pytorch_lesson13.5 Xavier方法与kaiming方法(HE初始化)解决激活函数sigmoid or tanh/relu梯度不均匀的问题
提示:仅仅是学习记录笔记,搬运了学习课程的ppt内容,本意不是抄袭!望大家不要误解!纯属学习记录笔记!!!!!!
文章目录
- 前言
- 一、Xavier方法
-
- 1.Xavier初始化参数方法基础理论
- 2.Xavier初始化参数执行方法
-
- 2.1 PyTorch实现Xavier均匀分布的参数创建
-
-
- Sigmoid激活函数
- tanh激活函数
-
- 2.2 PyTorch实现Xavier高斯分布的参数创建
- 二、Kaiming方法(HE初始化)
-
- 1.HE初始化基础理论
- 2.HE初始化在PyTorch中实现
-
- 2.1 PyTorch实现HE初始化的均匀分布参数创建
- 2.2 PyTorch实现HE初始化的正态分布参数创建
- 三、参数初始化的作用局限
前言
本部分内容介绍的是:参数初始化优化方法,也就是针对tanh和Sigmoid激活函数的Xavier方法,以及针对ReLU激活函数的Kaiming方法(HE初始化)。
一、Xavier方法
1.Xavier初始化参数方法基础理论
回顾Glorot条件,我们要求正向传播时候数据流经每一层前后的方差一致,并且反向传播时候数据流经每一层,该层梯度前后方差一致。我们将前者称为向前传播条件,后者称为反向传播条件。我们先看当向前传播条件成立时候,有如下计算过程。
首先,数据流至某一层时,该层神经元接收到的数据可以通过如下方法算得:









2.Xavier初始化参数执行方法
2.1 PyTorch实现Xavier均匀分布的参数创建
我们可以使用torch.nn.init.xavier_uniform_进行初始化参数设置。这里需要注意的是,函数处理的对象是张量,也就是说只要输入张量,就可以自动进行处理。神经网络里生成的参数矩阵跟我们手动实现的参数矩阵是转置关系,我们手动创建一个参数矩阵时,行数代表的是上一层神经元的个数,列数代表的是下一层神经元的个数;而神经网络里生成的参数矩阵正好相反,行数代表的是下一层神经元的个数,列数代表的是上一层神经元的个数。

t = torch.arange(8).reshape(2, 4).float()
print(t)
'''
tensor([[0., 1., 2., 3.],
[4., 5., 6., 7.]])
'''
#我们创建的是两行四列的张量,上一层神经元有4个,下一层神经元有2个,fan_in+fan_out=6
#所以手动创建的参数应该满足在-1到1上均匀分布的情况
t = nn.init.xavier_uniform_(t) # 该函数会在原对象基础上直接进行修改
print(t)
'''
tensor([[ 0.9740, -0.7099, 0.7228, 0.6562],
[ 0.4058, 0.8598, -0.0502, 0.4801]])
'''
Sigmoid激活函数
# 设置随机数种子
torch.manual_seed(200)
# 创建最高项为2的多项式回归数据集
features, labels = tensorGenReg(w=[2, -1], bias=False, deg=2)
# 进行数据集切分与加载
train_loader, test_loader = split_loader(features, labels)
# 初始核心参数
lr = 0.03
num_epochs = 20
# 设置随机数种子
# 设置随机数种子
torch.manual_seed(200)
# 实例化模型
sigmoid_model3 = Sigmoid_class3() # 保留原参数
sigmoid_model3_init = Sigmoid_class3() # 使用Xavier初始化参数
# 修改init模型初始参数
for m in sigmoid_model3_init.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# 创建模型容器
model_l = [sigmoid_model3, sigmoid_model3_init]
name_l = ['sigmoid_model3', 'sigmoid_model3_init']
# print(list(sigmoid_model3_init.parameters()))
train_l, test_l = model_comparison(model_l=model_l,
name_l=name_l,
train_data=train_loader,
test_data=test_loader,
num_epochs=2,
criterion=nn.MSELoss(),
optimizer=optim.SGD,
lr=lr,
cla=False,
eva=mse_cal)
weights_vp(sigmoid_model3, att="grad")
plt.show()
weights_vp(sigmoid_model3_init, att="grad")
plt.show()


