神经网络学习(1):cells +layers
神经网络学习(1):cells +layers
NEURAL NETWORK ZOO PREQUEL: CELLS AND LAYERS

一、 神经元(cells)
神经网络图表展示了不同类型的 神经元(cell) 和不同的 层(layer) 连接样式,但它并没有深入研究每个神经元的工作方式。最初给不同类型的神经元设置不同的颜色来更清晰地区分网络,但后来发现这些神经元的工作方式或多或少是相同的,所以给出以下描述。
1、基础神经网络神经元(basic neural network cell),可以在常规的前馈体系结构中找到,非常简单。神经元通过权值与其他神经元连接,即可以连接到前一层的所有神经元。每个连接都有自己的权值,通常一开始只是一个随机数。权重可以是负的、正的、非常小、非常大或零。(人工神经网络的权重初始化,会直接影响到之后的训练过程,以及整个模型的性能)
它连接到的每个神经元的值乘以其各自的连接权值,将所有结果都加在一起,再加上一个偏置得到总和。这个总和通过一个激活函数传递,得到的输出就是神经元的值。
偏置可以防止神经元陷入输出为零的状态,还可以加快某些操作的速度,减少解决问题所需的神经元数量。偏置也是一个数字,有时是常数(通常是-1或1),有时是变量。

2.1、卷积神经元(Convolutional cells) ,很像前馈细胞,只是它们通常只与前一层的几个神经元相连。通常用来保存空间信息,因为它们不是连接到几个随机的神经元,而是连接所有 特定范围内/一定距离内 的神经元,适用于包含大量局部信息的数据,如图像和语音(但主要是图像)。
2.2、解/逆卷积神经元,倾向于通过与下一层的局部连接来解码空间信息。卷积和解卷积神经元都有许多副本,这些副本都是独立训练的,每个副本都有自己的权重,但连接方式完全相同。这些副本可以被认为是位于具有相同结构的独立网络中。它们本质上与普通神经元相同,但使用方式不同。
3.1、池化神经元(Pooling cells),池化和插值神经元常常与卷积神经元相结合。它们并不是真正意义上的神经元,只能进行一些原始操作。池化神经元接收连接的其他神经元传入的值,并决定通过哪个值。在图像中,可以被认为是缩小了图片,不能再看到所有的像素。它必须学会保留和丢弃哪些像素。
3.2、插值神经元(interpolating cells),执行相反的操作,插值神经元接收一些信息并将其映射到更多的信息。额外的信息是编造出来的,就像放大一个小分辨率的图片。内插神经元并不是池化神经元的唯一反向操作,但由于它们快速且易于实现,因此相对比较常见。它们之间的关系,很像卷积神经元和解卷积神经元。
4、均值和标准差神经元(Mean and standard deviation cells),几乎只会作为概率神经元成对出现,用于表示概率分布。均值是平均值,标准差表示与平均值(两个方向)的偏离程度。
例如,用于图像的概率神经元可以包含一些信息,如某个特定像素中有多少红色。若均值是0.5,标准差是0.2。当从这些概率神经元中采样时,将它们的值输入高斯随机数生成器中,结果可能是0.4到0.6之间的任何值,而距离0.5越远的值越不可能(但仍然是可能的)。它们通常与前一层或下一层完全连接,并且没有偏置。
5、循环神经元(Recurrent cells),不仅在层之间有连接,在时间轴上也有连接。每个神经元在内部存储其先前值。它们就像基本的神经元一样被更新,但是带有额外的权重:连接到神经元的先前值,并且大多数时候,也连接到同一层中的所有神经元。
当前值和存储的先前值之间的权重的作用,就像易失存储器(RAM),继承2个属性:
a. 维持一个特定的“状态”
b. 如果不对其持续进行更新(输入),这个状态就会消失
因为先前值是一个通过激活函数的激活值,并且每次更新会将这个激活值和其他权重一起传递给激活函数,信息会不断丢失。事实上信息的保留率很低,仅需4~5次迭代之后,几乎所有的信息就都丢失了。

6、长、短期记忆神经元(Long short term memory cells),用来解决循环神经元(RNN)中信息快速丢失的问题。LSTM神经元是逻辑电路,复制了计算机内存单元(记忆神经元)的设计。与存储两种状态的RNN神经元相比,LSTM神经元存储四种状态:输出的当前值和先前值,记忆神经元的当前值和先前值。
它们有三个“门”:输入、输出、遗忘,而且它们还有常规输入。每个门都有自己的权重,这意味着连接到这类神经元需要设置4个权值(而不是1个)。门的功能很像流动门,而不是栅栏门:它们可以让所有信息通过,只通过一点点,什么也不允许通过,或者通过某个区间的信息。
它的工作原理是将输入的信息乘以一个0~1之间的值,该值存储在这个门值中。即输入门决定向神经元值添加多少输入。输出门决定了有多少输出值传递给后面的神经网络。遗忘门不连接到输出神经元的先前值,而是连接到前一个记忆神经元的值,它决定前一个记忆神经元的状态需要保留多少。因为它没有连接到输出,并且循环中没有放置激活函数,信息的丢失要少得多。
7、门控循环神经元(Gated recurrent units (cells)),是LSTM神经元的一种变异。它们也使用门来对抗信息丢失,但只有两个门:更新和重置。这使得它们的表达能力略差,但速度也略快,因为他们在任何地方使用的连接都更少。
LSTM神经元和GRU神经元在本质上有两个不同:
a. GRU神经元没有由输出门保护的隐神经元,
b. 它们将输入和遗忘门合并为一个更新门。其思想是,如果想获得大量的新信息,就可以遗忘一些旧信息(反之亦然)。

