小知识·BitTorrent 简介
BitTorrent 简介

从 P2P 说起
经常在网上飙车的老司机应该都知道 BT 下载,但是有时候拿到了种子却下载不动,会不会很抓狂,是不是还觉得是自己网不行,那作为一个合格的老司机,我们需要探究一下下载不动的原因是什么,BT的运作方式是怎样的,如果你也有这样的疑惑,那么,系好安全带,我们一起来了解一下什么是 BT。
2001年4月,程序员布莱姆·科恩设计了一种协议,然后在2001年7月2日,他发布了 BitTorrent 客户端的第一个实现。
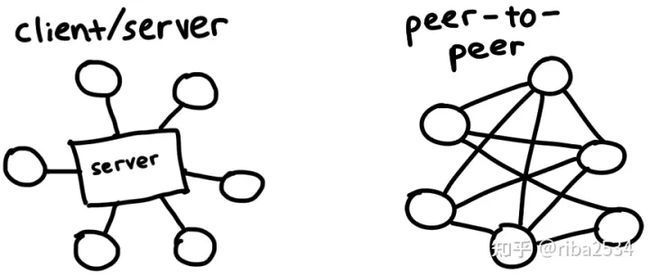
BT(BitTorrent)是 P2P 的一种实现,P2P也叫「对等网络」(英语:peer-to-peer, 简称P2P),是一种在对等者(Peer)之间分配任务和工作负载的分布式应用架构,是对等计算模型在应用层形成的一种网络形式。在P2P网络环境中,彼此连接的多台计算机之间都处于对等的地位,各台计算机有相同的功能,无主从之分,每个节点既充当服务器,为其他节点提供服务,也能作为客户端,享用其他节点提供的服务。
P2P有着很广泛的应用,比如 P2P金融(雾),区块链,BT下载等。它的关键字是去中心化,依靠用户群(peers)来互相传输数据,符合这种特征的都可以称之为 P2P。
BitTorrent
大家肯定有在互联网上下载各种资源的经历,比如电影电视剧,我们在网上一搜,就会搜到一些不知名的小网站,网站上通常会提供一个叫做「种子」的东西,我们使用时只需要把种子下载到电脑上,通常是一个后缀为 .torrent 的文件, 然后用迅雷或者其他的下载工具下载。
在实际操作中,如果我们使用迅雷进行下载,有时候会发现种子下不动,有时候发现下的特别慢,有时候还被提示资源敏感,无法下载,还有时候迅雷提示你开会员可以加速(这个时候开一个会员基本就可以满速下载了,因为迅雷已经把资源提前下载到自己服务器了),我们可能产生一些疑惑:
种子是什么?
为什么资源有时候下不动,有时候速度那么慢?
如何才能让我的BT下载速度变快?
为了解决这个疑问,我们需要了解一下 BT 协议,全称是 BitTorrent,这个协议被设计用来实现 P2P(Peer to Peer) 下载。普通的 HTTP/FTP 下载使用 TCP/IP 协议,BitTorrent 协议是架构于 TCP/IP 协议之上的一个P2P文件传输通信协议,是一个应用层协议。
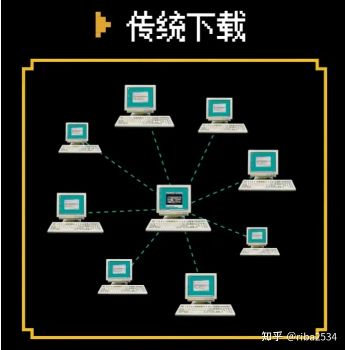
传统的下载是客户端请求服务器获取资源,下载方和资源提供方的角色很清楚。这样做的优点是简单,易于理解,我要下载东西,我就去请求服务器,缺点也很明显:
一旦服务器故障,大家都无法下载
服务器带宽有限,下载的人多速度必然下降
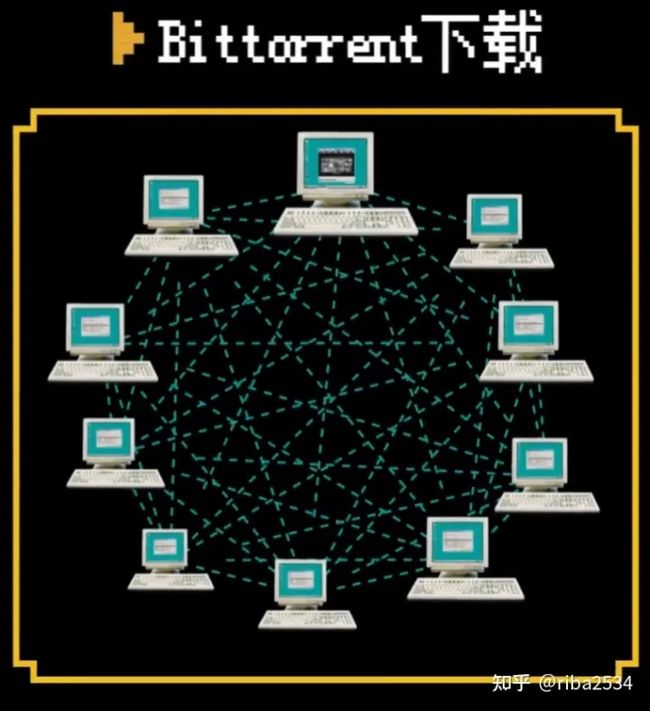
而 P2P 则不一样,每一个客户端同时也是服务器,从别人那里下载资源的同时,也提供资源给到别人。这样一来,就规避了服务器模型的缺点:
每个人都是服务器,除非所有机器都故障了,否则网络依旧可以运转
不会去请求单一机器,而是从多个机器获取资源,这样可以使带宽得到最大利用
种子的格式与作用
我们对 BT 的认知,一般是从种子开始的,所以首先需要了解一下种子的格式与作用。
我们一般下载下来的文件是一个以 .torrent 结尾的文件,通过文本编辑器打开,会看见一堆乱码,它并不是一个纯文本文件,而是一个二进制文件,通过查资料,可以发现种子文件中采用了一种文件编码,叫做 Bencode ,这种编码以 ACSII 字符来进行编码,里面包含几种简单的数据结构,我们一起来了解一下:
Bencode 编码
字符串
将一个字符串的前面加上长度标识和符号(冒号),这就是 Bencode 编码后的字符串了,比如:
'hello' -> 5:hello
'How are you' -> 11:How are you整数
一个整数起始以 i 作为标识,结尾以 e 来作为标识,把数字写在中间即可,如:
123 -> i123e
666 -> i666e
0 -> i0e列表
列表可以类比为 Python 中的列表,是一种容器性质的数据结构,每个元素可以是四种数据结构中的任意一组,没有长度限制。语法是,列表的开头和结尾分别用 l 和 e 作为标识符,中间的值就是任意的数据结构。
[123,666,0] -> li123ei666ei0ee
[123,'hello',456] -> li123e5:helloi456ee字典
字典的开头和结尾以 d 和 e 作为标识符,bencode中的字典,key 要求必须是字符串格式的,value 的格式可以随便。另外,编码过程,key 要根据字符串的字典序进行升序排序。比如:
{'a':1,'cd':[3,4],'b':2} -> d1:ai1e1:bi2e2:cdli3ei4eee.torrent 种子的格式
关于种子文件的定义,在官方文档:bep_0003.rst_post 里面说的很清楚。实质上,种子文件就是一个使用 Bencode 格式编码的一个 Dictionary,里面含有一些字段,声明了关于这个种子的一些信息。
