苏宁基于 AI 和图技术的智能监控体系的建设
汤泳,苏宁科技集团智能监控与运维产研中心总监,中国商业联合会智库顾问,致力于海量数据分析、基于深度学习的时间序列分析与预测、自然语言处理和图神经网络的研究。在应用实践中,通过基于 AI 的方式不断完善智能监控体系的建设,对日常和大促提供稳定性保障。
概述
知识图谱有较强的知识表达能力、直观的信息呈现能力和较好的推理可解释性,因此知识图谱在推荐系统、问答系统、搜索引擎、医疗健康、生物制药等领域有着广泛的应用。运维知识图谱构建相对于其他领域的知识图谱构建而言,具有天然的优势,网络设备固有的拓扑结构、系统应用的调用关系可以快速的构成软硬件知识图谱中的实体和关系。历史的告警数据蕴含着大量的相关、因果关系,使用因果发现算法,也可以有效的构建告警知识图谱。基于知识图谱上的权重进行路径搜索,可以给出根因的传播路径,便于运维人员快速的做出干预决策。
苏宁通过 CMDB、调用链等数据构建软硬件知识图谱,在此基础上通过历史告警数据构建告警知识图谱,并最终应用知识图谱进行告警收敛和根因定位。本文主要包括运维知识图谱构建、知识图谱存储、告警收敛及根因定位等内容。
痛点及产品对策演进
痛点
- 苏宁内部系统和服务的复杂性:
6000+ 系统,数量还在增加;
系统间调用方式复杂: 大部分使用 RSF,也有 HTTP、HESSIAN 等;
苏宁业务的复杂: 既有线上新业务又有线下老业务,这些业务系统之间会有大量的关联。
- 基础环境的复杂性:
多数据中心,每个数据中心会划分多个逻辑机房和部署环境;
服务器规模 30w+,例如,缓存服务器就有可能有上千台服务器;
设备复杂性: 多品牌的交换机,路由器,负载均衡,OpenStack, KVM, k8s 下 docker,swarm 下的 docker 等。
基础设施的复杂性导致每天平均产生 10w+ 的告警事件,峰值可达到 20w+ / 天。面对海量的运维监控数据,系统和指标间关联关系越来越复杂,一个节点出现故障,极易引发告警风暴,波及更广的范围,导致定位问题费时费力。此时,单纯依靠人肉和经验分析,越来越难以为继。迫切需要一个工具,可以辅助我们分析系统和指标间关联关系,可视化展示告警的传播路径和影响范围等。
产品对策演进
针对上述痛点,我们采用领域知识结合 AI 的方法对告警进行收敛,以缓解告 警风暴。此外,为便于一线运维人员快速的作出干预决策,我们同时对告警的传播路径和影响范围进行分析。
- 基于交叉熵的告警聚类(1.0 版本)
按照告警的场景和规则,利用交叉熵对告警信息进行聚类,实现告警的收敛。 借鉴 moogsoft 的思想,将告警聚类结果生成 situation,同一个 situation 中包含同场景、有关联的告警。
缺点:
-
收敛效果有限,该方法只能减少 30% 左右的告警,无法有效解决告警风暴问题;
-
无法提供根告警以及根因链路
-
弱解释性
-
无法解决告警的根因问题。
- 基于 GRANO 算法的根因定位(2.0 版本)
根因定位是在告警收敛的基础上进行的,采用 GRANO[2] 算法,基于告警收敛结果生成 situation,计算 situation 中每个告警节点的得分,然后排序来确定根因。
缺点:
- 这种方法的缺点是不会给出一条完整的根因链路,因此根因的可解释性不强。
