Numpy库(二):NumPy的数组类ndarray
NumPy的数组类称为ndarray,也被称为别名 array。请注意,numpy.array这与标准Python库类不同array.array,后者仅处理⼀维数组且功能较少。
一. ndarray对象的属性
| 属性 | 说明 |
|---|---|
| .ndim | 轴的数量或维度的数量(通俗理解就是二维的行数) |
| .shape | ndarray对象的尺度,对于矩阵,n行m列 |
| .size | ndarray对象元素的个数,相当于.shape中n*m的值(通俗理解就是长方体 长x宽x高) |
| .dtype | ndarray对象的元素类型 |
| .itemsize | ndarray对象中每个元素的大小,以字节为单位 |
import numpy as np
arr = np.random.randint(0,100,size = (2,3,2))
print(arr.ndim)
print(arr.shape)
print(arr.size)
print(arr.dtype)
print(arr.itemsize)

二. ndarray的数据类型
2.1、常用数据类型
| 数据类型 | 说明 |
|---|---|
| bool | 布尔类型,True或False |
| intc | 与c语言中的int类型一致,一般是int32或int64 |
| intp | 用于索引的整数,与c语言中ssize_t一致,int32或int64 |
| int8 | 字节长度的整数,取值:[−128,127] |
| int16 | 16位长度的整数,取值 : [−32768,32767] |
| int32 | 32位长度的整数,取值 : [−231,231−1] |
| int64 | 64位长度的整数,取值 : [ − 2 ^63 , 2 ^63 − 1 ] |
| uint8 | 8位无符号整数,取值 : [0,255] |
| uint16 | 16位无符号整数,取值 : [0,65535] |
| uint32 | 32位无符号整数,取值:[0, 232‐1] |
| uint64 | 32位无符号整数,取值:[0, 264‐1] |
| float16 | 16位半精度浮点数:1位符号位,5位指数,10位尾数 |
| float32 | 32位半精度浮点数:1位符号位,8位指数,23位尾数 |
| float64 | 64位半精度浮点数:1位符号位,11位指数,52位尾数 |
| complex64 | 复数类型,实部和虚部都是32位浮点数 |
| complex128 | 复数类型,实部和虚部都是64位浮点数 |
| str | 字符串类型 |

2.2、数据类型转换
1)、asarray转换是指定类型
import numpy as py
arr = [1,2,3,4,5,6]
np.asarray(arr,dtype='float') #将列表进⾏变换

2)、astype 直接类型转换
import numpy as py
arr = np.random.randint(0,10,size=5,dtype='int16')
arr.astype('float') # 将列表类型进⾏变换

三. ndarray的数组运算
3.1、加减乘除幂运算
import numpy as np
arr1 = np.array([1,2,3,4,5])
arr2 = np.array([2,3,1,5,9])
arr1 - arr2 # 减法
arr1 * arr2 # 乘法
arr1 / arr2 # 除法
arr1**arr2 # 两个星号表示幂运算
3.2、逻辑运算
import numpy as np
arr1 = np.array([1,2,3,4,5])
arr2 = np.array([1,0,2,3,5])
arr1 < 5
arr1 >= 5
arr1 == 5
arr1 == arr2
arr1 > arr2
3.3、数组与标量计算
import numpy as np
arr = np.arange(1,10)
1/arr
arr+5
arr*5
3.4、*=、+=、-=操作
某些操作(例如+=和=)只会修改现有数组,⽽不是创建⼀个新数组*
import numpy as np
arr1 = np.arange(5)
arr1 +=5
arr1 -=5
arr1 *=5
# arr1 /=5 不⽀持运算
四. 数组的赋值、视图、拷贝
4.1、赋值
数组赋值不会创建新的数组对象,只是创建了一个原对象的引用。当某一个引用改变了数组,所有的引用的数据都会改变
import numpy as np
a = np.random.randint(0,100,size = 5)
b = a
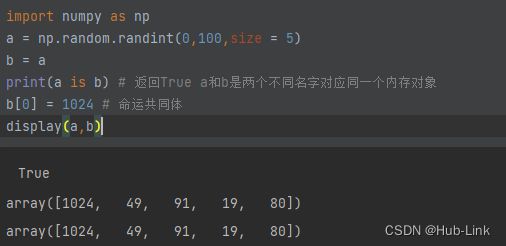
print(a is b) # 返回True a和b是两个不同名字对应同⼀个内存对象
b[0] = 1024 # 命运共同体
display(a,b)
4.2、视图
视图,使用view方法创建一个相同数据的新数组对象。共享数据,但是是不同的对象
import numpy as np
a = np.random.randint(0,100,size = (4,5))
b = a.view() # 使⽤a中的数据创建⼀个新数组对象
a is b # 返回False a和b是两个不同名字对应同⼀个内存对象
b.base is a # 返回True,b视图的根数据和a⼀样
b.flags.owndata # 返回False b中的数据不是其⾃⼰的
a.flags.owndata # 返回True a中的数据是其⾃⼰的
b[0,0] = 1024 # a和b的数据都发⽣改变
display(a,b)

