3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation
Abstract
本文介绍了一种从稀疏标注的体积图像中学习的体积分割网络。我们概述了该方法的两个有吸引力的用例:(1)在半自动设置中,用户注释要分割的体积中的一些切片。网络从这些稀疏注释中学习并提供密集的3D分割。(2)在全自动设置中,我们假设存在一个有代表性的、稀疏注释的训练集。在这个数据集上训练,网络密集分割新的体积图像。所提出的网络扩展了Ronneberger等人先前的u-net架构。通过将所有2D操作替换为对应的3D操作。该实现在训练期间执行动态弹性变形以实现有效的数据增强。它是从头开始端到端训练的,即不需要预先训练的网络。我们在复杂、高度可变的3D结构(非洲爪蟾肾脏)上测试了所提出方法的性能,并在两个用例中都取得了良好的效果。
关键词: 卷积神经网络,3D,生物医学体积图像分割,非洲爪蟾肾脏,半自动,全自动,稀疏标注
1 Introduction
体积数据在生物医学数据分析中非常丰富。使用分段标签对此类数据进行注释会造成困难,因为计算机屏幕上只能显示2D切片。因此,以逐片的方式注释大量数据是非常繁琐的。这也是低效的,因为相邻切片显示几乎相同的信息。特别是对于需要大量注释数据的基于学习的方法,3D 体积的完整注释不是创建能够很好地泛化的大型和丰富的训练数据集的有效方法。
图 1:使用3D u-net进行体积分割的应用场景。(a)半自动分割:用户注释要分割的每个体积的一些切片。网络预测密集分割。 (b)全自动分割:网络使用来自代表性训练集的带注释切片进行训练,并且可以在非注释卷上运行。
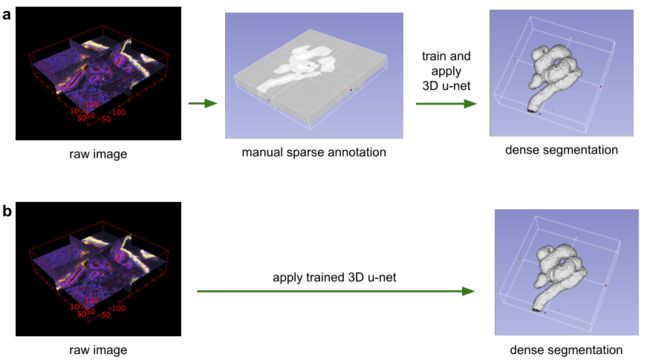
在本文中,我们提出了一个深度网络,它可以学习生成密集的体积分割,但只需要一些带注释的2D切片进行训练。该网络可以以两种不同的方式使用,如图1所示:第一个应用案例仅针对密集化稀疏注释的数据集;第二个从多个稀疏注释的数据集中学习以推广到新数据。这两个案例都具有高度相关性。
该网络基于之前的u-net架构,由一个用于分析整个图像的收缩编码器部分和一个用于产生全分辨率分割的连续扩展解码器部分组成 [11]。虽然u-net是一个完全2D的架构,但本文提出的网络将3D卷作为输入,并使用相应的3D操作对其进行处理,特别是3D convolutions,3D max pooling, 和3D up-convolutional层。此外,我们避免了网络架构[13]中的瓶颈,并使用批量归一化[4]来加快收敛速度。
在许多生物医学应用中,只需要很少的图像来训练一个泛化能力相当好的网络。这是因为每个图像已经包含具有相应变化的重复结构。在体积图像中,这种效果更加明显,因此我们可以只在两个体积图像上训练一个网络,以便推广到第三个。加权损失函数和特殊的数据增强使我们能够仅使用少量手动注释切片来训练网络,即来自稀疏注释的训练数据。
我们展示了所提出的方法在困难的爪蟾肾共焦显微数据集上的成功应用。在其发展过程中,非洲爪蟾肾脏形成了一个复杂的结构[7],这限制了预定义参数模型的适用性。首先,我们提供定性结果来证明少数带注释切片的稠密化质量。这些结果得到定量评估的支持。我们还提供了实验,显示了带注释的切片数量对我们网络性能的影响。基于Caffe[5]的网络实现作为开源提供。
1.1 Related Work
具有挑战性的生物医学2D图像可以通过CNN以接近人类表现的精度进行分割[11,12,3]。由于这一成功,已经进行了几次尝试将3D CNNs应用于生物医学体积数据。Milletari等人[9]提出了一种结合Hough投票法的CNN用于3D分割。然而,他们的方法不是端到端的,只适用于紧凑的团状结构。Kleesiek等人[6]的方法是用于3D分割的少数端到端3D CNN方法之一。然而,它们的网络并不深,在第一次卷积后只有一个最大池;因此,它不能在多个尺度上分析结构。我们的工作基于2D u-net [11],该网络在2015年赢得了多项国际分割和跟踪比赛。u-net的体系结构和数据扩充允许仅从几个带注释的样本中学习具有非常好的泛化性能的模型。它利用了这样一个事实,即适当应用的刚性变换和轻微的弹性变形仍然会产生生物上似是而非的图像。上行卷积架构,如用于语义分割的全卷积网络[8]和u-net,仍然没有广泛传播,我们只知道一种将这种架构推广到3D的尝试[14]。在Tran等人的这项工作中,该架构被应用于视频,并且完整的注释可用于训练。本文的重点是,由于其无缝拼接策略,它可以在稀疏标注的卷上从头开始训练,并且可以在任意大的卷上工作。
2 Network Architecture