大家可以把一个种子文件理解成为一个大 Json,只不过是因为压缩需要用二进制的形式存起来了而已。
我写了一个解析器,可以把不可读的 bencode 变成可读的 json 格式:
https://github.com/riba2534/bencode
我们以 Ubuntu20.04.2 官方提供的种子为例:https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/20.04.2.0/ubuntu-20.04.2.0-desktop-amd64.iso.torrent
把这个种子解析之后,会得到一个json文件,如下:
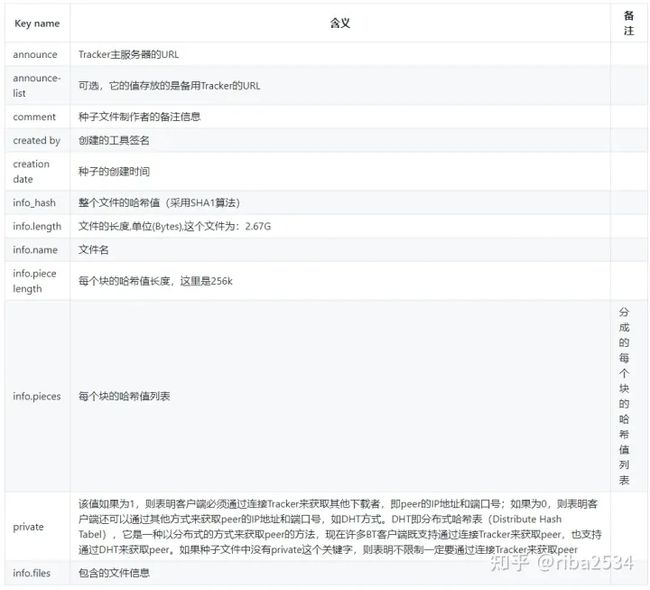
{"announce":"https://torrent.ubuntu.com/announce","announce-list":[["https://torrent.ubuntu.com/announce"],["https://ipv6.torrent.ubuntu.com/announce"]],"comment":"Ubuntu CD releases.ubuntu.com","created by":"mktorrent 1.1","creation date":"2021-02-12 03:02:32","info_hash":"4ba4fbf7231a3a660e86892707d25c135533a16a","info":{"length":2877227008,"name":"ubuntu-20.04.2.0-desktop-amd64.iso","piece length":262144,"pieces":["d89b853053ac28e09d6d322658636d9663aa80fe","287528aae8bda9ef962918ba8db2ceb0638454e4","149987b3a98147d9b5cc1e249b2fea7dc3401eb1","539f5c519a5fcb058d5978b415188340f57039df","c5ac6a46748abef691e96f7913c60c22990d5123","e87e684ca1c31cc029560514058c75c306a6b41c","c19e41f1c980b91ff735af99a2c4ab4d90946344","4707444be592ae107ddd614a3ef79fbc21e090a3","3acce815ec86a6d5bc0677874ab98dba424ddf35","d4e0d04c15514509c14fa97b1eb09f3bdbaff144","f03a8f9c698568221b4582995716b1123b7e7390","3efe825e140ab8137525f2ecaa0b32d46ec62851","数量太多,这里截断,一共10976行 ......."]}}我们可以发现,种子包含以下几个key:
BT 下载流程概述
刚才说了种子文件的格式,大家可能有疑惑,种子中这么多字段有啥用?我们先来简要了解一下BT下载的完整流程,再详细展开:
这里有一个网站,可以生动形象的展示 BT 下载的流程。 http://mg8.org/processing/bt.html
我们在这里用文字简述一下整个流程。
种子发布者制作种子,且向 Tracker 服务器表明,大家要下载这个种子就来找我。(Tracker 的地址就是种子文件中 announce 字段中的 url)
种子发布者把做好的种子分享到互联网。
下载者在互联网上获取到种子文件
下载者本地的 BT 客户端解析种子文件,拿到 Tarcker 地址,向 Tarcker 发起请求(HTTP或UDP),获取其他 Peer 的地址
Tracker接收到请求后,去自己的存储里找拥有这个种子中的文件的 peers 的 IP:port,返回给下载者,并且把当前下载者的 IP:Port 加入服务器的存储。
下载者与其他 Peer 建立连接,由于一个文件被分成了若干个文件块,所以下载者可以和多个 Peer 下载不同的块,下载完成后,校验块的哈希值,保存在本地。(这也是下载种子的人越多,下载速度越快的原因)
整个文件下载完成时,校验整个文件哈希值,不出意外,下载成功
BT客户端不要关闭,自己作为 Peer 服务 BT 网络中的其他人
BT下载核心思想:人人为我,我为人人
知道了基本下载流程之后,我们继续来了解一下细节。
与 Tracker 进行交互
Tracker 的作用
种子文件中的 announce 字段中包含了一个 url ,这个 url 也就是 tracker 服务器。首先我们来了解 Tracker 是什么,服务器的作用是作为 peers 沟通的桥梁而存在,当下载者要下载某一个资源的时候,就会去向服务器询问,服务器查询之后如果发现自己保存了这个资源的其他节点,就把这些节点的地址返回,然后客户端知道这些 IP:Port 后,就去与其他 Peer 建立连接。