我们发现,在num_epochs取值为2的时候(只迭代了一轮),经过Xavier初始化的模型梯度整体更加稳定,并且没有出现梯度消失的情况,反观原始模型sigmoid_model3,有3个sigmoid层,则有四个线性层。第一层的梯度已经非常小了,已经出现了梯度消失的倾向。而我们知道,各层梯度的情况就代表着模型学习的状态,很明显经过初始化的模型各层都处于平稳学习状态,此时模型收敛速度较快。我们也可以通过MSE曲线进行验证。
train_l, test_l = model_comparison(model_l=model_l,
name_l=name_l,
train_data=train_loader,
test_data=test_loader,
num_epochs=num_epochs,
criterion=nn.MSELoss(),
optimizer=optim.SGD,
lr=lr,
cla=False,
eva=mse_cal)
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), train_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train')
plt.show()
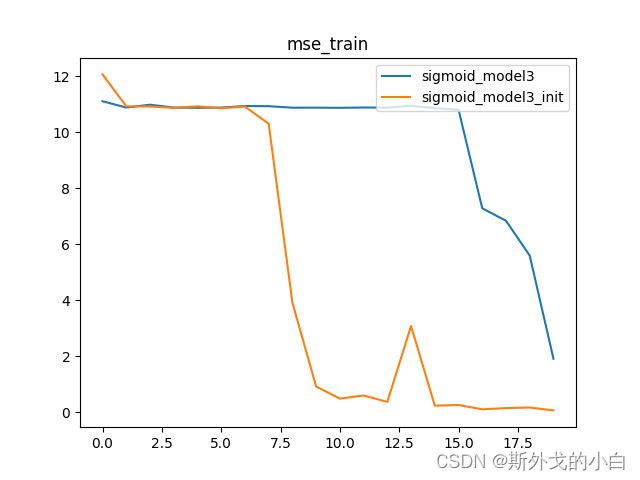
# 测试误差
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), test_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_test')
plt.show()

由此我们可知,Xavier初始化的作用核心在于保证各层梯度取值的平稳分布,从而确保各层模型学习的有效性,最终在模型结果的表现上,经过Xavier初始化参数的模型学习效率更高、收敛速度更快。上述结果也验证了Xavier初始化有效性。
当然,在一些极端情况下,Xavier初始化效果会更加明显。我们以四层sigmoid隐藏层的神经网络为例,观察Xavier初始化在规避梯度消失问题时的效果。
接下来,我们继续增加激活函数的层数,看一个更极端的情况下会发生什么。
# 设置随机数种子
torch.manual_seed(24)
# 实例化模型
sigmoid_model4 = Sigmoid_class4() # 保留原参数
sigmoid_model4_init = Sigmoid_class4() # 使用Xavier初始化参数
# 修改init模型初始参数
for m in sigmoid_model4_init.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# 创建模型容器
model_l = [sigmoid_model4, sigmoid_model4_init]
name_l = ['sigmoid_model4', 'sigmoid_model4_init']
# 核心参数
lr = 0.03
num_epochs = 40
# 模型训练
train_l, test_l = model_comparison(model_l = model_l,
name_l = name_l,
train_data = train_loader,
test_data = test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = lr,
cla = False,
eva = mse_cal)
# 训练误差
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), train_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train')
plt.show()
# 测试误差
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), test_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_test')
plt.show()
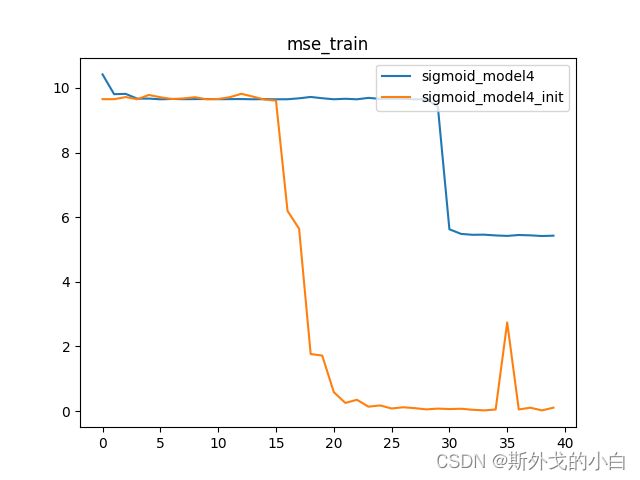