图2说明了网络架构。像标准的u-net一样,它有一个分析和综合路径,每个路径有四个解析步骤。在分析路径中,每一层包含两个3 × 3 × 3卷积,每个卷积后跟一个整流线性单元(ReLu),然后是一个2 × 2 × 2最大池化,每个维度的步长为2。在合成路径中,每一层都包括一个2 × 2 × 2的上卷积,每个维度上的步长为2,然后是两个3 × 3 × 3的卷积,每个卷积之后是一个ReLu。分析路径中相同分辨率层的快捷连接为合成路径提供了基本的高分辨率特征。在最后一层中,1×1×1卷积将输出通道的数量减少到标签的数量,在本例中为3个。该架构共有19069955个参数。正如[13]中所建议的,我们通过在最大池化之前将通道数量翻倍来避免瓶颈。我们在合成路径中也采用这种方案。
图 2: 3D u-net架构。蓝框代表要素地图。通道的数量在每个特征图上标出。

网络的输入是具有3个通道的图像的132 × 132 × 116体素块。我们在最后一层的输出分别是x、y和z方向的44×44×28个体素。在体素尺寸为1.76×1.76×2.04 μ m 3 \mu \mathrm{m}^{3} μm3的情况下,对于预测分割中的每个体素,近似感受野变为155×155×180 μ m 3 \mu \mathrm{m}^{3} μm3。因此,每个输出体素都可以访问足够的上下文来有效地学习。
我们还在每次ReLU之前引入了批处理归一化(“BN”)。在[4]中,每批在训练期间用其平均值和标准偏差进行归一化,并使用这些值更新全局统计数据。接下来是一个层,用于显式学习比例和偏差。在测试时,通过这些计算出的全局统计数据和学习到的标度和偏差来进行标准化。然而,我们有一个批量和几个样品。在这样的应用程序中,在测试时使用当前的统计数据效果最好。
该架构的重要部分是加权的softmax损失函数,它允许我们对稀疏注释进行训练。将未标记像素的权重设置为零使得可以仅从标记的像素中学习,从而推广到整个体积。
3 Implementation Details
3.1 Data
我们有三个处于Nieuwkoop-Faber阶段36-37的爪蟾肾胚胎样本[10]。其中一个如图1所示(左)。使用配备有Plan-Apochromat 40x/1.3油浸物镜的Zeiss LSM 510 DUO倒置共焦显微镜,在具有3个通道的四个瓷砖中记录了3D数据,体素尺寸为0.88×0.88×1.02 μ m 3 \mu \mathrm{m}^{3} μm3。第一个通道显示番茄凝集素与488nm激发波长的荧光素偶联。第二个通道显示在405nm激发下DAPI染色的细胞核。第三个通道显示Beta-Catenin使用标记有Cy3的二抗在564nm激发下标记细胞膜。我们使用Slicer3D 2 { }^{2} 2在每个体积中手动注释一些正交的xy、xz和yz切片[2]。根据良好的数据表示选择注释位置,即在所有3个维度上尽可能均匀地采样注释切片。不同的结构被赋予标签0:“小管内”;1:“小管”;2:“背景”,3:“未标注”。未标记切片中的所有体素也获得标记3(“未标记”)。我们对原始分辨率的下采样版本进行了所有的实验,在每个维度上的因子为2。因此,对于我们的样本1、2和3,实验中使用的数据大小在x × y × z维度上分别为248 × 244 × 64、245 × 244 × 56和246 × 244 × 59。对于样本1、2和3,正交(yz、xz、xy)切片中人工注释的切片数量分别为(7、5、21)、(6、7、12)和(4、5、10)。
3.2 Training
除了旋转、缩放和灰度值增强之外,我们还在数据和ground truth标签上应用了平滑的密集变形场。为此,我们在每个方向上间隔32个体素的网格中从标准偏差为4的正态分布中采样随机向量,然后应用B-spline插值。使用带有加权交叉熵损失的softmax比较网络输出和ground truth标签,我们减少常见背景的权重并增加内小管的权重,以达到小管和背景体素对损失的平衡影响。标签为3(“未标记”)的体素对损失计算没有贡献,即权重0。我们使用Caffe [5]框架的随机梯度下降求解器进行网络训练。为了能够训练大型3D网络,我们使用了内存高效的 c u D N N 3 \mathrm{cuDNN}^{3} cuDNN3卷积层实现。数据增强是即时完成的,这会产生与训练迭代一样多的不同图像。我们在NVIDIA TitanX GPU上运行了70000次训练迭代,大约耗时3天。
5 Conclusion
我们引入了一种端到端的学习方法,可以半自动和全自动地从稀疏注释中分割出3D体积。它为非洲爪蟾肾脏的高度可变结构提供了准确的分割。我们在半自动设置的3折交叉验证实验中实现了0.863的平均IoU。在全自动设置中,我们展示了3D架构相对于等效2D实现的性能增益。该网络是从头开始训练的,并且没有针对此应用进行任何优化。我们预计它将适用于许多其他生物医学体积分割任务。它的实现是作为开源提供的。
原文链接:https://arxiv.org/abs/1606.06650