4.3、拷贝
拷贝需要使用copy.() 方法,生成一个完整的数组,不在是共享数据,而是会创建一会自己的内存对象
import numpy as np
a = np.random.randint(0,100,size = (4,5))
b = a.copy()
print(b is a) # 返回False a和b是两个不同名字对应同⼀个内存对象
print(b.base is a) # 返回False b视图的根数据和a不一样
print(b.flags.owndata) # 返回True b中的数据是其⾃⼰的
print(a.flags.owndata) # 返回True a中的数据是其⾃⼰的
b[0,0] = 1024 # b改变,a不变,分道扬镳
display(a,b)

五. 数组索引、切⽚和迭代
5.1、基本索引和切⽚
numpy中数组切⽚是原始数组的视图,这意味着数据不会被复制,视图上任何数据的修改都会反映到原
数组上
arr = np.array([0,1,2,3,4,5,6,7,8,9])
arr[5] #索引 输出 5
arr[5:8] #切⽚输出:array([5, 6, 7])
arr[2::2] # 从索引2开始每两个中取⼀个 输出 array([2, 4, 6, 8])
arr[::3] # 不写索引默认从0开始,每3个中取⼀个 输出为 array([0, 3, 6, 9])
arr[1:7:2] # 从索引1开始到索引7结束,左闭右开,每2个数中取⼀个 输出 array([1, 3, 5])
arr[::-1] # 倒序 输出 array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
arr[::-2] # 倒序 每两个取⼀个 输出 array([9, 7, 5, 3, 1])
arr[5:8]=12 # 切⽚赋值会赋值到每个元素上,与列表操作不同
temp = arr[5:8]
temp[1] = 1024
arr # 输出:array([ 0, 1, 2, 3, 4, 12, 1024, 12, 8, 9])
对于⼆维数组或者⾼维数组,我们可以按照之前的知识来索引,当然也可以传⼊⼀个以逗号隔开的索引
列表来选区单个或多个元素
arr2d = np.array([[1,3,5],[2,4,6],[-2,-7,-9],[6,6,6]]) # ⼆维数组 shape(3,4)
arr2d[0,-1] #索引 等于arr2d[0][-1] 输出 5
arr2d[0,2] #索引 等于arr2d[0][2] == arr2d[0][-1] 输出 5
arr2d[:2,-2:] #切⽚ 第⼀维和第⼆维都进⾏切⽚ 等于arr2d[:2][:,1:]
arr2d[:2,1:] #切⽚ 1 == -2 ⼀个是正序,另个⼀是倒序,对应相同的位置
# 输出:
#array([[3, 5],
# [4, 6]])
5.2、花式索引和索引技巧
整数数组进⾏索引即花式索引,其和切⽚不⼀样,它总是将数据复制到新数组中
import numpy as np
#⼀维
arr1 = np.array([1,2,3,4,5,6,7,8,9,10])
arr2 = arr1[[1,3,3,5,7,7,7]] # 输出 array([2, 4, 4, 6, 8, 8, 8])
arr2[-1] = 1024 # 修改值,不影响arr1
#⼆维
arr2d = np.array([[1,3,5,7,9],[2,4,6,8,10],[12,18,22,23,37],
[123,55,17,88,103]]) #shape(4,5)
arr2d[[1,3]] # 获取第⼆⾏和第四⾏,索引从0开始的所以1对应第⼆⾏
# 输出 array([[ 2, 4, 6, 8, 10],
# [123, 55, 17, 88, 103]])
arr2d[([1,3],[2,4])] # 相当于arr2d[1,2]获取⼀个元素,arr2d[3,4]获取另⼀个元素
# 输出为 array([ 6, 103])
# 选择⼀个区域
arr2d[np.ix_([1,3,3,3],[2,4,4])] # 相当于 arr2d[[1,3,3,3]][:,[2,4,4]]
arr2d[[1,3,3,3]][:,[2,4,4]]
# ix_()函数可⽤于组合不同的向量
# 第⼀个列表存的是待提取元素的⾏标,第⼆个列表存的是待提取元素的列标
# 输出为
# array([[ 6, 10, 10],
# [ 17, 103, 103],
# [ 17, 103, 103],
# [ 17, 103, 103]])
boolean值索引
names = np.array(['softpo','Brandon','Will','Michael','Will','Ella','Daniel','softpo','Will','Brandon'])
cond1 = names == 'Will'
cond1
# 输出array([False, False, True, False, True, False, False, False, True,False])
names[cond1] # array(['Will', 'Will', 'Will'], dtype='
arr = np.random.randint(0,100,size = (10,8)) # 0~100随机数
cond2 = arr > 90
# 找到所有⼤于90的索引,返回boolean类型的数组 shape(10,8),⼤于返回True,否则False
arr[cond2] # 返回数据全部是⼤于90的
六. 数组 形状操作
6.1、数组变形
import numpy as np
arr1 = np.random.randint(0,10,size = (3,4,5)) # 创建一个 3*4*5的三维数组
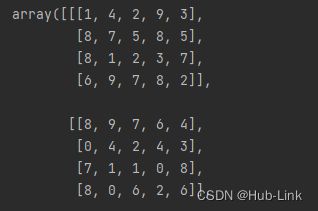
arr2 = arr1.reshape(10,6) # 改变成 10*6 的二维数组,返回新数组
arr2

