情感识别难?图神经网络创新方法大幅提高性能
作者 | Kevin Shen
译者 | Monanfei
出品 | AI科技大本营(ID: rgznai100)
【导读】最近,深度学习在自然语言处理领域(NLP)取得了很大的进步。随着诸如 Attention 和 Transformers 之类新发明的出现,BERT 和 XLNet 一次次取得进步,使得文本情感识别之类的等任务变得更加容易。本文将介绍一种新的方法,该方法使用图模型在对话中进行情感识别。
什么是情感识别?
简而言之,情感识别(ERC)是对文字背后的情感进行分类的任务。例如,给定一段文字,你能说出说话者是生气、快乐、悲伤还是困惑吗?情感识别在医疗保健、教育、销售和人力资源方面具有许多广泛的应用。从最高的一个层面讲,情感识别任务非常有用,因为许多人认为,这是构建能够与人类对话的智能 AI 的基石。

ERC 帮助健康助理的例子(图片来源于论文1)
当前,大多数 ERC 所基于的两个主要的革新技术是递归神经网络(RNN)和注意力机制。诸如 LSTM 和 GRU 之类的 RNN 能够依次查看文本。当文本很长时,开始部分的模型记忆会丢失。而通过给不同的语句进行加权,注意机制能够很好地解决这一问题。
但是,RNNs + Attention 在考虑来自相邻序列以及说话者的个性、主题和意图的上下文时仍然会遇到困难。再加上缺乏用于个性/情绪的标记基准数据集,不仅要实施而且还要衡量新模型的结效果,这确实变得非常困难。最近的一篇论文《DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation 》使用了图卷积神经网络,采用一种相对创新的方法解决了许多问题,本文将对这篇论文进行介绍和总结。

