哈希表(开散列和闭散列)
哈希表
时间复杂度: O(1)
目录
一、哈希函数
二、冲突解决
2.1闭散列-开放定址法
2.2开散列-链地址法(哈希桶)
一、哈希函数
哈希函数的设计原则:
- 哈希函数的定义域必须包括需要存储的全部关键码,且如果散列表允许有m个地址,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常用的哈希函数:
-
直接定址法
取关键字的某个线性函数为哈希地址:H a s h ( K e y ) = A ∗ K e y + B
优点:每个值都有一个唯一位置,效率很高,每个都是一次就能找到。
缺点:使用场景比较局限,通常要求数据是整数,范围比较集中。
使用场景:适用于整数,且数据范围比较集中的情况。 -
除留取余法
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:H a s h ( K e y ) = K e y % p ( p < = m ) ,将关键码转换成哈希地址。
优点:使用场景广泛,不受限制。
缺点:存在哈希冲突,需要解决哈希冲突,哈希冲突越多,效率下降越厉害。
这一部分如果暂时看不懂,可以最后来看这一部分
都说使用除留余数法时,哈希表的大小最好是素数,这样能够减少哈希冲突产生的次数。
- 如果一个序列中,每个元素之间的间隔为1,那么不管哈希表的大小为几,该序列插入哈希表后都是均匀分布的
- 如果一个序列中,每个元素之间的间隔刚好是哈希表大小或哈希表的倍数,那么该序列插入哈希表时,将全部产生冲突
- 哈希表中的分布按照序列的间隔进行分隔,如果序列的间隔恰好是哈希表大小的因子(除了1和本身),那么哈希表的分布就会产生间隔,反之则不会
某个随机序列当中,每个元素之间的间隔是不定的。因此,为了尽量减少冲突,我们就需要让哈希表的大小的因子最少,这样才能最大可能避免让某两个元素之间的间隔是哈希表的因子,所以哈希表的大小最好是素数。
如何实现?
我们如果每次增容时让哈希表的大小增大两倍,那么增容后哈希表的大小就不是素数了。因此我们可以将需要用到的素数序列提前用一个数组存储起来,当我们需要增容时就从该数组当中进行获取就行了。
例如,下面这些都是素数,且它们近似以2倍的形式进行增长,我们就可以将它们用一个数组存储起来。
//获取本次增容后哈希表的大小
size_t GetNextPrime(size_t prime)
{
const int PRIMECOUNT = 28;
//素数序列
const size_t primeList[PRIMECOUNT] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
size_t i = 0;
for (i = 0; i < PRIMECOUNT; i++)
{
if (primeList[i] > prime)
return primeList[i];
}
return primeList[i];
}
注意: 下面的代码中可能没有用到此方法,是为了读者便于理解,但你明白这种方法后,可以自行修改
返回目录
二、冲突解决
2.1闭散列-开放定址法
闭散列,也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表种必然还有空位置,那么可以把产生冲突的元素存放到冲突位置的“下一个”空位置中去
寻找下一位置的方法:
-
线性探测
当发生哈希冲突时,从发生冲突的位置开始,依次向后探测,直到找到下一个空位置为止
Hi=(H0+i)%m ( i = 1 , 2 , 3 , . . . )H0:通过哈希函数对元素的关键码进行计算得到的位置。
Hi:冲突元素通过线性探测后得到的存放位置。
m:表的大小。线性探测的优点:实现非常简单。
线性探测的缺点:一旦发生冲突,所有的冲突连在一起,容易产生数据“堆积”,即不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要多次比较(踩踏效应),导致搜索效率降低。 -
平方探测
线性探测的缺陷是产生冲突的数据堆积在一块,平方探测可以有效解决这一问题
Hi=(H0+i^2)%m ( i = 1 , 2 , 3 , . . . )H0:通过哈希函数对元素的关键码进行计算得到的位置。
Hi:冲突元素通过平方探测后得到的存放位置。
m:表的大小。采用二次探测为产生哈希冲突的数据寻找下一个位置,相比线性探测而言,采用二次探测的哈希表中元素的分布会相对稀疏一些,不容易导致数据堆积。闭散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
实现思路
在闭散列的哈希表中,哈希表的每个位置应该记录存储数据和当前存储位置的状态,有三种状态:
- EMPTY(无数据的位置)
- EXIST(已存储数据)
- DELETE(原本有数据,但现在被删除了)
我们为什么需要额外记录这哈希表每个位置的状态?