二、 层(layers)
构建神经网络的最基本方法是将所有的神经元都与其他神经元连接起来,可以在Hopfield网络和玻尔兹曼机(Boltzmann machines) 中看到。当然,这意味着连接的数量,随着神经元数量的增加呈指数级增长,但对应的函数表达力也会越来越强,被称为全(或完全)连接(completely (or fully) connected)。
过了一段时间,人们发现将网络分成不同的层是一个有用的特性,其中层的定义是一组神经元,它们彼此之间没有连接,只与其他组的神经元相连。这个概念应用于受限玻尔兹曼机(Restricted Boltzmann Machines)。层的概念现在被推广到任意数量的层,并且几乎应用于所有当前的架构中。其中一个比较令人困惑的概念是全连接(fully connected or completely connected),也就是某一层的每个神经元跟另一层的所有神经元都有连接,但实际上全连接神经网络非常少见。
1、卷积连接层(Convolutionally connected layers)
卷积连接层比全连接层更受限制:只将每个神经元连接到其他层中相邻的部分神经元。如果将图像或语音直接一对一地传输到网络中(例如,每个像素对应一个神经元),那么它们包含的信息量非常大。卷积连接的概念来自于对空间信息的保留。事实证明,这是一个很好的猜测,因为它在许多基于图像和语音的神经网络中得到了应用。并且,卷积连接比全连接的层代价更低。
本质上,卷积连接方式是一种“重要性”过滤的方法,决定哪些分组紧密的信息包是重要的,对于降维非常有用。神经元在何种空间距离下仍然可以连接取决于实际情况,但是很少使用超过4或5个神经元。“空间”通常指二维空间,这就是为什么大多数表述中显示出神经元三维薄片的连接,连接范围适用于所有维度。
2、随机连接神经元(randomly connected neurons)
随机连接神经元的连接方式有两个主要的变体:
a. 允许部分神经元全连接,
b. 层之间连接部分神经元。
随机连接有助于线性降低人工神经网络的性能,大型网络中在全连接层遇到性能问题时,采用随机连接方式有非常有用。在某些情况下,神经元多、连接稀疏的层效果更好,特别是在需要存储大量信息但不需要交换那么多信息的情况下(有点类似于卷积连接层的效果,但它是随机的)。在ELMs、ESNs和LSMs中,也使用了非常稀疏的连接网络(1%或2%)。特别是在脉冲网络(spiking networks)中很有意义,因为神经元的连接越多,每个权值传递的能量就越少,意味着扩散和重复的模式就越少。
3、时间滞后连接(Time delayed connections)
时间滞后连接是神经元之间的连接(通常来自同一层,甚至是它们自身的连接),它们不从上一层获取信息,而是从当前层先前的状态获取信息(大部分是以前的迭代)。能够存储暂时的相关信息(时间上或序列上)。为了清除网络的“状态”,这种类型的连接需要经常的人工重置。与常规连接的关键区别在于,即使没有对网络进行训练,这些连接也在不断变化。
下图展示了上述的一些小型示例神经网络及其连接:
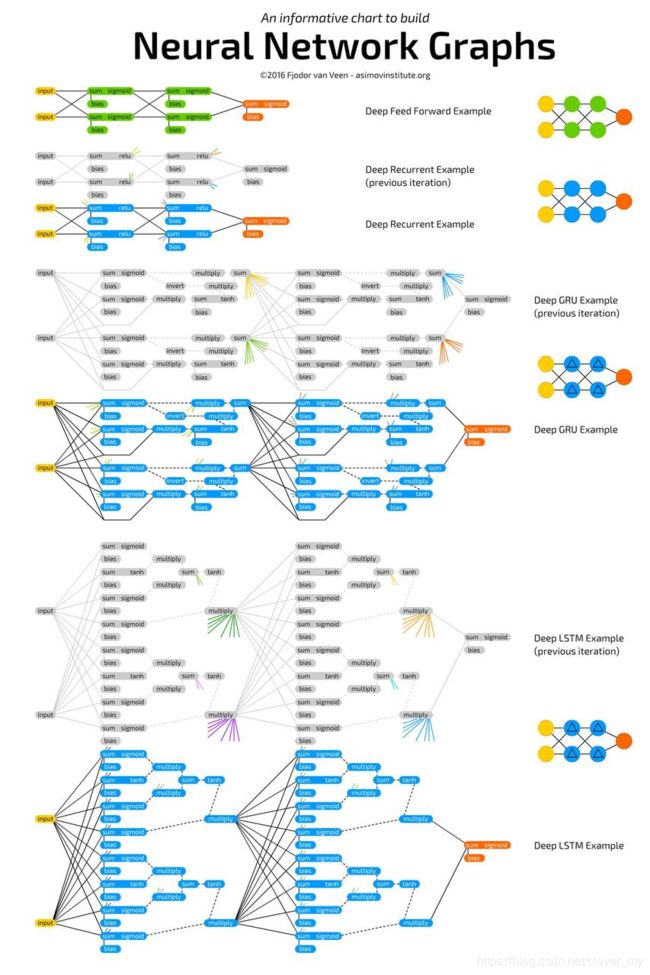
参考:各种网络汇总CNN、RNN、GAN…