Tracker 不存储任何具体资源的文件信息,只存储文件的哈希值,来帮助 Peers 来建立连接
发布者做种(Seed)
做种:指上传文件数据给其他 BT 用户的行为。
种子只有先被制作发布,才能使用,我们来探究一下种子的发布方法。我们先来实操一下,我现在有一个文件夹,叫做「学习资源」
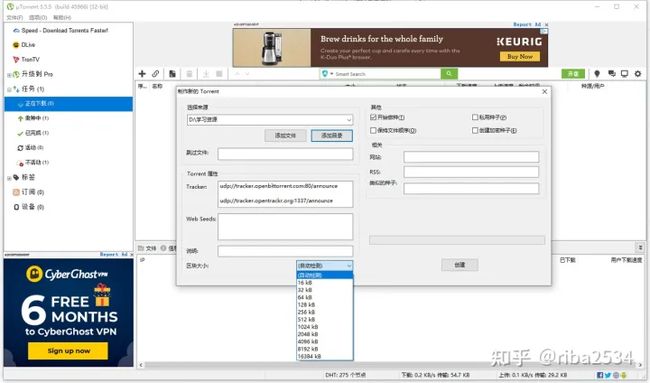
在 Utorrent 客户端中,我选择添加新的 torrent 文件,首先会让我选择一个目录,然后选一个区块大小(一般是 256KB)用于分割文件为若干个块,点击创建后,会得到一个文件,我解析字段后,如下图所示:
{"announce":"udp://tracker.openbittorrent.com:80/announce","announce-list":[["udp://tracker.openbittorrent.com:80/announce"],["udp://tracker.opentrackr.org:1337/announce"]],"created by":"uTorrent/3.5.5","creation date":"2021-03-27 16:34:08","encoding":"UTF-8","info_hash":"808eb761570975c41a7236ce8feaea5eb3c4c76b","info":{"files":[{"length":6,"path":["1.txt"]},{"length":6,"path":["2.txt"]},{"length":6,"path":["3.txt"]}],"name":"学习资源","piece length":16384,"pieces":["f118f355485f17f340330dc1bafb2f98fca7a455"]}}一般来说,使用 BT 下载软件进行做种的时候,下载软件会内置几个 tracker 服务器,当然也可以自己找一些 tarcker 的地址添加进去,BT客户端会向这些 tracker 发起请求。Tracker 服务器就会记录下来上传者的 IP:Port ,以便于传输给后续下载者进行下载。
那如果下载者要下载的时候,所有拥有这些文件的人都不在线怎么办。那就真没办法了,这种种子也叫「死种」,因为没人上传,这也就是网上很多种子下载不动的原因。
下载者下载
获取 Peers
作为一个下载者,在开始下载资源之前首先要向 tracker 宣布自己的存在,同时获得其他人的地址。 因此接下来要做的事情就是与tracker通信,获取peers。
我们仍然可以从官方文档中找到下载者与 tarcker 通信的方式 http://www.bittorrent.org/beps/bep_0003.html ,可以看出下载者与 Trakcer 的通信方式有 UDP 和 HTTP 两种协议,具体使用哪一种,看种子里面包含的信息是 udp 还是 http,下面我们以 HTTP 的方式来进行探究:
下载者向 Tracker 发起一个 GET 请求,请求的格式包含的关键字段:
Tracker 接收到 GET 请求后,Tracker服务器就会反连(NatCheck)下载者的IP地址和端口,这样就可以区分内网用户还是公网用户(如果是内网用户,它是连不通的,因为它会连到Nat服务器或者路由器上,结果就是连不通),然后服务器返回现在正在下载这个文件的所有公网用户的IP地址和端口列表,返回给BT客户端(也可能是部分客户列表),最后如果该用户是公网用户 Tracker服务器会把用户提交的IP地址和端口保存下来,这样其他人就可以找到该用户。
在返回的 Body 中,也是一个用 Bencode 编码的信息,正常响应至少要包含 interval 和 peers 两个字段。其中,interval 用于告诉客户端间隔多久再向服务端发一次请求(当然客户端有可能完全不理会),peers 字段包含同伴的 peer_id、ip、port 等信息。
BT客户端得到这些其他用户IP后,就可以直接连接到这些IP和端口下载资料了。BT客户端会到所有的用户去寻找自己要下载的东西。BT客户端每找到一个用户就建立一个 Socket来下载 ,所以下载的人越多,速度就越快。
我们可以来看一下整个下载过程,这里我参考了一个开源的 torrent 客户端的实现: https://github.com/veggiedefender/torrent-client
一个种子文件中的 info.pieces 字段包含了每个小块的哈希值,而每个块的大小都是 256KB。这样就相当于把下载任务分解了,分解成了下载若干个大小为 256KB 的小块的任务。采用并发的方式去依次请求每个块的数据,然后计算好数据的位置放进最终结果中返回,然后把内存中的数据写入硬盘。
// Download downloads the torrent. This stores the entire file in memory.
