ChatGPT等GPT-3.5系列大模型的鲁棒性如何?
来自:FudanNLP
最近ChatGPT的爆火,展现出了 GPT-3.5 模型在各种自然语言处理任务中非常出色的性能,在很多任务上展示出了能够与人类媲美的理解和推理能力。
然而,它们在处理开放世界的各种复杂性方面的能力和鲁棒性尚未被完全探索。我们急迫的想知道,这类大模型的鲁棒性真正如何?因此,本研究对 GPT-3.5 系列的大模型进行了全面的实验分析,以探索其大模型的鲁棒性。
访问 http://arxiv.org/abs/2303.00293
或点击 阅读原文 获取原文链接


ABSTRACT
GPT-3.5 模型在各种自然语言处理任务中表现出了出色的性能,展示了它们强大的理解和推理能力。
然而,它们对于处理开放世界的各种复杂性的能力和鲁棒性尚未得到探索,而这对于评估模型的稳定性非常重要并且是建立可信 AI 的关键方面。
在本研究中,我们对 GPT-3.5 进行了全面的实验分析以探索其鲁棒性,使用涵盖了 9 个广泛使用的自然语言理解任务的 21 个数据集(共包括约 116K 测试样例)和来自TextFlint的 66 个文本变形。
论文速看
通过详细的实验和分析,我们得出以下三点结论:
1. 模型理解能力的来源:
预训练、代码训练、指令微调机制共同对模型理解能力的提升起到了决定性作用。我们推测预训练为模型提供了基础的语义理解能力,代码训练提升了模型的语义依赖和理解能力,而指令微调提升了模型对任务的泛化能力。
2. 鲁棒性的影响因素:
指令微调阶段仍然采用的有监督训练方式,可能是一个导致指令和任务都存在与“预训练-微调”范式一样的鲁棒性问题的重要原因。因此,除了对于任务的鲁棒性研究,对于指令鲁棒性的也需要进一步研究。
3. 任务标签词和种类的一致性:
指令微调阶段对模型自然语言理解的表现起到重要作用,具体表现在指令微调阶段和实际应用阶段的任务标签词一致性和标签种类一致性。因此,为了确保这种一致性,Prompt的设计需要考虑到这两个方面,指导模型正确地理解和使用任务标签,同时适应不同的标签种类和应用场景。
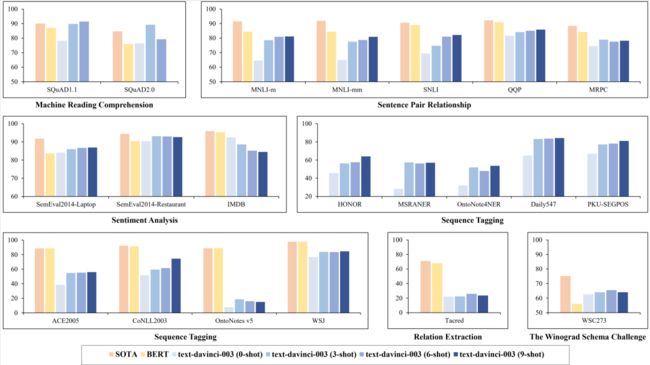
具体结论如下:
1. 部分数据集测试结果惊艳:
GPT-3.5在大多数自然语言处理任务上,达到了最好结果超过了在特定任务上进行监督训练的模型。其中,GPT-3.5在阅读理解和情感分析任务上表现出色,但是在序列标注和关系抽取任务中面临极大挑战。
2. 缺乏鲁棒性:
GPT-3.5在绝大多数自然语言理解任务上依然存在与“预训练-微调”方法相同的鲁棒性问题。但是,GPT-3.5在某些任务上的鲁棒性达到了SOTA,比如:情感分析,阅读理解和WSC任务。
3. 鲁棒性提升并不稳定:
在少样本场景下,GPT-3.5的鲁棒性提升情况在不同任务之间差异较大。比如,GPT-3.5的鲁棒性在细粒度情感分析任务中明显提升,但是在自然语言推理和语义匹配任务中下降。
4. 提示敏感性:
输入指令(即提示)的变化对结果影响程度较高,GPT3.5对于指令变化的鲁棒性仍需提升。在情感分析、自然语言推理、语义匹配、阅读理解任务中,GPT-3.5在不同提示之间的方差较大。
5. 数字敏感性:
GPT3.5对数字的敏感性远高于预训练-微调模型。例如,在NumWord变换中--用不同的数字替换句子中的数字,GPT-3.5表现出非常高的敏感性。
6. 任务标签的敏感性:
GPT-3.5在指令微调阶段的任务构建方式(包括任务标签词和任务类型)会对模型产生较大影响。在情感分析的二分类数据集IMDB中,模型会给出大量“中立”(neutral)的回答,而这个回答并不属于实际的标签空间,从而导致模型性能下降。
7. 零样本/少样本场景下表现显著提升:
在零样本和少样本场景下,GPT-3.5的表现在大多数自然语言理解任务上超过了现有的零样本/少样本学习模型,尤其是在阅读理解、自然语言推理和语言匹配的任务中。
8. 上下文学习能力:
1-shot与0-shot相比,GPT-3.5的效果在大部分任务上都有提升。但是,1-shot、3-shot、6-shot、9-shot之间模型性能没有显著变化。需要注意的是,增加提示中的实例数量会显著提升序列标注任务的表现。
9. GPT系列模型的差异:
GPT-3.5系列(text-davinci-003, text-davinci-002)与GPT-3系列(text-davinci-001)相比,在大多数NLU任务中性能显著提升,尤其是在需要更高水平语言理解的任务中,例如阅读理解,自然语言推理和序列标记。

责任编辑:窦士涵、刘妍
最后给大家推荐一下最近小编从最新的斯坦福NLP的公开课都放到了bilibili上了,都已做了中英翻译,大部分已经更新完毕了,给需要的小伙伴~
是最新的呦~
目录
词向量
神经分类器
反向传播和神经网络
句法结构
RNN
LSTM
机器翻译、Seq2Seq和注意力机制
自注意力和Transformer
Transformers和预训练
问答
自然语言生成
指代消解
T5和大型预训练模型
待更...

点击阅读原文直达b站~
进NLP群—>加入NLP交流群