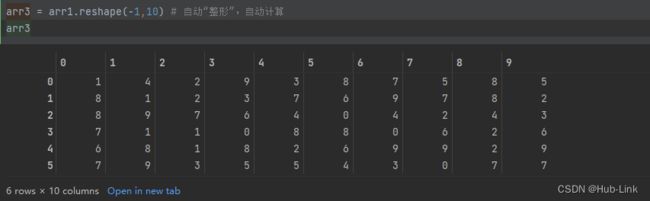
arr3 = arr1.reshape(-1,10) # ⾃动“整形”,⾃动计算
arr3
arr4 = arr1.reshape(-1,9) # ⾃动“整形”,⾃动计算
arr4

从上面的示例可以看出,三维数组转成二维数组或者一维,数据个数一定要相同的。
6.2、数组转置
import numpy as np
arr1 = np.random.randint(0,10,size = (3,5)) # shape(3,5)
arr1
arr1.T # shape(5,3) 转置

6.3、数组堆叠
import numpy as np
arr1 = np.array([[1,2,3]])
arr2 = np.array([[4,5,6]])
np.concatenate([arr1,arr2],axis = 0)
# 串联合并shape(2,3) axis = 0表示第⼀维串联 输出为
# array([[1, 2, 3],[4, 5, 6]])
np.concatenate([arr1,arr2],axis = 1)
# shape(1,6) axis = 1表示第⼆维串联 输出为:array([[1, 2, 3, 4, 5, 6]])
np.hstack((arr1,arr2)) # ⽔平⽅向堆叠 输出为:array([[1, 2, 3, 4, 5, 6]])
np.vstack((arr1,arr2))
# 竖直⽅向堆叠,输出为:
# array([[1, 2, 3],[4, 5, 6]])
6.4、split数组拆分
import numpy as np
arr = np.random.randint(0,10,size = (6,5)) # shape(6,5)
np.split(arr,indices_or_sections=2,axis = 0) # 在第⼀维(6)平均分成两份
np.split(arr,indices_or_sections=[2,3],axis = 1) # 在第⼆维(5)以索引2,3为断点分割成3份
np.vsplit(arr,indices_or_sections=3) # 在竖直⽅向平均分割成3份
np.hsplit(arr,indices_or_sections=[1,4]) # 在⽔平⽅向,以索引1,4为断点分割成3份