因为如果我们不标记状态,当我们寻找40时会挨个遍历整个数组并判断每个位置元素的数值是否等于40,这样也就失去了哈希的意义

所以应该设置存在和不存在的状态,但是如何表示不存在的位置呐,不存在的位置数值设置为0可行吗?答案显然是不可以,如果搜索的元素是0,那到了0位置,该判断这里为空还是找到元素了呐,这里发生了歧义,所以我们设置了exist,empty两种状态。
那我们为什么还要设置delete状态?
当我们删除1000这个元素后,搜索40时,当探测到2这个位置为空就停止下来,但是没事实现搜索40这个功能,所以我们应该增添一个delete状态,当搜索时,遇到exist或delete都应该继续往后面探测;当插入时,我们应该遇到delete或empty都应该在次位置插入
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JlJAufCb-1667664096685)(哈希表.assets/image-20221105095616443.png)]](http://img.e-com-net.com/image/info8/19b17e238caf401ab1cd97f1363d0cef.jpg)
我们引入一个概念负载因子
负载因子 = 表中有效数据个数 / 空间的大小由于表中元素越多,越容易发生冲突,所以
- 负载因子越大,产出冲突的概率越高,增删查改的效率越低。
- 负载因子越小,产出冲突的概率越低,增删查改的效率越高。
这里我们需要指明在进行 闭散列-开放定址法 时,应当使负载因子不能超过某一约定值,否则就需要扩容操作
我们还需要记录哈希表的有效元素个数,以便在之后方便计算负载因子,当负载因子过大就应该及时扩容
哈希表的插入
向哈希表中插入数据的步骤如下:
-
查看哈希表中是否存在该键值的键值对,若已存在则插入失败。
-
判断是否需要调整哈希表的大小,若哈希表的大小为0,或负载因子过大都需要对哈希表的大小进行调整,调整方式如下:
-
若哈希表的大小为0,则将哈希表的初始大小设置为10。
-
若哈希表的负载因子大于0.7,则先创建一个新的哈希表,该哈希表的大小为原哈希表的两倍,之后遍历原哈希表,将原哈希表中的数据插入到新哈希表,最后将原哈希表与新哈希表交换即可。
-
-
将键值对插入哈希表。
-
通过哈希函数计算出对应的哈希地址。
-
若产生哈希冲突,则从哈希地址处开始,采用线性探测向后寻找一个状态为EMPTY或DELETE的位置。
-
将键值对插入到该位置,并将该位置的状态设置为EXIST。
-
-
哈希表中的有效元素个数加一。
注意: 在将原哈希表的数据插入到新哈希表的过程中,不能只是简单的将原哈希表中的数据对应的挪到新哈希表中,而是需要根据新哈希表的大小重新计算每个数据在新哈希表中的位置,然后再进行插入。
哈希表的查找
在哈希表中查找数据的步骤如下:
- 先判断哈希表的大小是否为0,若为0则查找失败。
- 通过哈希函数计算出对应的哈希地址。
- 从哈希地址处开始,采用线性探测向后向后进行数据的查找,直到找到待查找的元素判定为查找成功,或找到一个状态为EMPTY的位置判定为查找失败。
注意: 在查找过程中,必须找到位置状态为EXIST,并且key值匹配的元素,才算查找成功。若仅仅是key值匹配,但该位置当前状态为DELETE,则还需继续进行查找,因为该位置的元素已经被删除了。
哈希表的删除
在哈希表中删除数据的步骤如下:
- 查看哈希表中是否存在该键值的键值对,若不存在则删除失败。
- 若存在,则将该键值对所在位置的状态改为DELETE即可。
- 哈希表中的有效元素个数减一。
代码实现
#include 返回目录
2.2闭散列-链地址法(哈希桶)
开散列,又叫链地址法(拉链法),首先对关键码集合用哈希函数计算哈希地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
与闭散列不同的是,这种将相同哈希地址的元素通过单链表链接起来,然后将链表的头结点存储在哈希表中的方式,不会影响与自己哈希地址不同的元素的增删查改的效率,因此开散列的负载因子相比闭散列而言,可以稍微大一点。
- 闭散列的开放定址法,负载因子不能超过1,一般建议控制在[0.0, 0.7]之间。
- 开散列的哈希桶,负载因子可以超过1,一般建议控制在[0.0, 1.0]之间。
在实际中,开散列的哈希桶结构比闭散列更实用,主要原因有两点:
- 哈希桶的负载因子可以更大,空间利用率高。
- 哈希桶在极端情况下还有可用的解决方案。
