以抵抗对抗性的扰动。在形式上,我们将对抗性训练定义为一个极大极小优化问题w.r.t.型号:

4方法
4.1剖面污染攻击
该算法既可以攻击历史项,也可以向推荐人插入“欺骗”对抗项。理想情况下,被污染的序列会导致性能下降(即非目标攻击)或增加目标项目的暴露(即目标攻击)。我们在图1中说明了所提出的轮廓污染攻击算法,非目标攻击和目标攻击的详细步骤如算法1所示。

步骤1:前进和计算梯度w.r.t.“输入”。
给定输入,我们通过在中替换选定的项来构建污染序列‘。首先,我们将污染序列‘不变初始化为,然后使用嵌入函数计算嵌入序列˜’。然后,我们计算˜‘的梯度,在嵌入空间中构造对抗性扰动。在目标攻击的情况下,通过推荐函数输入˜‘来计算交叉熵损失Lw.r.t.目标项目。然后,进行反向传播,检索˜‘的梯度∇˜’(即∇˜‘=∇˜’Lce((˜‘),))。对于非目标攻击,我们计算交叉熵损失w.r.t.输出分布中的预测项。在非目标攻击中,否定梯度,以执行梯度上升。
步骤2:
选择要攻击的脆弱项目。在输入顺序中,项目具有不同的脆弱性。我们选择易受攻击的项目,并对这些项目进行替换,以达到最佳的攻击性能。特别是,我们使用前一步中的∇˜‘来计算重要性分数。与现有的工作不同,我们将∇˜‘中最后一个维度的2范数作为我们的重要性分数(即∥∇˜’∥),这样就可以通过梯度的陡度有效地估计输入项目的脆弱性。我们通过从重要性排名中选择第一个项目来选择最多的项目。基于快速梯度符号法[9],扰动嵌入˜‘可以计算如下:

步骤3:对项目空间的项目攻击。在最后一步中,我们将扰动嵌入˜‘投影回项目空间。与[36]类似,我们计算˜‘和I中的候选项目之间的余弦相似度,相似度值较高的项目被青睐作为对抗性的替代品。它背后的思想是利用余弦相似性在构造的敌对嵌入的方向上找到最接近的项。我们将表示为余弦相似度分数。在这里,我们施加另一个约束来强制项目相似性,其中对抗性项目需要与原始项目具有最小的余弦相似度(高于)。我们使用指标函数(即1)来选择满足相似性约束的项目。表示相似度约束结果,与按元素顺序相乘(即⊙)。最终的对手可以从中选择。为了提高对抗性攻击和项目投影的效率,对前面的所有步骤都采用矩阵乘法进行批量计算。

4.2狄利克雷邻域抽样
为了有效地训练一个鲁棒序列推荐器,我们首先提出了狄利克雷邻域抽样,这是一种增强模型鲁棒性的随机训练方法。对于邻域抽样,需要一个连通图来识别项目的邻域。在自然语言处理中,同义词信息可以用于计算多跳邻居。然而,在推荐系统中不存在自然的邻居或同义词。因此,我们建议通过计算所有项目对之间的余弦相似度来为项目范围I中的每个项目构造一个邻域。如果项目和项目的余弦相似度大于或等于(即CosSim(,)≥),则我们将项目对(,)定义为邻居。在不存在邻居的情况下,使用相似度值最高的项目作为1跳邻居。在现有的1跳邻居的基础上,将图扩展到包含2跳邻居,并构造一个邻域字典,在训练中对增广项嵌入进行采样。邻域字典在每个时代都会更新(我们在实验中使用=10)。
对于每个项目,我们可以在由项目的多跳邻居(即顶点)所跨越的嵌入空间中计算一个凸包(平面上 N 个点的凸包是包围这 N 个点的最小多边形)。利用凸包作为增强项目嵌入的采样空间。这允许我们从由凸包中的顶点定义的狄利克雷分布中进行抽样,以构造随机嵌入。通过在邻域内进行多次采样,推荐者对局部扰动的敏感性较低,并学会了拒绝对抗性项目,如图2a所示。形式上,对于项目及其集合的多跳邻居C(C={,1,,2,……,,|C|}),我们用从狄利克雷分布中采样的来表示增强项:
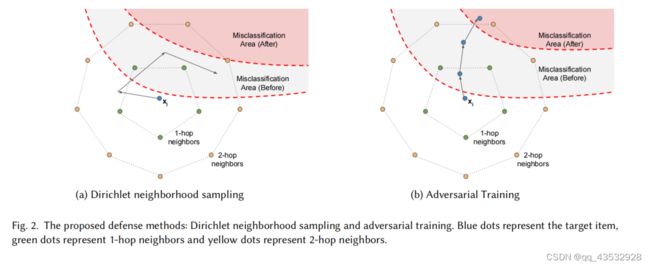
4.3混合表示的对抗性训练
虽然狄利克雷邻域抽样对训练顺序推荐很有效,但它不利用计算最坏情况增强的训练实例。为了进一步提高模型的鲁棒性,我们设计了一种附加的防御方法,称为具有混合表示的对抗性训练。与现有的对抗性训练方法[31,45]和狄利克雷邻域抽样不同,该方法在I中搜索项目的最坏情况线性组合,而不是单独从局部邻域抽样。搜索项目组合背后的想法是引入原始项目和潜在的对抗性项目的混合表示。然后,我们可以通过使用梯度上升更新来计算最坏情况下的线性组合,使原始和对抗性项目嵌入共同优化鲁棒项目表示。
对于输入中的项目,我们首先用一个热向量=Onehot()∈R|I|初始化。与狄利克雷邻域抽样类似,()被计算为嵌入矩阵(即()=I|I|=1,())的加权和。接下来,我们执行梯度上升并计算梯度w.r.t. .具体来说,首先使用嵌入函数计算输入的嵌入序列˜。与第4.1节类似,然后我们将˜使用序列模型转发˜,并基于优化损失计算梯度来更新:

其中,是步长。在每次更新中,我们通过将梯度除以它们的2范数来规范化梯度。然后,将步长乘以梯度,然后进行梯度上升。因此,转向顺序推荐的误分类区域,见图2b。由于是I中所有项目的线性组合,我们需要I|I|,=1和,≥0,=1,2,……并确保更新后的在嵌入空间内遵循相同的要求。因此,我们在每次更新后剪辑负元素并重新调整:

我们在图2b中用混合表示来说明所提出的对抗性训练。我们用蓝点表示项目,蓝点的路径表示对抗性训练的更新迭代,其中对抗性的例子向错误分类区域移动,从而迫使推荐者抵抗最坏情况下的扰动。与狄利克雷抽样不同的是,增强方向是从局部凸包内的分布中抽样的,对抗性训练发现使用项目的线性组合来传播梯度到项目表示。这种最坏情况下的增强将模型的鲁棒性扩展到局部邻域之外的更大区域,从而有效地减少了错误分类的区域。与狄利克雷邻域抽样相比,使用混合表示的对抗性训练需要增加的计算成本,因为对抗性的例子在每次迭代中都会更新多次。为了降低培训成本,我们选择了的比例在实验中,我们使用干净输入和扰动示例对推荐项进行优化,以增强模型的鲁棒性。
5实验
5.1设置
5.1.1数据集。在我们的实验中,我们采用了5个数据集来验证所提出的攻击和防御方法(详见表1)。我们使用亚马逊Beauty[23],ML(1M和20M)[11],LastFM[2]和Steam[21]。我们采用了所有数据集的5核版本,并按照[30,36]的方法对数据进行了预处理。