- 基于运维知识图谱的告警收敛和根因定位(3.0 版本)
包括全局视角下的软硬件知识图谱和告警知识图谱,利用 NLP 技术对告警文 本信息进行分类,然后将告警收敛到软硬件知识图谱的相关节点上,再结合具 有因果关系的告警知识图谱,得出一条 “A –> B –> C –> D”的根因链路。
优点:
- 由于结合了领域相关知识,该方法收敛效果更好,而且提供了一条完整的根因链路,所以解释性更强,可以更好的为 SRE / 运维人员提供指引。
思路与架构
分层建设思路
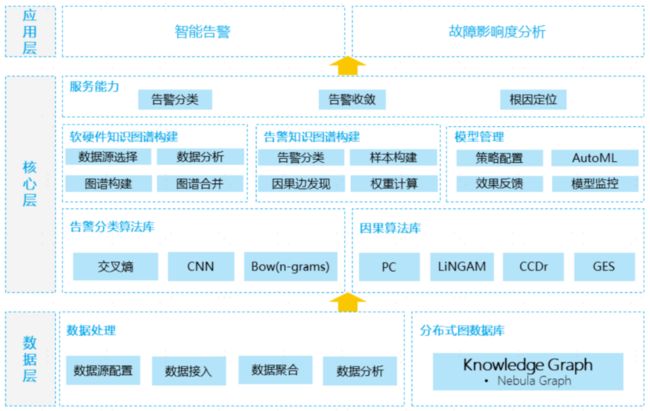
流程架构
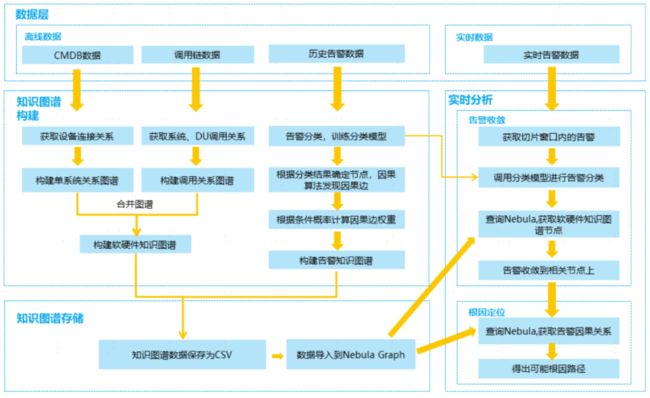
运维知识图谱构建
4.1 软硬件知识图谱构建
软硬件知识图谱是以全局的视角展示系统内各应用、软件、虚拟机、物理机间 的内在逻辑,系统间的调用关系,网络设备的物理连接关系。图谱中的节点包 括系统、DU(部署单元)、group(主机实例组)、软件、虚拟机、物理机、接入交 换机、核心交换机、汇聚交换机、路由器等。关系包括 constitute(构成)、call (调用)、logical(逻辑连接)、cluster(汇聚)、ship(承载)、host(宿主)、connect(物 理连接)等。软硬件知识图谱的原型如下:
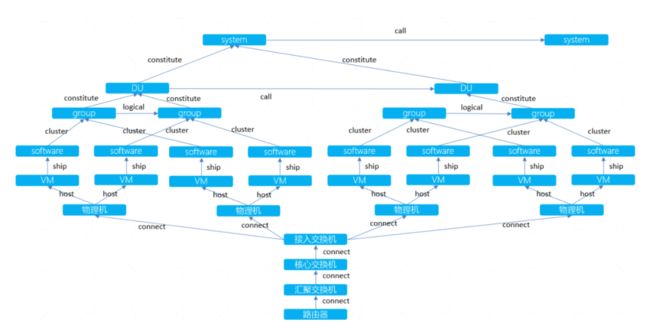
软硬件知识图谱构建的数据源主要有 CMDB 数据、调用链数据和物理设备网络连接数据。实践中首先基于离线数据初始化软硬件知识图谱,随着业务的变化和拓展会出现旧系统的下线和新系统的上线,然后根据变化定时或定期更新软硬件知识图谱。
4.1.1 CMDB 数据构建流程

通过 CMDB 数据可以构建 HOST->VM->SOFTWARE->GROUP 及 GROUP (WildFly) -> GROUP(Nginx)的关系图谱。
4.1.2 调用链 / 物理设备网络连接数据
调用链数据主要用于获取 DU 间调用关系、系统间调用关系、DU / IP 映射关系、中间件间的逻辑连接关系等,数据主要通过内部的一些 API 接口获取。
物理设备主要包括物理机、交换机、路由器等,数据主要通过运维平台获取。
4.1.3 合并图谱
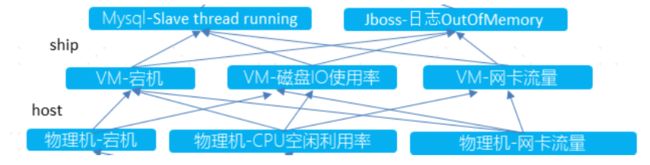
将前面得到的 CMDB、调用链和物理设备图谱通过 networkx 合并,然后存入图数据库 NebulaGraph 中,最终得到的单系统和系统间图谱分别如下(NebulaGraph Studio 可视化呈现):
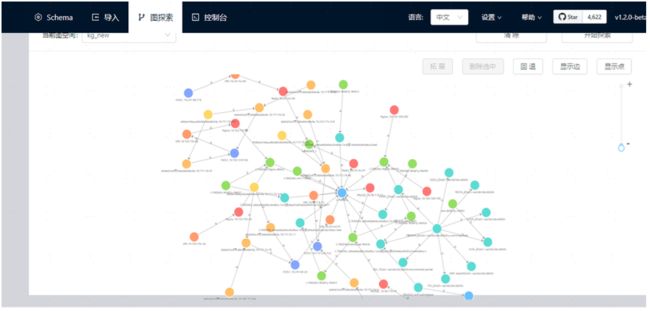
其中蓝色节点为系统,浅蓝色节点为 DU,绿色节点为 group,红色节点为软件,橙色节点为虚拟机,深蓝色节点为物理机,黄色节点为接入交换机,淡黄色节点为汇聚交换机。
NebulaGraph Studio: https://github.com/vesoft-inc/nebula-web-docker
4.2 告警知识图谱构建
4.2.1 告警数据分类