上下文很重要
在对话中,上下文很重要。简单的 “ Okay” 可以表示 “ Okay?”,“ Okay!” 或 “ Okay ...” 。这取决于你和对方之前说过的内容,你的感受,对方的感受,紧张程度以及许多其他因素。重要的上下文主要有两种:
-
序列的上下文:序列中句子的含义。该上下文处理过去的单词如何影响未来的单词、单词的关系以及语义/句法特征。RNN 模型考虑了序列的上下文。
-
说话者级别的上下文:说话者相互以及自身的依赖性。这种情况涉及说话者之间的关系以及自我依赖性:自己的个性会改变并影响你在谈话过程中的说话方式。
你可能会猜到,大多数模型很难考虑到说话者级别的上下文。事实证明,我们可以使用图卷积神经网络来进行这种形式的建模,而这正是 DialogueGCN 所采用的方法。
将对话表示为图形
在一段对话中,M个说话者/参加者表示为p [1], p [2],...,p [M]。每段发言(某个人发送的一段文字)被表示为U [1],U [2] ,..., u [N]。ERC 的最终目标是准确地将每段发言预测为快乐、悲伤、中立、愤怒、激动、沮丧、厌恶或恐惧中的一种。
整个对话可以构建为如下所示的有向图:
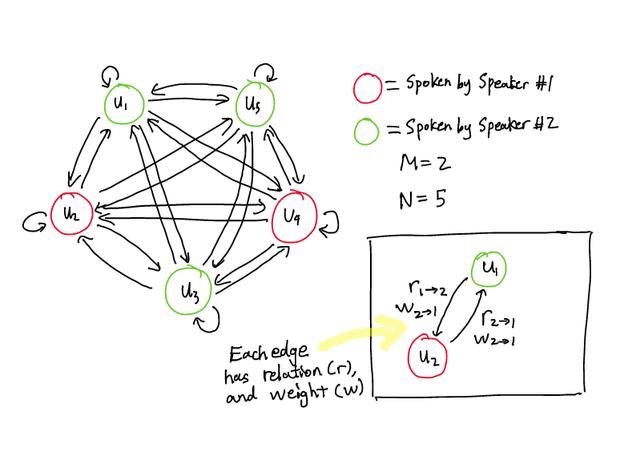
一张包含 2 个说话者和 5 个句子的对话图
G =(V,E,R,W)
-
语段作为节点(V)。边(E)是节点之间的路径/连接。关系(R)是边的不同类型/标签。边权值(W)代表边的重要性。
-
两个节点 v[i] 和 v[j] 之间的每个边都有两个属性:关系(r)和权重(w)。
-
该图是有向的。因此,所有边都是独特的路径。从v[i] 到 v[j] 的边不同于从 v[j] 到 v[i] 的边。
从图中我们可以看到,每个语段都有一条与其自身相连的边。这代表了话语与其自身的关系。更通俗地讲,这代表了发声如何影响发话者的思想。
上下文窗口
图表示的一个主要问题是,如果对话很长,则单个节点可能有许多边。而且,由于每个节点都与其他节点相连,因此随着图的大小增加,节点的边数会呈平方增加。这将消耗大量的计算资源。
为了解决该问题,DialogueGCN 基于具有特定尺寸的上下文窗口构造图表示的边。因此,对于某节点 i,在图中仅连接在过去窗口和将来窗口范围内的节点。
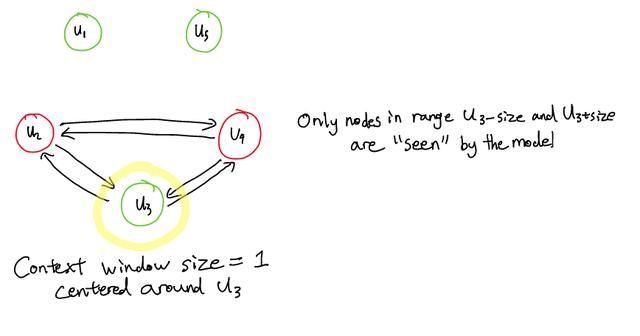
围绕第三句话大小为 1 的上下文窗口
边权值
使用注意力机制计算边权值。设置注意力,使得每个节点的入边权重之和为1。边权值是恒定的,在学习过程中不会改变。简单来说,边权值代表了两个节点之间连接的重要性。
关系
边的关系取决于两件事:
-
说话者依赖性:谁说过 u[i]?谁说 v[j]?
-
时间依赖性:u[i] 是在 u[j] 之前发出的,还是之后?
在对话中,如果有 M 个不同的讲话者,则最多会有 M (u[j] 的讲话者)* M(u[j] 的讲话者)* 2(u [i] 是否在 u [j] 之前出现,或之后)= 2M ² 个关系。
我们可以从上面的示例图中列出所有的关系,如下图所示:
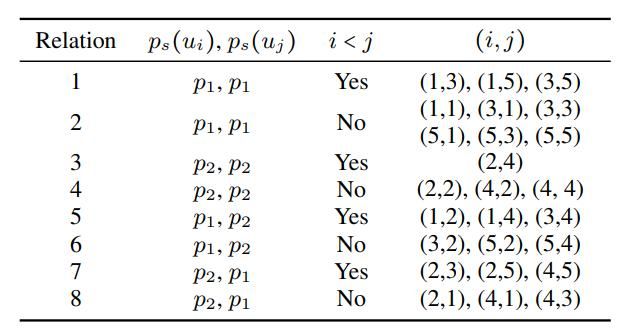
例子中所有可能的关系列表
下图所示为同一个图,其中边的关系根据表格进行了标记:

边缘标记有各自的关系(请参见上表)
在我们的例子中,我们有 8 个不同的关系。在较高的层次上,关系是边的重要属性,因为在对话中谁说什么和什么时候说都很重要。如果 Peter 问一个问题而 Jenny 回答,则不同于 Jenny 先说答案,然后 Peter 问这个问题(时间依赖性)。同样,如果 Peter 向 Jenny 和 Bob 提出相同的问题,他们的回答可能会有所不同(说话者依赖性)。
将关系视为定义连接的类型,而边权值代表连接的重要性。
模型
DialogueGCN 模型使用一种称为图卷积网络(GCN)的图神经网络。
就像上面一样,下图所示为 2 个说话者的 5 段对话的图。
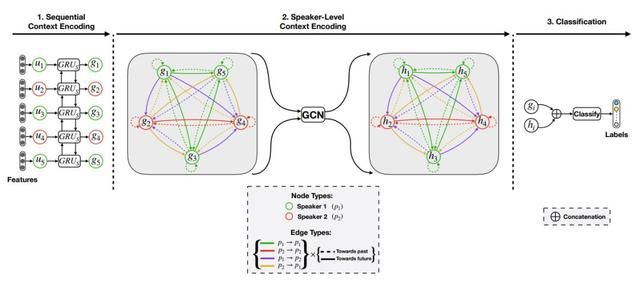
图片来源于论文 1
在阶段 1 中,每个语段 u[i] 表示为一个特征向量,该向量含有对话的顺序信息。该过程由一个顺序上下文编码器的 GRU 实现:将每个语段按照顺序输入该上下文编码器。阶段 1 不需要图结构。具有顺序上下文的新语段表示为 g[1] ,..., g[N]。这是 GCN 的输入。