sigmoid_model4是Lesson 13.2中出现严重梯度消失的模型,由于前几层基本丧失学习能力,sigmoid_model4本身效果并不好。但加入Xavier初始化之后,我们发现,init模型能够极大程度规避梯度消失问题,从而获得更好的效果。
不过正如此前所说,相比于sigmoid激活函数,Xavier初始化方法更适用于tanh激活函数,核心原因在于tanh激活函数本身能够生成Zero-centered Data,配合Xavier初始化生成的参数,能够更好的确保各层梯度平稳、确保各层平稳学习。
因为Glorot条件要求每一层的输入值是零均值的,tanh函数容易满足零均值的条件,但是sigmoid生成的数值都大于0,relu函数更加不满足零均值条件。
tanh激活函数
# 设置随机数种子
torch.manual_seed(420)
# 实例化模型
tanh_model3 = tanh_class3() # 保留原参数
tanh_model3_init = tanh_class3() # 使用Xavier初始化参数
# 修改init模型初始参数
for m in tanh_model3_init.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# 创建模型容器
model_l = [tanh_model3, tanh_model3_init]
name_l = ['tanh_model3', 'tanh_model3_init']
# 核心参数
lr = 0.03
num_epochs = 40
# 设置随机数种子
torch.manual_seed(420)
# 模型训练
train_l, test_l = model_comparison(model_l=model_l,
name_l=name_l,
train_data=train_loader,
test_data=test_loader,
num_epochs=num_epochs,
criterion=nn.MSELoss(),
optimizer=optim.SGD,
lr=lr,
cla=False,
eva=mse_cal)
# 训练误差
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), train_l[i], label=name)
plt.legend(loc=1)
plt.title('mse_train')
plt.show()

总体来说,初始化参数之后的多层tahn模型loss函数收敛得更快。
2.2 PyTorch实现Xavier高斯分布的参数创建
类似的,我们可以使用torch.nn.init.xavier_normal_进行初始化参数设置。

# 实例化模型
sigmoid_model2 = Sigmoid_class2()
# 修改init模型初始参数
for m in sigmoid_model2.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
#在第一个线性层上,我们生成的是均值为0,标准差为0.578左右的正太分布
print(list(sigmoid_model2.parameters()))
'''
[Parameter containing:
tensor([[ 0.3022, 0.1873],
[ 0.3836, -0.2401],
[-0.6020, -0.1917],
[-0.4873, 0.1773]], requires_grad=True), Parameter containing:
tensor([ 0.3076, -0.1271, -0.0392, -0.2326], requires_grad=True), Parameter containing:
tensor([[ 0.0124, -0.6300, -0.0161, 0.4529],
[ 0.6640, 0.3979, -0.0418, 0.7152],
[ 0.3333, 0.2480, 0.0730, 0.0560],
[-0.3851, -0.3736, 0.2337, -0.9451]], requires_grad=True), Parameter containing:
tensor([ 0.2734, -0.0804, 0.4638, 0.0934], requires_grad=True), Parameter containing:
tensor([[-1.4520, 0.0319, 0.2793, -0.8681]], requires_grad=True), Parameter containing:
tensor([-0.1576], requires_grad=True)]
'''
二、Kaiming方法(HE初始化)
1.HE初始化基础理论
尽管Xavier初始化能够在Sigmoid和tanh激活函数叠加的神经网络中起到一定的效果,但由于ReLU激活函数属于非饱和类激活函数,并不会出现类似Sigmoid和tanh激活函数使用过程中可能存在的梯度消失或梯度爆炸问题,反而因为ReLU激活函数的不饱和特性,ReLU激活函数的叠加极有可能出现神经元活性消失的问题,很明显,该类问题无法通过Xavier初始化解决。
尽管如此,对参数的初始值进行合理设置,仍然是保证模型有效性的有效方法,同样也能一定程度上解决ReLU激活函数的神经元活性消失问题。目前通用的针对ReLU激活函数的初始化参数方法,是由何凯明在2015年的《Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification》一文中所提出的HE初始化方法,也被称为Kaiming方法。
当然,He初始化也遵循Glorot条件,即参数初始化结果要求正向传播时各层接收到的数据方差保持一致、反向传播时各层参数梯度的方差保持一致,不过由于每一层的激活值(激活函数输出结果)均值不为0,因此Xavier的数学推导过程不再成立。HE初始化仍然是规定参数是满足均值为0的随机变量,并且仍然借助均匀分布和高斯分布进行随机变量创建,不同的是Xavier中参数方差为:
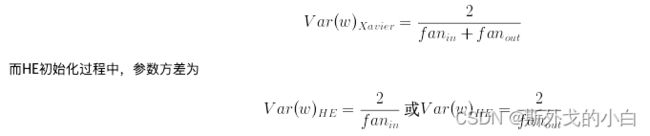
至于到底用的是输入层还是输出层的神经元个数,对我们的模型效果来说差距不大,均可。