原来的告警分类采用是交叉熵方法: 告警信息、分词、统计词频、计算与各类别的相似度(交叉熵),若相似度大于阈值,选择相似度最高的那一类归到该类,若相似度均小于阈值,则新增一个类别。
这样做的缺点:
-
无法控制分类的数量,比如如果阈值设的较大,就会出现好多类别;如果设置的较小,很多告警又会归到一类。
-
无法控制类别的具体含义,分类依赖于交叉熵的计算结果以及阈值的设置,无法确切知道每个类别的真正含义。
上述这种方法无法满足我们构建因果图的需要。
为了让构建的因果图有更好的说服力和可解释性,我们需要对各种告警信息进行人工分类,比如有的告警是对应于基础设施,比如网卡流量,cpu 利用率,
有的告警对应于具体软件,比如 mysql 延迟,wildfly 无法获取连接。这样,每个告警类别都有自己明确的含义。在此基础上构建的因果图才是有意义的。
我们首先对 zabbix 六个月全量告警信息进行了整理,将所有告警分为了 183 类,然后使用有监督的方法,训练分类模型。这样新来的告警信息也可以按照 我们预先设定的类别进行分类。
分类模型我们使用的是自然语言处理方法,先对告警信息进行分词,然后计算词向量,然后将词向量作为输入训练模型。我们分别训练的 cnn 和 bow(ngr ams)分类模型,整体而言,分类准确率都很高,能满足我们的要求。其中 cnn 效果好一点,但是预测时间也会比 bow 耗时长一点。
• cnn 模型(modelcnn20e__0813):
- -------------- train_list
predict total time= 12.386132
总告警数量: 20620 错误个数: 0 准确率= 1.0
- -------------- test_list
predict total time= 1.452978
总告警数量: 3620 错误个数: 0 准确率= 1.0
- -------------- 全部六个月告警信息
总告警数量: 733637 预测错误数量: 9 准确率: 0.99998
• n bow 模型(model__bow__20e__0813)
- -------------- train_list
predict total time= 1.687823
总告警数量: 20620 错误个数: 1 准确率= 0.999952
- -------------- test_list
predict total time= 0.272725
总告警数量: 3620 错误个数: 1 准确率= 0.999724
- -------------- 全部六个月告警信息
总告警数量: 733637 预测错误数量: 12 准确率: 0.99998
4.2.2 因果节点选取
因果节点不具体指一个物理机或虚拟机 IP 上的告警,而是对所有告警类型的一个抽象总结,目前包含三层(结构如下): 物理机层面的告警、虚拟机层面 的告警、软件层面的告警。比如: 任何一台物理机上的宕机告警都归类于因果图上【物理机-宕机】节点。
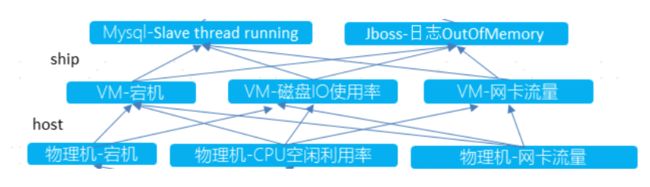
经过告警数据分类,我们初步将所有的告警分类都作为因果节点,在经过因果算法输出因果边并人工筛查确认之后,选取最终的因果节点。
4.2.3 构建因果发现样本

基于 6 个月的 zabbix 告警数据(如上图,共 781288 条告警)构建样本。