func(t*Torrent)Download()([]byte,error){log.Println("Starting download for",t.Name)// Init queues for workers to retrieve work and send results
workQueue:=make(chan*pieceWork,len(t.PieceHashes))// 任务队列,包含了若干个下载任务
results:=make(chan*pieceResult)// 结果队列,当对应的块下载完成后,就放进结果队列中
forindex,hash:=ranget.PieceHashes{length:=t.calculatePieceSize(index)// 计算每一个序号所对应的块的长度
workQueue<-&pieceWork{index,hash,length}// 把对应任务加入任务队列
}// Start workers
for_,peer:=ranget.Peers{got.startDownloadWorker(peer,workQueue,results)}// Collect results into a buffer until full
buf:=make([]byte,t.Length)donePieces:=0fordonePiecesPeer 与 Peer 之间的通信
上面只说了下载者需要向其他 peer 发起连接,没说具体原理,下面我们来探究一下 Peer 与 Peer 是如何建立连接的。
握手
开始下载一个块的信息时,由客户端向另一个 peer(要连接几个 peer ,就需要握手多少次),发起 TCP 连接请求,请求内容由以下几个字段组成:
协议标识符的长度,始终为19 byte(十六进制为0x13)
协议标识符,称为pstr,始终为BitTorrent protocol
八个保留字节,都设置为0。我们会将其中一些翻转为1,以表示我们支持某些扩展,但是我们没有,所以我们将它们保持为0。
我们之前计算出的信息哈希值,用于确定所需的文件(此处指的是整个文件的哈希值,不是某个块的哈希值)
我们用来识别自己的Peer ID

// New creates a new handshake with the standard pstr
funcNew(infoHash,peerID[20]byte)*Handshake{return&Handshake{Pstr:"BitTorrent protocol",InfoHash:infoHash,PeerID:peerID,}}// Serialize serializes the handshake to a buffer
func(h*Handshake)Serialize()[]byte{buf:=make([]byte,len(h.Pstr)+49)buf[0]=byte(len(h.Pstr))curr:=1curr+=copy(buf[curr:],h.Pstr)curr+=copy(buf[curr:],make([]byte,8))// 8 reserved bytes
curr+=copy(buf[curr:],h.InfoHash[:])curr+=copy(buf[curr:],h.PeerID[:])returnbuf}向 Peers 发送一次握手后.我们应该以相同的格式收到一次握手。我们返回的信息哈希应该与发送的信息哈希匹配. 这样我们就知道我们在谈论同一文件,响应格式为,第一个字节代表了协议的长度,接下来这个长度的字节数是协议名称,接下来20个字节为响应的哈希值和 peerID

typeHandshakestruct{PstrstringInfoHash[20]bytePeerID[20]byte}发起请求的 Peer 接受到对端 Peer 的响应后,对比其中的 Info Hash 字段的值是不是相等,如果不相等就给上层抛出错误。
此时 两个 Peer 的握手部分就完成了。
数据传输
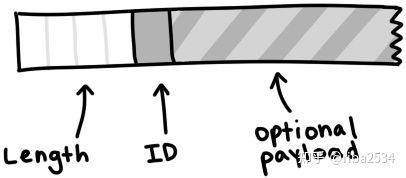
握手完成之后,此时需要进行数据传输,双方的沟通换了一种消息格式:
一条消息以长度指示符开头,该指示符告诉我们该消息将有多少字节长,它是一个32位整数, 意味着它是由 4 个 byte 按序排列的字节组成。下一个字节,即ID,告诉我们正在接收的消息类型(Message Type)。最后,可选的有效 payload 将填充消息的剩余长度.