哈希桶的极端情况就是,所有元素全部产生冲突,最终都放到了同一个哈希桶中,此时该哈希表增删查改的效率就退化成了O ( N )
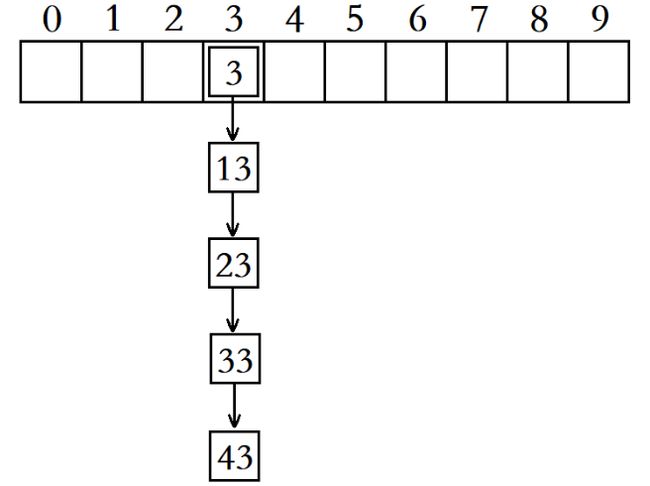
这时,我们可以考虑将这个桶中的元素,由单链表结构改为红黑树结构,并将红黑树的根结点存储在哈希表中。
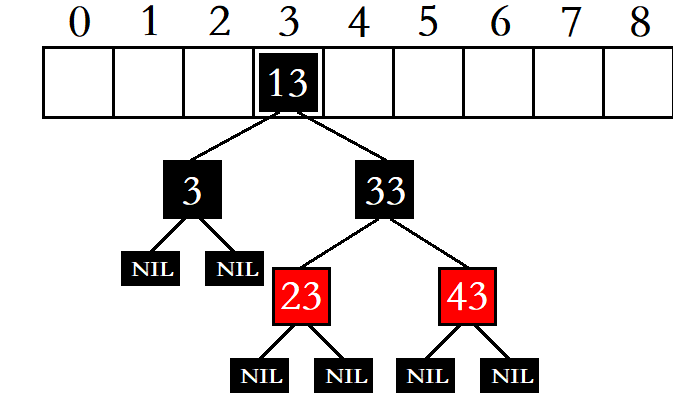
在这种情况下,就算有十亿个元素全部冲突到一个哈希桶中,我们也只需要在这个哈希桶中查找30次左右,这就是所谓的“桶里种树”。
为了避免出现这种极端情况,当桶当中的元素个数超过一定长度,有些地方就会选择将该桶中的单链表结构换成红黑树结构,比如在JAVA中比较新一点的版本中,当桶当中的数据个数超过8时,就会将该桶当中的单链表结构换成红黑树结构,而当该桶当中的数据个数减少到8或8以下时,又会将该桶当中的红黑树结构换回单链表结构。
但有些地方也会选择不做此处理,因为随着哈希表中数据的增多,该哈希表的负载因子也会逐渐增大,最终会触发哈希表的增容条件,此时该哈希表当中的数据会全部重新插入到另一个空间更大的哈希表,此时同一个桶当中冲突的数据个数也会减少,因此不做处理问题也不大。
实现思路
在开散列的哈希表中,哈希表的每个位置存储的实际上是某个单链表的头结点,即每个哈希桶中存储的数据实际上是一个结点类型,该结点类型除了存储所给数据之外,还需要存储一个结点指针用于指向下一个结点。
与闭散列的哈希表不同的是,在实现开散列的哈希表时,我们不用为哈希表中的每个位置设置一个状态字段,因为在开散列的哈希表中,我们将哈希地址相同的元素都放到了同一个哈希桶中,并不需要经过探测寻找所谓的“下一个位置”。
哈希表的开散列实现方式,在插入数据时也需要根据负载因子判断是否需要增容,所以我们也应该时刻存储整个哈希表中的有效元素个数,当负载因子过大时就应该进行哈希表的增容。
哈希表的插入
向哈希表中插入数据的步骤如下:
-
查看哈希表中是否存在该键值的键值对,若已存在则插入失败。
-
判断是否需要调整哈希表的大小,若哈希表的大小为0,或负载因子过大都需要对哈希表的大小进行调整。
- 若哈希表的大小为0,则将哈希表的初始大小设置为10。
- 若哈希表的负载因子已经等于1了,则先创建一个新的哈希表,该哈希表的大小为原哈希表的两倍,之后遍历原哈希表,将原哈希表中的数据插入到新哈希表,最后将原哈希表与新哈希表交换即可。
-
将键值对插入哈希表。
-
通过哈希函数计算出对应的哈希地址。
-
若产生哈希冲突,则直接将该结点头插到对应单链表即可。
-
-
哈希表中的有效元素个数加一。
在将原哈希表的数据插入到新哈希表的过程中,我们只需要遍历原哈希表的每个哈希桶,通过哈希函数将每个哈希桶中的结点重新找到对应位置插入到新哈希表即可,不用进行结点的创建与释放。
注意:
在将原哈希表的数据插入到新哈希表的过程中,不要通过复用插入函数将原哈希表中的数据插入到新哈希表,因为在这个过程中我们需要创建相同数据的结点插入到新哈希表,在插入完毕后还需要将原哈希表中的结点进行释放,多此一举。
为了降低时间复杂度,在增容时取结点都是从单链表的表头开始向后依次取的,在插入结点时也是直接将结点头插到对应单链表
哈希表的查找
在哈希表中查找数据的步骤如下:
- 先判断哈希表的大小是否为0,若为0则查找失败。
- 通过哈希函数计算出对应的哈希地址。
- 通过哈希地址找到对应的哈希桶中的单链表,遍历单链表进行查找即可。
哈希表的删除
在哈希表中删除数据的步骤如下:
- 通过哈希函数计算出对应的哈希桶编号。
- 遍历对应的哈希桶,寻找待删除结点。
- 若找到了待删除结点,则将该结点从单链表中移除并释放。
- 删除结点后,将哈希表中的有效元素个数减一。
代码实现
//每个哈希桶中存储数据的结构
template<class K, class V>
struct HashNode
{
pair<K, V> m_kv;
HashNode* m_next;
HashNode(const pair<K, V>& kv)
:m_kv(kv),
m_next(nullptr)
{}
};
//哈希表
template<class K, class V>
class HashTable
{
typedef HashNode<K, V> Node;
public:
//哈希表的查找
Node* Find(const K& key)
{
if (0 == this->m_Table.size())
{
return nullptr;
}
size_t index = key % this->m_Table.size();