2.HE初始化在PyTorch中实现
2.1 PyTorch实现HE初始化的均匀分布参数创建
我们可以使用torch.nn.init.kaiming_uniform_进行初始化参数设置。

相关参数解说:
***- mode:***参数表示选择带入扇入还是扇出的神经元个数进行计算,正如前文所说,理论上二者对建模没有明显影响,可任选其一,但实际由于模型个体差异,在实际使用过程中还是略有差异,我们可以根据实际效果进行选择;
***- a:***为使用ReLU变种激活函数时的修正系数;
***- nonlinearity:***表示所选用的变种ReLU激活函数类型,需要配合a参数使用,相关使用方法我们将在后续介绍ReLU变种激活函数的使用时一并介绍。
在默认的情况下,kaiming_uniform_带入的是扇入的神经元个数
t = torch.arange(12).reshape(2, 6).float()
print(t)
'''
tensor([[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10., 11.]])
'''
#设置随机数种子
torch.manual_seed(420)
t = torch.nn.init.kaiming_uniform_(t) # 此时扇入个数是6
print(t)
'''
tensor([[ 0.6107, -0.6019, 0.9517, -0.7944, -0.3051, -0.6891],
[ 0.7712, 0.3751, -0.4988, -0.7734, -0.5790, -0.1929]])
'''
# 设置随机数种子
# torch.manual_seed(420)
torch.nn.init.kaiming_uniform_(t,a=1) # 此时分母是12
print(t)
'''
tensor([[-0.3609, 0.5153, -0.2975, -0.4626, -0.2181, -0.6905],
[-0.3434, -0.3858, 0.1522, 0.5751, 0.0764, -0.4121]]
'''
# 设置随机数种子
# torch.manual_seed(420)
torch.nn.init.kaiming_uniform_(t,a=1) # 此时分母是12
print(t)
'''
tensor([[-0.3609, 0.5153, -0.2975, -0.4626, -0.2181, -0.6905],
[-0.3434, -0.3858, 0.1522, 0.5751, 0.0764, -0.4121]]
'''
t = torch.arange(18).reshape(6, 3).float()
print(t)
# 设置随机数种子
torch.manual_seed(420)
torch.nn.init.kaiming_uniform_(t) # 此时扇入个数是3
#1.4142135623730951
print(math.sqrt(2)) #这里是根据方差计算公示计算得到的根号2
print(t)
'''
tensor([[ 0.8637, -0.8512, 1.3459],
[-1.1234, -0.4314, -0.9746],
[ 1.0907, 0.5305, -0.7054],
[-1.0938, -0.8188, -0.2728],
[-0.7218, 1.0306, -0.5950],
[-0.9252, -0.4363, -1.3810]])
'''
HE初始化如何帮助模型规避Dead ReLU Problem?核心在于模型初始化时如果参数完全随机选择,就有可能出现初始参数全部输出0的结果,而通过HE初始化的参数不会出现上述情况。(这个结论不太严谨感觉,因为x输入值也是重要的影响因素)。
# 设置随机数种子
torch.manual_seed(420)
# 创建最高项为2的多项式回归数据集
features, labels = tensorGenReg(w=[2, 1], bias=False, deg=2)
# 进行数据集切分与加载
train_loader, test_loader = split_loader(features, labels)
# 初始核心参数
lr = 0.001
num_epochs = 20
# 设置随机数种子
torch.manual_seed(420)
# 实例化模型
relu_model3 = ReLU_class3() # 保留原参数
relu_model3_init = ReLU_class3() # 使用HE初始化参数
# 修改init模型初始参数
for m in relu_model3_init.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_uniform_(m.weight)
# 创建模型容器
model_l = [relu_model3, relu_model3_init]
name_l = ['relu_model3', 'relu_model3_init']
train_l, test_l = model_comparison(model_l = model_l,
name_l = name_l,
train_data = train_loader,
test_data = test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = lr,
cla = False,
eva = mse_cal)
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), train_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train')
plt.show()
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), test_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_test')
plt.show()