5.1.2模型。我们选择了四种不同的推荐体系结构来评估所提出的方法,见表2。特别是,我们在实验中采用了NARM[18]、SASRec[15]、BERT4Rec[30]和Locker[13]:
神经注意推荐机(NARM)是一种基于RNN的顺序推荐器,由全局编码器和局部编码器组成。NARM利用一个注意力模块来计算项目表示,并使用相似度层[18]输出预测。
•自注意顺序推荐(SASRec)利用变压器块来自动回归地转发项目。变压器块计算具有单向自注意的注意表示。SASRec由一个嵌入函数、变压器块和一个输出层[15]组成。
•来自顺序推荐变压器的双向编码器表示(BERT4Rec)具有与SASRec类似的架构。BERT4Rec利用双向自注意,采用掩蔽训练(即掩蔽语言建模)对[30]模型进行优化。
•局部约束自注意推荐器(Locker)类似于BERT4Rec,但提出了额外的局部约束来提高自我注意。在我们的实现中,我们使用卷积层来建模局部动力学。储物柜也通过蒙面训练[13]进行了优化。
5.1.3评估。我们跟随[15,30,36]进行评估。我们采用留一法,在每个序列中的最后两项进行验证和测试。我们采用归一化贴现累积增益NDCG@10和召回率@10作为评估指标。在攻击实验中,在不同的流行群体中选择15个项目作为目标攻击,对被污染的轮廓进行评估并计算平均结果。
5.1.4实现。我们按照原论文实现顺序推荐[13,15,18,30]。除非明确提到,超参数都来自原始作品。所有模型都使用Adam优化器进行不预热的训练,学习率为0.001,权重衰减为0.01,批处理大小为64。与[15,30,36]类似,我们将其他数据集的ML-1M的最大序列长度分别设置为200和50。对于轮廓污染,我们使用=2作为ML-1M的最大替代品,并使用=1替代其他数据集。对攻击和防御方法都采用了=0.5的最小余弦相似度。在我们的防御实验中,我们将替换概率设置为0.5,并采用狄利克雷采样的2跳邻域。为了更新对抗性训练中的扰动,在我们的实现3中使用了来自[0.01,0.1,1.0]的更新步长和三个对抗性更新迭代。
5.2 RQ1:我们是否可以使用基于替代性的配置文件污染来攻击推荐系统?
我们首先评估了所提出的轮廓污染算法对所有模型架构和数据集的攻击性能,结果如表3所示。由于我们限制了替换两个以上的项,所以我们采用SimAlter为基线方法,利用邻居项作为对抗项来进行攻击[36]。该表包括几个部分:(1)每一行表示模型名称和设置(即U表示非目标攻击,T表示目标攻击);(2)每一列表示一个数据集的结果;(3)针对目标攻击,我们在不同流行组中选择15个项目并报告平均结果;(4)结果较低表示更好的非目标攻击性能,较高的结果表示更好的目标攻击性能;(5)结果在NDCG@10和召回@10(即N@10/R@10)中。最佳结果用粗体标记。

从结果中我们观察到:(1)通过比较清洁性能(即之前)和被攻击的度量数(即SimAlter和我们的),推荐模型显示了对轮廓污染攻击的脆弱性。例如,推荐者在对ML-1M的非目标攻击中,性能有超过50%的下降。(2)该方法在非目标攻击和目标攻击中都表现最好,成功地使推荐模型偏向于目标,并且在所有情况下都优于基线方法,但Steam上的Locker除外。(3)我们在模型架构和训练数据集之间观察到不同的漏洞。例如,我们观察到基于RNN的模型(即NARM)更容易受到目标攻击,在NDCG@10上平均增加超过175%。相反,储物柜的有针对性攻击只增加了82.1%。此外,我们观察到,密集的数据集通常对轮廓污染攻击更稳健。例如,我们只观察到对LastFM数据集的非目标攻击的性能下降了9.5%,而相同的设置导致对Beauty的性能下降了37.5%。研究结果表明,该算法能够有效地进行轮廓污染攻击。
5.3 RQ2:建议的防御方法在轮廓污染攻击下如何执行?
我们通过评估用防御方法训练的推荐者的轮廓污染攻击来研究防御方法的有效性。特别地,我们采用相同的训练条件,并应用所提出的方法(即狄利克雷邻域抽样和对抗性训练)。然后,我们对干净测试数据和污染测试数据评估推荐性能。由于每种防御方法都产生一个新的模型,我们只计算模型上清洁和污染评估数据之间的性能变化(Δ)。理想情况下,鲁棒推荐器的性能变化很小,因此Δ的绝对值越低表明防御性能更好。换句话说,越高的值表明非目标攻击的结果越好,因为模型在攻击后会下降(即Δ是负的)。较低的值表示目标攻击的结果更好,如度量值w.r.t.攻击后目标项目增加(即Δ为正),见表4。与表3类似,我们根据模型、数据集和攻击类型分离了不同的设置。我们采用NDCG@Δ@10和Recall@10作为指标,并以粗体标记最佳结果。

