MobileNet(轻量级神经网络)
## MobileNet(轻量级神经网络)相关知识
1.前言
神经网络体积越来越大,结构越来越复杂,预测和训练需要的硬件资源也逐步增多,往往只能在高算力的服务器中运行深度学习神经网络模型。移动设备因硬件资源和算力的限制,很难运行复杂的深度学习网络模型。
 深度学习领域内也在努力促使神经网络向小型化发展。在保证模型准确率的同时体积更小,速度更快。到了2016年直至现在,业内提出了SqueezeNet、ShuffleNet、NasNet、MnasNet以及MobileNet等轻量级网络模型。这些模型使移动终端、嵌入式设备运行神经网络模型成为可能。而MobileNet在轻量级神经网络中较具代表性。
深度学习领域内也在努力促使神经网络向小型化发展。在保证模型准确率的同时体积更小,速度更快。到了2016年直至现在,业内提出了SqueezeNet、ShuffleNet、NasNet、MnasNet以及MobileNet等轻量级网络模型。这些模型使移动终端、嵌入式设备运行神经网络模型成为可能。而MobileNet在轻量级神经网络中较具代表性。
2.什么是MobileNet
MobileNet网络是由谷歌团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络,相比于传统的卷积神经网络在准确率稍微减少但参数量与运算量大大降低。
3.MobileNet的亮点
- Depthwise Convolution(大大减少参数量与运算量)
- 增加超参数a和β
- MobileNetV2中的倒残差结构(Inverted Residual)和Linear Bottlenecks
4.MobileNet各版本结构
4.1 MobileNetV1
4.2 MobileNetV2
4.3 MobileNetV3
5.深度卷积(DepthWise Convolution)
5.1 传统卷积
- 常规卷积每个卷积核的维度与输入维度相同,每个通道单独做卷积运算后相加,如下图:

卷积核channel=输入特征矩阵channel
输出矩阵channel = 卷积核个数
5.2 DW卷积
常规卷积是利用若干个多通道卷积核对输入的多通道图像进行处理,输出的是既提取了通道特征又提取了空间特征的feature map。
深度卷积(Depthwise convolution, DW)不同于常规卷积操作,深度卷积中一个卷积核只有一维,负责一个通道,一个通道只被一个卷积核卷积,如下图所示:
深度卷积完成后的输出特征图通道数与输入层的通道数相同,无法扩展通道数。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的特征信息。因此需要逐点卷积来将生成的特征图进行组合生成新的特征图。
6.逐点卷积(PointWise Convolution)
逐点卷积(Pointwise Convolution, PW)的运算与标准卷积运算非常相似。

逐点卷积卷积核大小为1×1xM(M为输入数据的维度),每次卷积一个像素的区域。逐点卷积运算会将上一层的特征图在深度(通道)方向上进行加权组合,生成新的特征图,新的特征图的大小与输入数据大小一致,但深度与卷积核的个数相等。这种卷积方式以较少的计算量进行降维或升维操作(改变输出数据的维度)。这种卷积被用来“混合”通道之间的信息。
7. 深度可分离卷积(Depthwise Separable Convolution)
从MobileNetV1开始,到V2、V3的线性瓶颈结构都大量使用了深度可分离卷积。
深度可分离卷积(Depthwise Separable Convolution)是一种卷积结构。它是由一层深度卷积(Depthwise convolution)与一层逐点卷积(Pointwise Convolution)组合而成的,每一层卷积之后都紧跟着BN和ReLU激活函数。跟标准卷积的区别就是精度基本不变的情况下,参数与计算量都明显减少

首先进行深度卷积操作,得出的特征图各通道之间是不关联的。接着进行逐点卷积把深度卷积输出的特征图各通道关联起来。
注:可以把DW卷积和PW卷积看作吃汉堡,DW卷积每次吃一层,先吃面包片,再吃蔬菜,肉,再吃面包片,而PW卷积就是每次吃一口,这一口什么都有
深度可分离卷积使用了更小的空间代价(参数减少)和更少的时间代价(计算量更少)实现了标准卷积层一样的效果(提取特征)。
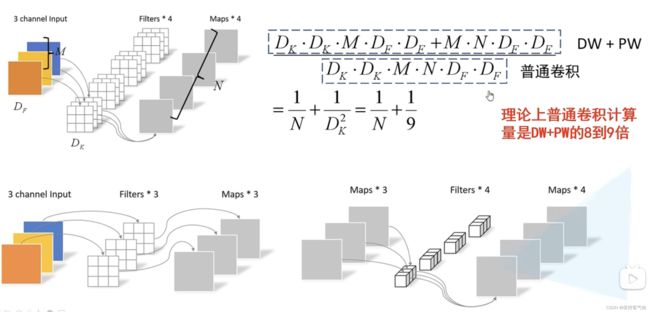
对于普通卷积来说:Dk×Dk×M×N×Df×Df ,前面四个是计算出参数的个数,后面两个Df是每个参数要参与计算的次数,得出来计算量。
普通卷积参数量:dk×dk×M×N,dw卷积参数量:dk×dk×M×N(N=1), pw卷积参数量1×1×M×N
(其中N是输出通道数,pointwise卷积核个数)(Dk:depthwise卷积核尺寸)
举个例子:对于输入特征矩阵为6*6*3的特征矩阵,采用5个4*4*3大小的卷积核进行卷积
1.常规卷积的计算量为:4*4*3*5
2.深度可分离卷积计算量为:4*4*1*5+1*1*3*5
即参数量减少了8到9倍(因为N通常很大,Dk通常是3)·的计算量,只损失了一点准确度
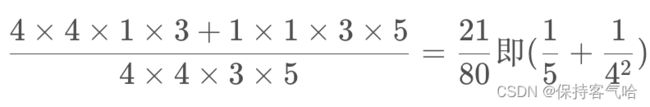
8. 倒残差结构(Inverted Residual)
MobileNetV2中以ResNet的残差(Residuals)结构为基础进行优化,提出了反向残差(Inverted Residuals)的概念,之后也同样运用与MobileNetV3中。
ResNet中提出的残差结构解决训练中随着网络深度增加而出现的梯度消失问题,使反向传播过程中深度网络的浅层网络也能得到梯度,使浅层网络的参数也可训练,从而增加特征表达能力。

ResNet中的残差结构使用第一层逐点卷积降维,后使用深度卷积,再使用逐点卷积升维。
MobileNetV2版本中的残差结构使用第一层逐点卷积升维并使用Relu6激活函数代替Relu,之后使用深度卷积,同样使用Relu6激活函数,再使用逐点卷积降维,降维后使用Linear激活函数。这样的卷积操作方式更有利于移动端使用(有利于减少参数与M-Adds计算量),因维度升降方式与ResNet中的残差结构刚好相反,MobileNetV2将其称之为反向残差(Inverted Residuals)。

9. 线性瓶颈(Linear Bottleneck)
线性瓶颈英文为Linear Bottleneck,是从Bottleneck结构演变而来的,被用于MobileNetV2与V3。
Bottleneck结构首次被提出是在ResNet网络中。该结构第一层使用逐点卷积,第二层使用3×3大小卷积核进行深度卷积,第三层再使用逐点卷积。MobileNet中的瓶颈结构最后一层逐点卷积使用的激活函数是Linear,所以称其为线性瓶颈结构(Linear Bottleneck)。线性瓶颈结构有两种,第一种是步长为1时使用残差结构,第二种是步长为2时不使用残差结构。