// 沟通的消息类型的枚举值
const(MsgChokemessageID=0// 阻塞消息接收者
MsgUnchokemessageID=1// 解除阻塞消息接收者
MsgInterestedmessageID=2// 表示有兴趣接收数据
MsgNotInterestedmessageID=3// 没兴趣接收数据
MsgHavemessageID=4// 提醒消息接收者,发送者已经下载了一个块
MsgBitfieldmessageID=5// 对发送者已经下载的片段进行编码
MsgRequestmessageID=6// 向消息接收者请求一个块
MsgPiecemessageID=7// 传送满足请求的数据块
MsgCancelmessageID=8// 取消一个请求
)然后双方会利用上述的这种消息格式进行沟通,用以完成数据传输。一个完整的数据传输过程为:
数据提供者对下载者发送 Bitfield 消息,告诉自己有这个文件的哪些块(数据提供者并不一定有完整的文件,所以需要告诉客户端,自己有这个文件的哪些块,这个信息通过 Bitfield 来传递,Bitfield 可以理解成一个二进制 bit 数组,数组值为1 ,就代表有这个块,0代表没有)
下载者发送 Unchoke 消息,代表自己准备好了,可以进行消息传输了。(握手完成后的刚开始,我们被其他 Peer 认为状态是阻塞的(chocked),我们需要发送一条解锁消息,让他们知道我们可以开始接收数据了)
下载者发送 Interested 消息,代表自己要开始下载文件了
下载者发送 Request 消息,其中 Payload 包含具体的某个块的信息,包括:块的序号(index),开始位置(begin)和长度(length)。
数据提供者向下载者发送 Piece 消息,其中 Payload 里面包含真正的块数据,以及块的序号,开始位置和长度,以便于下载者保存数据

不断重复这个过程,直到所有的数据块都被下载完为止。
校验哈希值
当下载者收到数据提供者发送过来的二进制数据后,会计算一下这个二进制数据的哈希值,然后和自己的 torrent 文件中的对应块的哈希值进行比较,如果哈希值一样,就代表这块块有效,就保存下来,否则视为无效,会丢弃这个块重新下载。
这种下载方式一定安全吗?
一种被称为虚假数据块攻击的 P2P污染方法。与传统的P2P污染攻击方法不同,该方法避开“元信息”的发布环节,直接对数据传输过程进行污染,通过浪费下载者的网络带宽来延长下载者的下载时间。攻击者伪装成一个普通节点加入被攻击的文件传播任务对应的BitTorrent网络,将其节点信息注册到tracker服务器上并声称自己拥有全部或大部分被共享文件的数据块。当下载者从tracker服务器中获得了攻击者的节点信息,便与攻击者建立连接并向其请求若干个需要的数据块,但攻击者向其返回无效的数据块。下载者在收到若干个数据块后,将这些数据块组装成一个数据片断并对该数据片断进行哈希校验以保证数据传输的正确性。只要组成数据片断的数据块中有一块是从攻击者处获得的无效数据块,哈希校验就无法通过,下载者会丢弃该数据片断并重新下载该片断对应的所有数据块。因此,攻击者只需要发送一个数据块就可以使下载者下载的整个数据片断作废,从而实现浪费下载者的网络带宽,延长其下载时间的目的。但近年来,越来越多的BitTorrent下载客户端引入了黑名单机制以防范虚假数据块攻击,使数据块攻击的攻击者在发送一定的虚假数据后便被加入黑名单,无法对文件传播进行控制。
见:https://patents.google.com/patent/CN101753572B/zh
当 BT 下载遇到 NAT
在实际中的网络,目前由于 IPV4 地址不够用,部分运营商一般给用户分配一个 NAT 网络,那么网络结构可能会变成这样。当P2P遇到NAT就比较头疼了,因为NAT进行了IP转换,你告诉邻居节点的IP:PORT是公网的,当他来连接时发现进不来,因为NAT没有做映射。
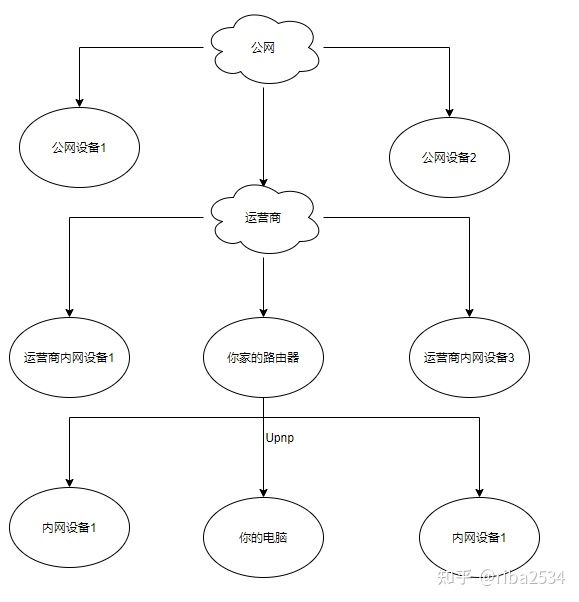
遗憾的是,如果是这种情况,确实会无法上传。我们都知道,一个公网 IP 无法主动向一个内网地址发起连接。那么有没有其他方式去解决这个情况呢。其实是有曲线救国的方法的。流程如下:
内网用户开始做Seed
服务器收到请求,由于是第一个所以也没有Peer(对端,只一个TCP连接的一方)返回
公网用户提交请求,由于Seed是内网用户所以也没有Peer返回,等待下载,但服务器会把它的IP放到列表中
内网经过设定的时间间隔后,再向服务器放出请求,得到上面得公网IP
得到公网IP后,内网马上进行连接
公网用户建立连接,数据开始传输 (实际上现在是公网用户做服务器,内网用户做客户端)
其它内网用户去上面公网用户下载数据
经过这个流程,内网用户主动向公网发起连接,把数据成功地传给公网用户。
但是,这仍是一种曲线救国的方法,实际操作中,我们可以主动要求运营商给家庭宽带分配公网IP,打客服电话很快就可以办妥。但是家庭网络中一般用的都是路由器,那实际PC设备还是在内网,这一步有办法解决吗?实质上是有办法的,即开启路由器中的 Upnp 设置。
UPNP的英文全称是 Universal Plug and Play ,即通用即插即用协议,简单来说它的作用是应用程序可以自动和路由器之间协商端口来进行端口映射。由于这一切都是自动的,用户感知不到这个过程,
