python数据分析与挖掘实战——挖掘建模学习记录(一)
1.分类与预测
1.1回归分析-Logistic回归分析
模型
应变量为二分变量
![]()
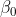 :无自变量时的,优势比的自然对数
:无自变量时的,优势比的自然对数
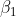 :某自变量变化时,y=1优势比的自然对数
:某自变量变化时,y=1优势比的自然对数
代码
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
# 参数初始化
filename = '../data/bankloan.xls'
data = pd.read_excel(filename)
x = data.iloc[:,:8].values
#iloc[]函数,全称为index location,即对数据进行位置索引,从而在数据表中提取出相应的数据
#注意:在iloc中a:b是左到右不到的,即lioc[1:3,:]是从行索引从1到2,所有列索引的数据。
y = data.iloc[:,8].values
lr = LR() # 建立逻辑回归模型
lr.fit(x, y) # 用筛选后的特征数据来训练模型
print('模型的平均准确度为:%s' % lr.score(x, y))ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
模型的平均准确度为:0.8085714285714286问题
代码运行可以出结果,但是报错,解决如下
这是说训练模型的时候,参数的迭代次数达到了限制(默认max_iter=100),但是两次迭代参数变化还是比较大,仍然没有在一个很小的阈值以下,这就叫没有收敛。
不过,这只是一个警告(温馨提示)而已,我们要么选择 1.忽略,要么 2.增大最大迭代次数,要么 3.更换其他的模型或者那个参数solver,要么 4.将数据进行预处理,提取更有用的特征。
————————————————
版权声明:本文为CSDN博主「音程」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_43391414/article/details/113144702
1.2 ID3决策树
模型
采用划分后样本集的不确定性作为衡量划分好坏的标准,用信息增益值度量不确定性;信息增益值越大,不确定性越小。
代码
import pandas as pd
# 参数初始化
filename = '../data/sales_data.xls'
data = pd.read_excel(filename, index_col = '序号') # 导入数据
# 数据是类别标签,要将它转换为数据
# 用1来表示“好”“是”“高”这三个属性,用-1来表示“坏”“否”“低”
data[data == '好'] = 1
data[data == '是'] = 1
data[data == '高'] = 1
data[data != 1] = -1
x = data.iloc[:,:3].astype(int)
#取data的前三列所有数据,并且把里面的值都转换为整型
y = data.iloc[:,3].astype(int)
#取data的第三列所有数据,并且把里面的值都转换为整型
#iloc[a:b,c]:取行索引从a到b-1,列索引为c的数据
from sklearn.tree import DecisionTreeClassifier as DTC
dtc = DTC(criterion='entropy')
# 建立决策树模型,基于信息熵
dtc.fit(x, y)
# 训练模型
# 导入相关函数,可视化决策树。
# 导出的结果是一个dot文件,需要安装Graphviz才能将它转换为pdf或png等格式。
from sklearn.tree import export_graphviz
x = pd.DataFrame(x)
1.3人工神经网络-BP神经网络算法
模型
特征:利用输出后的误差来估计输出层的直接前导层的误差,再用这个误差估计更前一层的误差,如此一层一层的反向传播下去,就获得了所有其他各层的误差估计。

代码
2.聚类分析
聚类分析实在没有给定分类的情况下,根据数据相似度进行样本分组的一种方法,划分的原则时组内样本最小化而组间距离最大化。
2.1 K-Means聚类算法
模型

代码
# -*- coding: utf-8 -*-
import pandas as pd
# 参数初始化
inputfile = '../data/consumption_data.xls' # 销量及其他属性数据
outputfile = '../tmp/data_type.xls' # 保存结果的文件名
k = 3 # 聚类的类别
iteration = 500 # 聚类最大循环次数
data = pd.read_excel(inputfile, index_col = 'Id') # 读取数据
data_zs = 1.0*(data - data.mean())/data.std() # 数据标准化
from sklearn.cluster import KMeans
model = KMeans(n_clusters = k, n_jobs = 4, max_iter = iteration,random_state=1234) # 分为k类,并发数4
model.fit(data_zs) # 开始聚类
# 简单打印结果
r1 = pd.Series(model.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) # 找出聚类中心
r = pd.concat([r2, r1], axis = 1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(data.columns) + ['类别数目'] # 重命名表头
print(r)
# 详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) # 详细输出每个样本对应的类别
r.columns = list(data.columns) + ['聚类类别'] # 重命名表头
r.to_excel(outputfile) # 保存结果
def density_plot(data): # 自定义作图函数
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
p = data.plot(kind='kde', linewidth = 2, subplots = True, sharex = False)
[p[i].set_ylabel('密度') for i in range(k)]
plt.legend()
return plt
pic_output = '../tmp/pd' # 概率密度图文件名前缀
for i in range(k):
density_plot(data[r['聚类类别']==i]).savefig('%s%s.png' %(pic_output, i)) R F M 类别数目
0 -0.160451 1.114802 0.392844 341
1 3.455055 -0.295654 0.449123 40
2 -0.149353 -0.658893 -0.271780 559
问题
遇到问题, 解决
参考https://machinelearningmastery.com/how-to-fix-futurewarning-messages-in-scikit-learn/
2.2聚类分析的评价
purity评价法:
purity评价法是一种极为简单的聚类评价方法,只需计算聚类书占总数的比例
RI评价法:
![]()
R是指被聚在一类的两个对象被正确分类了;
W是指不应该被聚在一类的两个对象被正确分开了
M是指不应该被放在一类的对象被放在了一类
D是指不应该分开的对象被错误的分开了
F值评价法:
![]()
式中:
![]()
![]()