更快更强!EfficientFormerV2来了!一种新的轻量级视觉Transformer
转载自:CVHub
Title: Rethinking Vision Transformers for MobileNet Size and Speed
Author: Yanyu Li et al. (Snap Inc.)
Paper: https://arxiv.org/pdf/2212.08059v1.pdf
Github: https://github.com/snap-research/EfficientFormer
Introduction
随着 ViT 的出现,Transformer 模型在计算机视觉领域遍地开花,一层激起一层浪。虽然精度很高,但被人广为诟病的依旧是它的效率问题,说人话就是这东西压根不好部署在移动端。
随后,有许多研究人员提出了很多解决方案来加速注意力机制,例如早先苹果提出的 Mobile-Former 以及前段时间的 EdgeNeXt,均是针对移动端设计的。
本文的思路也很简单,就是仿造 CNNs 圈子中的移动端之王—— MobileNet 来进行一系列的设计和优化。对于端侧部署来讲,模型的参数量(例如 Flash 大小)和延迟对资源受限型的硬件来说至关重要。因此,作者结合了细粒度联合搜索策略,提出了一种具备低延迟和大小的高效网络——EfficientFormerV2 ,该网络在同等量级参数量和延迟下比 MobileNetV2 可以高出4个百分点(ImageNet验证集)。
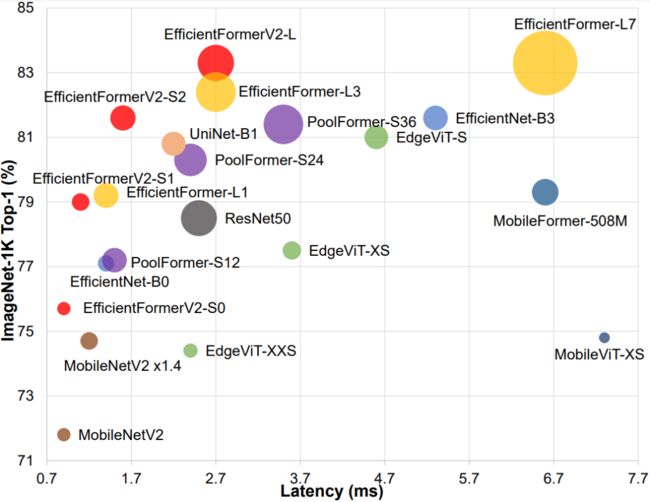 Comparison of model size, speed, and performance
Comparison of model size, speed, and performance
上图所示模型是在 ImageNet-1K 上进行训练所获得的 Top-1 精度。延迟是在 iPhone 12(iOS 16)上进行测量的。每个圆圈的面积与参数数量(模型大小)成正比。可以看出,EfficientFormerV2 在模型更小和推理速度更快的情况下获得了更高的性能。
Framework
先来看下整体的网络长什么样子:
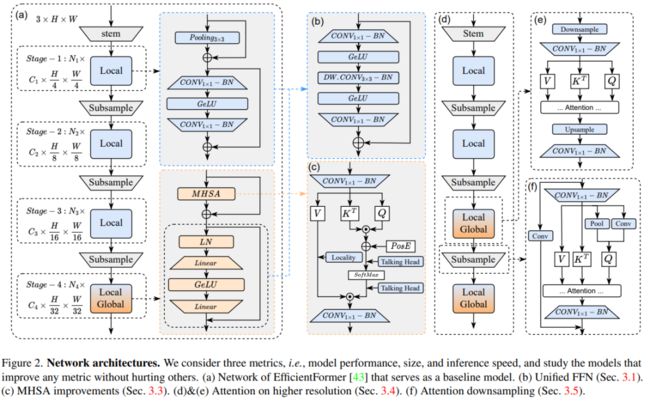 Overall
Overall
既然都叫 EfficientFormerV2,那必然是在上一版的基础上改进了,如图(a)所示。没什么特别新奇的,一个很常规的 ViT 型架构。下面的图表是作者统计的实验改进结果:
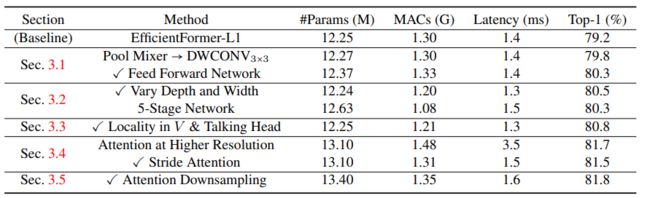 Number of parameters, latency, and performance for various design choices
Number of parameters, latency, and performance for various design choices
基于整体架构图和上述表格,让我们逐步拆解看看究竟做了哪些改进。
Token Mixers vs. Feed Forward Network
通常来说,结合局部信息可以有效提高性能,同时使 ViTs 对明确的位置嵌入缺失表现得更加稳健。PoolFormer 和 EfficientFormer 中都使用了 3×3 的平均池化层(如图 2(a)所示)作为局部的Token Mixers。采用相同卷积核大小的深度可分离卷积(DWCONV)替换这些层不会带来延迟开销,同时性能也能提高 **0.6%**,参数量仅微涨 0.02M。此外,同 NASVit,作者也在 ViTs 的前馈网络(FFN)中注入了局部信息建模层,这也有益于提高性能。
这里,作者直接将原来的 Pooling 层删掉了(下采样越大,理论感受野越大),而是直接替换成 BottleNeck 的形式,先用 1×1 卷积降维压缩,再嵌入 3×3 的深度可分离卷积提取局部信息,最后再通过 1×1 的卷积升维。这样做的一个好处是,这种修改有利于后续直接才用超参搜索技术搜索出具体模块数量的网络深度,以便在网络的后期阶段中提取局部和全局信息。
Search Space Refinement
通过调整网络的深度即每个阶段中的块数和宽度即通道数,可以发现,更深和更窄的网络可以带来:
更好的准确性(0.2% 的性能提升)
更少的参数(0.13M 的参数压缩)
更低的延迟(0.1ms 的推理加速)
同时将这个修改的网络设置为后续 NAS 搜素的 Baseline.