在阶段 2 中,该模型将构建一个如前文所述的图,并使用特征转换将说话者级别的上下文添加到图中。h[1] ,..., h[N] 表示序列级别和说话者级别的上下文。这是 GCN 的输出。
边和节点的外观差异(虚vs实、不同的颜色)表示不同的关系。例如,绿色 g[1] 到绿色 g[3] 的边为绿色实线代表关系1。
特征转换——嵌入说话者级别的上下文
GCN 最重要的步骤之一是特征转换——如何将说话者级别的上下文嵌入到话语中。我们将首先讨论所使用的技术,然后描述其背后的直觉。
特征转换有两个步骤。
在第 1 步中,对于每个节点h[i],相邻节点的信息(上下文窗口内的节点)被聚集,用以创建新的特征向量h[i]¹ 。

该函数看起来很复杂,但其核心只是网络中具有可学习参数 W[o]¹ 和 W[r]¹ 的层。此外,还需要添加归一化常数 c[i,r]。这些参数可以预先设置,也可以通过网络本身来学习。
如前所述,边权值是恒定的,在过程中不会更改或学习。
在第 2 步中,再次执行相同的操作。邻居信息被汇总,并且类似的函数被应用于接收步骤 1 的输出。在这里,我们使用 W² 和W[o]² 代表训练过程中可学习的参数。

公式2(第二步)
在较高级别上,这两步的实质上是对每个语段的相邻语段信息进行归一化求和。从更深层次上讲,这两步转化的基础是简单的可区分消息传递框架 [2](https://arxiv.org/pdf/1704.01212.pdf)。研究人员采用这种技术来研究图卷积神经网络,从而对关系数据进行建模 [3](https://arxiv.org/abs/1703.06103)。如果你有空闲的时间,我们强烈建议你按顺序阅读这两篇论文。DialogueGCN 的特征转换过程背后的直觉都在这两篇论文中。
GCN的输出在图中用 h [1] ,..., h [N]表示。
在阶段 3 中,将原始的顺序上下文编码向量与说话者级别的上下文编码向量进行串联。这类似于将原始图层与后面的图层组合,从而“汇总”每个图层的输出。
接着,我们将级联的特征向量馈送到全连接的网络中进行分类。最终的输出是语段的不同情绪的概率分布。