PT(Private Tracker)
我之前一直不知道PT是啥意思,为了研究PT,我购买了一个 PT 站,(http://xxx.net/)的会员资格。然后进网站下载了一个电影种子,下面以里面的一个电影种子为例,我们来研究一下 PT 种子的文件格式
出于保护站点需要,以下我们均以「XXX」代替本站点
{"announce":"https://www.xxx.net/announce.php?passkey=xxxxxxxxxxxx","created by":"Transmission/3.00 (bb6b5a062e)","creation date":"2021-03-23 23:56:16","encoding":"UTF-8","info_hash":"62a3938e4ed8a917e1be86c2ed3047207a0c72eb","info":{"files":[{"length":23406804689,"path":["National.Treasure.Book.of.Secrets.2007.Bluray.1080p.AVC.Remux.TrueHD.5.1-PTH.mkv"]}],"name":"National.Treasure.Book.of.Secrets.2007.Bluray.1080p.AVC.Remux.TrueHD.5.1-PTH","piece length":2097152,"pieces":["0b756bb6b4353484d58dee40616dc2c70c10fbeb","f7fa7f6a7eb82bfccf1650f426527c235dc3acbc","cdd40e1eda7ec33d223785c256a55da7cf94acaa","62bc80029ae21704cb437cfbc58c1fb353324404","f456d5931ba116549d8c31c779e12f68a0ccc51c","8878830cd11be1f2b63eb78d661259be951be50e","077ad7881c4fb3628c1f11c7c5fa8b608ecb832a","6d14a2cdddda2f8289eb1d3bbf81b61bfa328763","60d0c976e0e80ddb04abd4d44982130e13e9a838","太长了省略,这里一共 11162 行"],"private":1,"source":"[xxx.net] xxx"}}可以看出来,相比于 BT,PT种子的 announce 字段中增加了一个叫做 passkey 的东西。还增加了一个字段,private 为 1。
那 passkey 这个字段有什么用呢,我们打开 PT 站,登陆自己的账号,会发现网站上面会显示一个值叫做「分享率」,分享率的计算是 【上传量➗下载量=分享率】,那么网站是如何记录你的上传量和下载量呢,就是通过种子中的 passkey 字段来标识。
那么,网站为什么要有「分享率」这个概念呢?
我们可以回想一下一下 BT 的特点,在普通 BT 的世界里面,每个人都是靠自觉来分享种子&上传文件,但是人都是自私的,大部分的人属于那种下载了就跑的类型,还有些人会刻意的限制上传速度,这样的话,上传者们在默默付出得不到一点回报,长此以往,下载生态就无法构建起来,PT 就是为了解决大家都相当白嫖怪的心理,通过规则来构建良好的分享氛围。
俗话说的好,技术不能解决的事情就要靠规则来限制
PT站首先是一个私密的社区,通常是一个小圈子,里面有着大家共同默认的规则,即「想下载就必须先分享」,以 XXX 社区为例,规定如果一个人的分享率小于 0.2 ,则无法继续下载,还可能会导致封号,一个人要想去下载资源,就必须先做种,分享自己的带宽,由网站来记录用户的上传流量,当分享率为正的时候才能去下载资源。
这样就形成了一个良性循环,上传者为了下载会分享自己的带宽,而下载者也会因为上传者的上传,下载速度会大大提高。
这才是 P2P 的精髓,「人人为我,我为人人」
题外话:PT协议一定安全吗?
PT服务器与BT客户端之间的通信协议很简单。一开始BT客户端会向PT服务器发出请求,告知种子的状态(完成还是需要下载)。PT服务器返回一个间隔时间和peer列表。此后,BT客户端按照PT服务器给定的间隔时间定时向服务器报告上传了多少,下载了多少,还剩下多少(任务结束时也会报告同样的信息)。这个过程中的问题在于,上传量数据完全是由客户端提供的,而针对如此庞大的P2P网络,PT服务器完全无法验证上传量的真实性。所以,只要伪造了这个通信的过程,上传量就可以随意设定了。
从理论上讲,这种伪装做种/欺骗上传量的方法是无法从根本上防范的,因为PT服务器没有掌握足够信息。
事实上,目前已经有了破解工具(http://demon.tw/software/ptliar.html,https://wenku.baidu.com/view/19bcafe06f1aff00bed51eec.html)在网上流传,所以根本上,PT还是需要靠人自觉。
BT的延伸 - DHT网络
根据上面的介绍,我们来思考一个问题,BT下载严重依赖于 Tracker 服务器,那是不是意味着 Tracker 崩了整个 BT 网络就崩了,当然 Tracker 可能不止有一个,多个 Tracker 服务器可以增加 P2P 网络的容错性,那有有没有一种比较优雅的解决方案,来更好的解决这个问题呢?