MHSA Improvements
一般的 Transformer 模块都会包含两个组件,即多头注意力 MHSA 和全连接层 FFN. 作者随后便研究了如何在不增加模型大小和延迟的情况下提高注意模块性能的技术。
首先,通过 3×3 的卷积将局部信息融入到 Value 矩阵中,这一步跟 NASVit 和 Inception transformer 一样。
其次,在 Head 维度之间添加 FC 层(就图中标识的Talking Head),增强不同头之间的信息交互。
通过这些修改,可以发现性能进一步提高了,与基线模型相比,准确度达到了 80.8%,同时参数和延迟也基本保持一致。
Attention on Higher Resolution
加入注意力机制普遍都是能够提升性能的。然而,将它应用于高分辨率特征会降低端侧的推理效率,因为它具有与空间分辨率成平方关系的时间复杂度。因此,作者仅在最后的 1/32 的空间分辨率下使用,而对于倒数的第二阶段即 4 倍下采样提出了另外一种 MHSA,这有助于将准确率提高了 0.9% 同时加快推理效率。
先前的解决方案,例如 Cswin transformer 和 Swin transformer 都是采用基于滑动窗口的方式去压缩特征维度,又或者像 Next-vit 一样直接将 Keys 和 Values 矩阵进行下采样压缩,这些方法对于移动端部署并不是一个最佳的选择。这里也不难理解,以 Swin transformer 为例,它在每个 stage 都需要进行复杂的窗口划分和重新排序,所以这种基于 windows 的注意力是很难在移动设备上加速优化的。而对于 Next-vit 来说表面上看虽然进行了压缩,但整个 Key 和 Value 矩阵依旧需要全分辨率查询矩阵(Query)来保持注意力矩阵乘法后的输出分辨率。
本文方法的解决方案可以参考图(d)和(e),整体思路是采用一个带步长的注意力,实现上就是将所有的 QKV 均下采样到固定的空间分辨率(这里是 1/32),并将注意力的输出复原到原始分辨率以喂入下一层。(⊙o⊙)…,有点类似于把瓶颈层的思路又搬过来套。
Attention Downsampling
以往的下采样方式大都是采用带步长的卷积或者池化层直接进行的。不过最近也有一部分工作在探讨 Transformer 模块内部的下采样方式,如 LeViT 和 UniNet 提出通过注意力机制将特征分辨率减半,从而更好的整合全局上下文来进感知下采样。具体的做法也就是将 Query 中的 Token 数量减半,从而对注意力模块的输出进行压缩。
说到这里不经意间有个疑问,Token 数量减少多少才是合适?况且,如果我们直接就对所有的查询矩阵进行降采样的话,这对于较前的 stage 的特征提取是不利的,因为网络的浅层更多的是提取诸如纹理、颜色、边缘等 low-level 的信息,因此从经验上来看是需要保持更高分辨率的。
作者的方法是提出一种结合局部和全局上下文融合的组合策略,如上图(f)所示。为了得到下采样的查询,采用池化层作为静态局部下采样,而 3×3 DWCONV 则作为可学习的局部下采样,并将结果拼接起来并投影到查询矩阵中。此外,注意力下采样模块残差连接到一个带步长的卷积以形成局部-全局方式,类似于下采样瓶颈 或倒置瓶颈层。
Super-Network-Search
上面定义完基础的网络架构后,作者又进一步的应用了一种细粒度联合搜索策略,具体算法步骤如下所示:
 NAS
NAS
整体架构沿用的是超网的结构。
Conclusion
在这项工作中,作者全面研究混合视觉主干并验证对于端侧更加友好的网络结构设计。此外,基于确定的网络结构,进一步提出了在大小和速度上的细粒度联合搜索,并获得了轻量级和推理速度超快的 EfficientFormerV2 模型。
点击进入—>CV微信技术交流群
EfficientFormerV2论文和代码下载
后台回复:EfficientFormerV2,即可下载上面论文和代码
Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看