防御结果表明:(1)虽然推荐者对轮廓污染攻击很脆弱,但我们发现这两种防御方法都对被污染的测试数据很有帮助。例如,所提出的对抗性训练将ML-1M上NDCG@10的非目标攻击恶化减少了34.2%。(2)研究结果表明,所提出的对抗性训练表现最好,在40种情况中有30种表现最好。总的来说,对抗性训练使非目标攻击中NDCG@10的变化减少了34.4%,而所提出的狄利克雷邻域抽样方法为28.5%。结果表明,对抗性训练显著提高了模型的鲁棒性,并在大多数情况下可以优于随机化方法(即狄利克雷抽样)。这可能归因于生成的对抗性例子,这迫使模型减少对脆弱特征的依赖。(3)防御方法的性能因推荐器和数据集的不同而不同。例如,所提出的对抗性训练在NARM和SASRec上表现出更好的性能,在5个数据集中的4个上始终优于狄利克雷邻域采样。一个潜在的原因可能是自回归训练方法,它通过学习快捷方式和局部特征[8]增加了模型的脆弱性。(4)基于防御结果,LastFM在所有数据集上对两种攻击都表现出最高的鲁棒性,而Locker在所有推荐架构中表现最好。这表明,增加数据密度和捕获用户动态有助于健壮性,可能是通过提供更多信息的项目表示和转换模式。此外,通过自编码进行学习(即掩蔽训练)可能会提高推荐器对对抗性攻击的鲁棒性。

此外,我们还研究了性能变化w.r.t.项目的流行程度。具体来说,我们研究了对顺序推荐者的目标攻击,并选择了不同流行程度的目标项目。目标项目根据其在数据集中的受欢迎程度(即总出现的次数)被分为三个子组。流行的项目表示在项目范围内的13个最受欢迎的项目。中间和底部的13项和最后13项。我们在图3中展示了所有数据集的项目分布,我们展示了三个在所有推荐模型中平均的流行子组的污染结果。类似地,在表5中使用Δ为NDCG@10和Recall@10报告性能变化。我们观察到:(1)流行项目的脆弱性最高,攻击前ΔN@10为0.182,在所有情况下性能变化最大;(2)中间和底部的项目通常“更难”攻击。例如,中间的项目在攻击前的ΔN@10要低得多,为0.051。(3)流行的物品也“更难”防御,防御后的ΔN@10减少了27.0%,而中间和底部的物品分别为58.2%和73.8%。结果表明,流行的物品对侧面污染攻击表现出最高的脆弱性,造成这种脆弱性的一个潜在原因是邻居的数量较多,这增加了可能的对抗性替代品的数量。

5.4 RQ3:推荐人的性能和健壮性如何随着不同的模型体系结构而变化?我们研究了不同推荐模型的脆弱性和所提出的防御方法的性能。特别地,我们研究了对所有数据集的攻击,并比较了不同推荐架构在轮廓污染攻击下的原始性能和性能变化。我们在表6中给出了每个推荐架构的平均结果,以进行直接比较。可视化的结果如图4a和图4b所示。每个子图代表一个推荐模型,其中使用不同防御方法的所有数据集上的结果用条形图进行比较和可视化。由于NDCG@10和Recall@10提供了类似的趋势,我们将召回结果可视化在图表中。B、M-1、M-20、L、S代表Beauty、ML-1M、ML-20M、LastFM和Steam数据集。

以下是我们的观察结果:(1)我们观察到,对抗性训练对推荐绩效的影响有限。例如,我们在基于变压器的模型上的结果显示了轻微的性能变化,可能是由于改进的项表示。(2)通过比较表6中轮廓污染攻击前后的性能变化,我们观察到NARM更脆弱,并且在应用防御方法前后都表现出更高的性能变化。(3)Locker平均表现出最高的鲁棒性。在不采用防御方法的情况下,我们观察到非靶向攻击中锁定器变异的27.4%NDCG@10,而BERT4Rec、SASRec和NARM分别为32.7%、32.4%和33.6%。(4)虽然SASRec和BERT4Rec有类似的变压器到Locker、SASRec和BERT4Rec的方块更容易出现,即使经过反向训练,也会遭受更高的性能恶化。例如,针对流行物品的攻击使对SASRec的NDCG@10变异增加了31.3%,对BERT4Rec增加了27.2%,而对Locker的攻击只有24.8%。总的来说,基于变压器的顺序推荐器(即SASRec、BERT4Rec和Locker)比基于RNN的模型(即NARM)显示出了更好的鲁棒性。当我们对顺序推荐者应用对抗性训练时,可以观察到类似的趋势。这种鲁棒性的原因可以追溯到在变压器模型中引入的全局关注。此外,BERT4Rec和Locker利用掩蔽训练来提高对全局上下文的捕获。相比之下,NARM依赖于局部时间模式,并且可能对基于替代的扰动更加敏感。