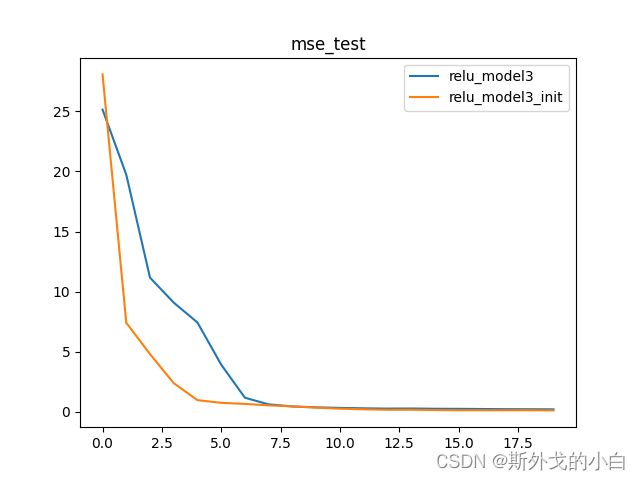
2.2 PyTorch实现HE初始化的正态分布参数创建
类似的,我们可以使用torch.nn.init.kaiming_normal_来进行满足正态分布的初始化参数设置。

# 设置随机数种子
torch.manual_seed(420)
# 创建最高项为2的多项式回归数据集
features, labels = tensorGenReg(w=[2, 1], bias=False, deg=2)
# 进行数据集切分与加载
train_loader, test_loader = split_loader(features, labels)
# 初始核心参数
lr = 0.001
num_epochs = 20
# 设置随机数种子
torch.manual_seed(420)
# 实例化模型
relu_model3 = ReLU_class3() # 保留原参数
relu_model3_init = ReLU_class3() # 使用HE初始化参数
# 修改init模型初始参数
for m in relu_model3_init.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight)
# 创建模型容器
model_l = [relu_model3, relu_model3_init]
name_l = ['relu_model3', 'relu_model3_init']
train_l, test_l = model_comparison(model_l = model_l,
name_l = name_l,
train_data = train_loader,
test_data = test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = lr,
cla = False,
eva = mse_cal)
# 训练误差
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), train_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train')
plt.show()
# 测试误差
for i, name in enumerate(name_l):
plt.plot(list(range(num_epochs)), test_l[i], label=name)
plt.legend(loc = 1)
plt.title('mse_test')
plt.show()


三、参数初始化的作用局限
合理的设置初始参数值能够一定程度上使得模型各层都得到有效的学习,模型训练过程更加平稳、收敛速度也更快。但由于我们设置的是初始条件,伴随着模型不断训练,由于受到激活函数导函数本身特性影响,仍然有可能在迭代过程中出现梯度不均衡的现象。
然而模型一旦开始训练,我们是不能手动参与修改模型参数的。那此时应该如何处理梯度不均衡的问题呢?我们知道,影响梯度计算的三个核心因素,分别是参数状态值、激活值和输入的数据,参数状态值由模型迭代的数学过程决定,激活值很大程度上由我们所选取的激活函数决定,如果从Glorot条件入手,我们就只剩下一个可以人工修改的选项:每一个线性层接收到的数据。