论文使用带有 L2 正则化的分类交叉熵损失(https://gombru.github.io/2018/05/23/cross_entropy_loss/)来对模型进行训练。使用该损失函数的原因是,模型需要预测多个标签(情感类别)的概率。
结果
基准数据集
在前文中我们提到缺乏基准数据集。通过使用标记的多模数据集(文本、视频或音频),然后提取其中的文本部分,并且忽略其他的音频或视频数据,论文的作者巧妙地解决了该问题。
DialogueGCN 在以下数据集上进行了评估:
-
IEMOCAP:视频形式的十位独立发言人的双向对话。语段中带有快乐、悲伤、中立、愤怒、激动或沮丧的标签。
-
AVEC:人类与人工智能之间的对话。语段具有四个标签:价值([-1,1])、唤醒([-1,1])、期望([-1,1])和能力([0,∞])。
-
MELD:包含电视连续剧《老友记》中的 1400 个对话和 13000 个语段。MELD 还包含互补的声音和视觉信息。语段被标记为愤怒、厌恶、悲伤、喜悦、惊奇、恐惧或中立。
MELD 具有预定义的训练集、验证集、测试集。AVEC 和 IEMOCAP 没有预定义的划分,因此将它们的 10% 对话用作验证集。
DialogueGCN 与许多基准模型和最新模型进行了对比。其中,DialogueRNN 是该论文某作者的最先进的模型。
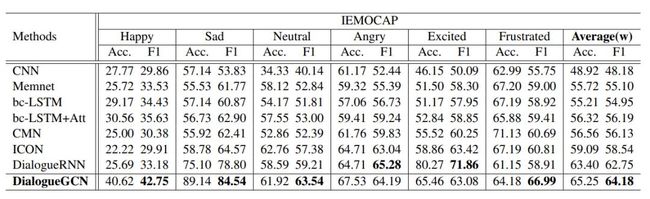
DialogueGCN与其他模型在IEMOCAP数据集上的表现(表摘自[1])
在 IEMOCAP 的 6 个类别中的 4 个类别中,相对于包括 DialogueRNN 在内的所有模型,DialogueGCN 均显示出明显的改进。在“愤怒”类别中,DialogueGCN 本质上与 DialogueRNN 存在联系(GCN 在 F1 评分上仅差 1.09),只有“兴奋”类别显示出足够大的差异。
DialogueGCN 在 AVEC 和 MELD 上产生了相似的结果,超过了现有的 DialogueRNN。
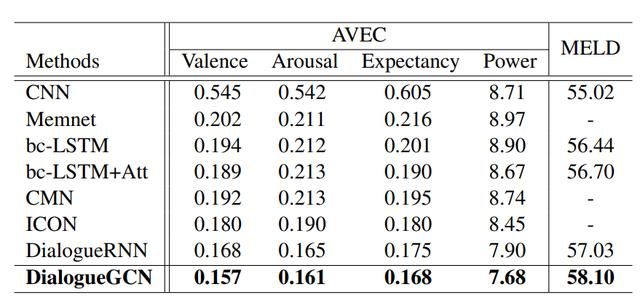
DialogueGCN与其他模型在AVEC和MELD数据集上的表现(表摘自[1])
从结果中可以明显看出,将说话者级别的上下文添加到对话图中,这种方式可以从本质上提高模型的理解能力。由此可见,DialogueRNN 能够很好地捕获顺序上下文,但是缺乏对说话人上下文进行编码的能力。
分析
该实验的一个参数是上下文窗口的尺寸。通过扩展其尺寸,我们可以将边的数量增加到特定的语段上。研究已经发现,尺寸的增加虽然在计算上更加昂贵,但是可以改善结果。
作者还进行了一个有趣的实验:消融研究。一次取下一个编码器,然后重新测量模型的性能。发现说话者级上下文编码器(阶段2)比顺序上下文编码器(阶段1)更重要。
研究还发现,误分类倾向于在以下两种情况下发生:
-
类似的情绪类别,例如“沮丧”和“生气”,或“激动”和“快乐”。
-
简短的话语,例如“好”或“是”。
由于所使用的数据集都是多模式的,而且包含音频和视频,因此可以通过整合音频和视觉多模式学习来提高这两种情况下的准确性。尽管仍然存在分类错误的问题,但是 DialogueGCN 仍在准确性方面取得了非常显著的进步。
重点
-
上下文很重要。一个好的模型不仅要考虑对话的顺序上下文(句子的顺序,单词彼此之间的关联),还要考虑说话者级别的上下文(说话者说什么,当他们说话时,它们如何受到其他说话者和自己的影响)。与传统的序列模型和基于注意力的模型相比,集成说话者级别的上下文是一大进步。
-
序列并不是代表对话的唯一方式。数据的结构可以帮助捕获更多的上下文。在这种情况下,说话者级别的上下文更容易以图形格式编码。
-
图神经网络是 NLP 研究的宝库。聚合邻居信息的关键概念虽然看上去简单,但在捕获数据中的关系方面具有惊人的功能。
原文链接:
https://towardsdatascience.com/emotion-recognition-using-graph-convolutional-networks-9f22f04b244e