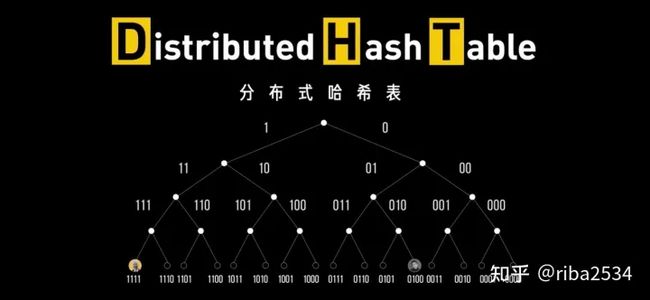
为了摆脱对 Tracker 服务器的依赖,彻底去中心化,这时候,DHT 出现了,DHT全称分布式哈希表(Distributed Hash Table),是一种分布式存储方法。在不需要服务器的情况下,每个节点负责一个小范围的路由,并负责存储一小部分数据,从而实现整个DHT网络的寻址和存储,相当于所有人一起构成了一个庞大的分布式存储数据库。
在 DHT 网络中每个节点拥有两个角色:
作为 BT 下载的节点,来进行上传和下载资源。
作为DHT网络中的一员,作为一个小型 Tracker ,保存一部分其他 Peer 的地址信息。
DHT 的本质是把所有人都变成一个小型 Tracker,每个人都拿着一份动态更新的地址和文件信息。当需要进行下载的时候,先根据自己本地存的路由表找其他节点,其他节点再去找他们保存的其他节点,直到找到拥有文件的人。一传十十传百、千、万,最后通过N个人的中转,找到应该连上的人。
磁力链接
事实上,目前最流行的下载方式是磁力链接(Magnet URI scheme)就是基于 DHT 网络的,通常是一串这样的神秘代码:
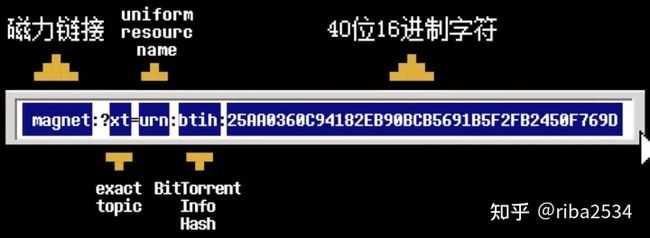
其中urn为统一资源名称,btih 是BitTorrent Info Hash的缩写,是 BitTorrent 使用的Hash函数。除了 btih 还可以是其他类型的Hash函数,但不如 btih 用的多。这一串长度为40的字符串正是文件内容的Hash,BT下载工具就根据这个Hash在DHT网络中定位下载文件。
那仅凭一个哈希值,peer 之间是如何互相找到的?
这个时候我们就需要了解一下DHT是具体怎么构建的。
KRPC 协议
刚才我们说到 DHT 中文名叫「分布式哈希表」,那么看名字就知道,这是一个哈希表,只不过是分布式的而已,对于哈希表我们肯定都很熟悉了,这不就是 Key,Value吗?那在 BT 下载中的 key 和 value 是什么呢,毫无疑问,Key 就是上文中说到的磁力链接中最重要的部分 InfoHash,占 160bit,value 自然就是 peers 的 IP:port 的列表了。那既然是一个哈希表,就要支持 Set(key,value) 和 Get(key) 操作,那磁力链接下载的本质就是给你一个key,你去分布式哈希表中找到 value ,然后去下载。
BitTorrent 官方采用的 DHT 协议名字叫做「Kademlia」协议,我们来简单了解一下它的思想:DHT 由很多节点组成,每个节点有自己的ID,每个节点保存一张表,表里边记录着自己的好友节点。当你向一个节点 A 查询另外一个节点 B 的信息的时候,A 就会查询自己的好友表,如果里边包含 B,那么 A 就返回 B 的信息,否则 A 就返回距离 B 距离最近的 k (一般k=8)个节点。然后你再向这 k 个节点再次查询 B 的信息,这样循环一直到查询到 B 的信息,查询到B 的信息后你应该向之前所有查询过的节点发个通知,告诉他们,你有B的信息。
那么在这个过程中,A 怎么知道 距离 B 最近的 K 个节点呢?难道是记录了地理位置?当然不是,此处说的距离与现实世界中的距离没有一点关系,此处的距离是一种逻辑上的距离,可以通过计算(XOR)来得到。
关于路由表和 Kademlia 的详细介绍,这里不再展开(挺复杂的),可以参照官方文档。
我们这里的重点在于了解如何根据磁力链接获取拥有该磁力链接对应的种子文件信息的Peers,所以只需要了解分布式哈希表的功能,以及如何使用这个哈希表,使用哈希表的办法是采用 KRPC协议。 KRPC协议是由 Bencode 组成的一个简单的RPC结构,有4种请求:ping、find_node、get_peers 和 announce_peer。
ping: 检测节点是否可达,请求包含一个参数id,代表该节点的nodeID。对应的回复也应该包含回复者的nodeID。用来侦探另一个节点是否在线。
find_node: 该请求包含两个参数id和target,id为该节点的nodeID,target为要查询的nodeID。回复中应该包含被请求节点的路由表中距离target最接近的8个nodeID。
get_peers: 该请求包含两个参数id和infohash,id为该节点的nodeID,infohash为种子文件的SHA1哈希值,也就是磁力链接的btih值。如果被请求的节点有对应info_hash的peers,他将返回一个关键字values,这是一个列表类型的字符串。每一个字符串包含了CompactIP-address/portinfo格式的peers信息。如果被请求的节点没有这个infohash的peers,那么他将返回关键字nodes,这个关键字包含了被请求节点的路由表中离info_hash最近的K个nodes,使用Compactnodeinfo格式回复。
announce_peer: 用来告诉别人自己可提供某一个资源的下载,让别人把这个消息保存起来。这样就可以分享给其他人,让其他人连接你进行下载。
整体看 DHT 这个哈希表,find_node 和 get_peers 就是我们之前说的 Get(key),announce_peer就是 Set(key,value)。那这样我们就可以只拥有一个哈希值,就可以在 DHT 网络中找到要下载的信息了。
题外话:
现在网上有很多在线工具,支持把种子文件和磁力链接互转,实际上原理很简单,把种子文件转换成磁力链就是提取文件的 hash 信息,然后用拼接了一下。把磁力链转换成种子文件就是先去 DHT 网络中查数据的元信息,查到之后按照 Bencode 编码格式进行编码。
新节点如何加入DHT网络(冷启动)
当一个新节点首次试图加入DHT 网络时,它必须做三件事:
如果一个新节点要加入到DHT网络中,它必须要先认识一个人带你进去。这样的人我们把他叫做bootstrap node,常见的bootstrap node有:http://router.bittorrent.com、http://router.utorrent.com、http://router.bitcomet.com、http://dht.transmissionbt.com 等等,我们可以称之为节点A ,并将其加入自己的路由表
向该节点发起一次针对自己ID的节点查询请求,从而通过节点A获取一系列与自己距离邻近的其他节点的信息
刷新所有的路由表,保证自己所获得的节点信息全部都是新鲜的。
磁力搜索引擎的原理
现在网上有很多磁力搜索引擎,大家可能会好奇他们网站的资源是从哪里来的,一个资源不可能凭空产生,那有一个很明显的结论:如果有人想下载一个种子,那么必然有人制作了这个种子。
因此,只需要写一个爬虫程序,把它伪装成 DHT 网络中的一个节点,这样当其他客户端想下载某个 torrent 时,就会在 DHT 网络发起广播,当它询问到我的节点时,我就知道了:哦,原来有人要下载这个种子啊,那么在 DHT 网络中肯定有这个种子。于是我把这个种子的信息保存到 MySQL/ES 中。 通过检测别人对我的询问情况,我还可以知道某个种子的热度。这种爬虫也称为 DHT 网络嗅探器。
这样,知道了种子的地址,名称等信息,只需要做一个网站,就可以利用手中的数据做一个磁力链接搜索了。
相关软件推荐
https://trackerslist.com/#/zh 这是网友维护的一个开源项目,每天会维护全网热门的 Tracker列表

https://motrix.app/zh-CN/ 一个开源的支持下载 HTTP、FTP、BT、磁力链接等资源的工具。没有广告,跨平台,使用 electron 编写,支持 Windows/Linux/macOS,Github链接:Motrix
思考
国内 BT 生态的现状
IPV4地址缺少
事实上,国内目前的 BT 生态很恶劣,首先现状是我们的互联网还是大量使用的 IPv4 ,这就导致了 IP 地址很稀缺,根据维基百科「各国IPv4地址分配列表」 可以看出,美国 3 亿多的人口,拿走了 15 亿的 IPV4 地址,而中国 13 亿的人口,却只有 3 亿多的 IPV4 地址,这就势必造成了国内运营商分配到每户的 IP 地址是经过层层 NAT 的,有公网 IP 的网民并不多。
不过好在大部分网民没有公网IP需求,基本上只要有需要可以和运营商客服协商,给自己的网络分配一个 IPV4 地址。
希望尽快普及 IPV6
潜移默化的习惯
大多数网民下载资源仅仅是想快速的进行下载,并没有上传意识,有相当一部分人甚至不知道BT下载还需要上传,知道会上传的网民很多会认为这会占用自己的上行带宽,主动限制网速。由于习惯带来的问题是很难改变的。
时代的变迁
国家的各种政策,以及中国网民付费意识越来越强,越来越容易接受正版化,可以很方便的从各大视频网站中满足自己的需求。网民们大部分使用的并不是 PC ,而是手机,消费内容的方式更多的也变成了手机 APP,而手机本身,就不是很适合来运行这种 BT 软件。
迅雷
迅雷的工作原理是,先看自己服务器有没有相关资源,如果有的话会主动进行限速,引导用户开通会员去进行下载。对于服务器中没有缓存的资源,进行 BT 下载,迅雷可以获取其他 BT 软件的用户,但其他 BT 软件无法获取迅雷的用户,用户数量上存在差距,也就导致了迅雷的下载速度越来越快,迫使其他用户转而使用迅雷,使得国内很多资源只有 迅雷 才有下载速度,而其他 BT 软件速度越来越不如迅雷,劣币驱逐良币,最终形成恶性循环。导致整体性的国内 BT 速度下降。
迅雷的种子只会给使用迅雷的人进行上传,这和 P2P 的理念是相悖的。
网盘时代
自从进入了网盘时代,很多分享的链接都是百度网盘的链接,这确实可以避免死种这种没速度的问题,但是却让使用 BT 的人越来越少,造成整体下载速度下降。
BT 的未来
目前 BT 的使用更多的是在一种灰色地带,大多数的影像/音乐等资源都是存在版权风险,而人们正版化意识越来越强,现在获取电影等资源已经很好的得到了满足,比如长视频爱优腾,视频网站都有大厂支持,看电影有大量的 CDN 可以进行资源分发,不用担心传输速度慢的问题。
BT/PT 用户应该还是持续的在小圈子里面存在下去,有很多发烧友喜欢电影的原盘,动则几十上百G,这种需求是爱优腾无法支持的,
像BitTorrent这样的P2P技术是对下载方式的一次革命,个人用户分享一个资源从未变得如此方便,这些天才们的设计,让我们拥有了一个无法被审查和追踪的去中心化网络。这催生了庞大的盗版产业,但也让很多内容有机会避开审查。
因为网站可以被隔离、被拔线、被禁止访问,但种子不会。只要种子不死,那些不存在的音乐图书和视频就还活在互联网上,没有任何人可以毁掉。
我个人认为,BT 在以后相当长的一段时间内不会消失,但是使用量也不会增多,会逐渐变成小圈子的分享。
不可否认的是,P2P技术改变了互联网对资源分享的方式。