Node* cur = this->m_Table[index];
while (cur)
{
if (cur->m_kv.first == key)
{
return cur;
}
cur = cur->m_next;
}
return nullptr;
}
//哈希表的插入
bool Insert(const pair<K, V>& kv)
{
//1.查找哈希表中是否存在该键值的键值对,如果存在则插入失败
Node* ret = Find(kv.first);
if (ret)
{
return false;
}
//2.判断是否需要调整哈希表的大小
if (this->m_Num == this->m_Table.size())//负载因子超过1或者容量为0
{
//创建一个新的哈希表
vector<Node*> newtable;
size_t newsize = this->m_Table.size() == 0 ? 10 : 2 * this->m_Table.size();
newtable.resize(newsize);
//将原哈希表中的数据插入到新哈希表中
for (auto& e : this->m_Table)
{
Node* cur = e;
while (cur)
{
Node* next = cur->m_next;
size_t index = cur->m_kv.first % newtable.size();
cur->m_next = newtable[index];
newtable[index] = cur;
cur = next;
}
e = nullptr;
}
//将原哈希表和新哈希表进行交换
this->m_Table.swap(newtable);
}
//3.将键值对插入到哈希表中
size_t index = kv.first % this->m_Table.size();
Node* newnode = new Node(kv);
newnode->m_next = this->m_Table[index];
this->m_Table[index] = newnode;
//4.哈希表中的有效元素加1
this->m_Num++;
return true;
}
//哈希表的删除
bool Erase(const K& key)
{
if (0 == this->m_Table.size())
{
return false;
}
size_t index = key % this->m_Table.size();
Node* prev = nullptr;
Node* cur = this->m_Table[index];
while (cur)
{
if (cur->m_kv.first == key)
{
if (prev == nullptr)
{
this->m_Table[index] = cur->m_next;
}
else
{
prev->m_next = cur->m_next;
}
delete cur;
this->m_Num--;
return true;
}
prev = cur;
cur = cur->m_next;
}
return false;
}
private:
vector<Node*> m_Table;
size_t m_Num = 0;
};
int main()
{
HashTable<int, int> HT;
HT.Insert(make_pair(1, 2));
HT.Insert(make_pair(2, 3));
HT.Insert(make_pair(3, 4));
HT.Insert(make_pair(4, 5));
HashNode<int, int>* ret1 = HT.Find(4);
if (ret1)
{
cout << "ret = " << ret1->m_kv.second << endl;
}
else
{
cout << "The key is not exist!" << endl;
}
HT.Erase(4);
HashNode<int, int>* ret2 = HT.Find(4);
if (ret2)
{
cout << "ret = " << ret2->m_kv.second << endl;
}
else
{
cout << "The key is not exist!" << endl;
}
system("pause");
return 0;
}