构建目标:
根据告警分类,已将每一条告警记录归类为一种告警类型(告警类型:物理机- xx 告警、虚拟机-xx 告警、软件-xx 告警)。以每条虚拟机告警记录为中心,给定一个告警时间切片(1min、2min 等),寻找每条虚拟机告警时间切片内的相关告警记录(相关告警包括: 该虚拟机隶属的物理机上的告警,同隶属该台物理机上的其他虚拟机上的告警)集合作为一个因果发现样本。
举例说明:
下面是一台虚拟机在某一个时间点的告警,以该告警构建样本。

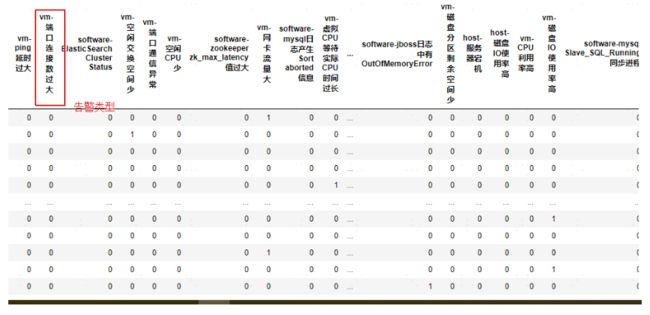
给定时间切片为 1 分钟,以上面一条虚拟机上的告警为例,寻找 1 分钟内与该虚拟机相关的物理机和虚拟机上的告警,所有告警如下图所示为一个因果样本。

最终转置每一个样本,将告警类型作为列名,集合所有的样本,若发生告警记为 1,不发生记为 0,生成最终的因果发现样本(因果算法的输入),如下所示:
4.2.4 因果算法
采用已有的因果发现算法工具包:CausalDiscoveryToolbox,其中包含的算法有: PC、GES、CCDr、LiNGAM 等。
PC:是因果发现中最著名的基于分数的方法,该算法对变量和变量集的进行 条件测试,以获得可能的因果边。
GES:Greedy Equivalence Search algorithm(贪婪干涉等价搜索算法),是一种 基于分数的贝叶斯算法,通过在数据上计算似然分数最小化来启发式地搜索 图,以获得因果边。
CCDr: Concave penalized Coordinate Descent with reparametrization(参数化的凹点惩罚坐标下降法), 这是一种基于分数的用来学习贝叶斯网络的快速结构学习算法,该方法使用稀疏正则化和块循环坐标下降。
目标:
采用多种因果发现算法训练告警数据,基于各个算法输出的因果边再结合人工审查筛选确定最终的因果边(包含因果节点),边确定了,相应的因果节点也确定了。
举例说明:
以 PC 和 GES 两个算法为例:
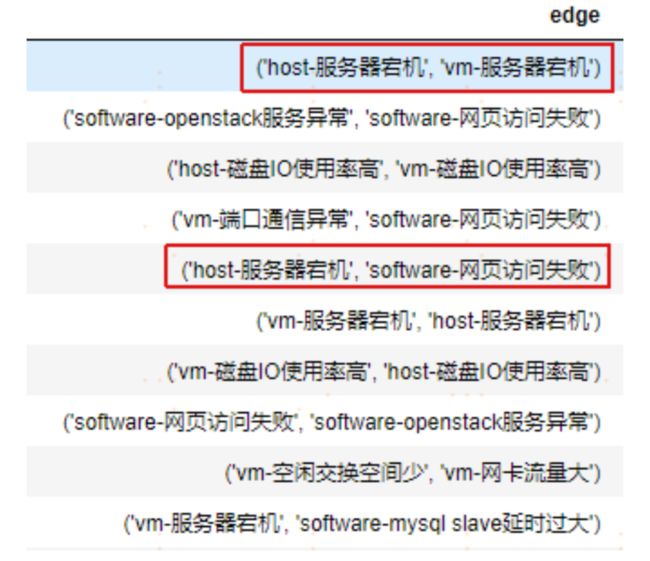
PC 算法输出的可能因果节点和边:
GES 算法输出的可能因果节点和边:

两个算法都发现了【host-服务器宕机】导致【vm-服务器宕机】和【host-服务 器宕机】导致【software-网页访问失败】等相同的因果边,经人工确认物理机宕机确实会导致其对应的虚拟机宕机和服务器上的软件访问失败,所以确定这两条边为因果边。
4.2.5 因果边的权重计算
因果边的权重采用条件概率计算,即:基于因果发现样本数据和因果发现算法给出的因果边(包括两个因果节点),【因节点发生告警的条件下果节点发生告警的次数】与【因节点总共发生的告警次数】的比值作为该因果边的权重。
举例:
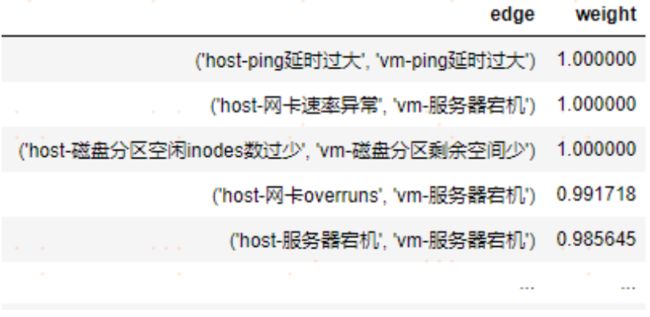
截取部分的因果边及其权重:【host-服务器宕机】导致【vm-服务器宕机】的因果边权重为 0.99。
4.2.6 构建告警知识图谱
经过【告警的分类】–>【构建因果发现样本】–>【因果算法发现因果边】–> 【因果边权重计算】,最终生成所有的因果边及其权重。
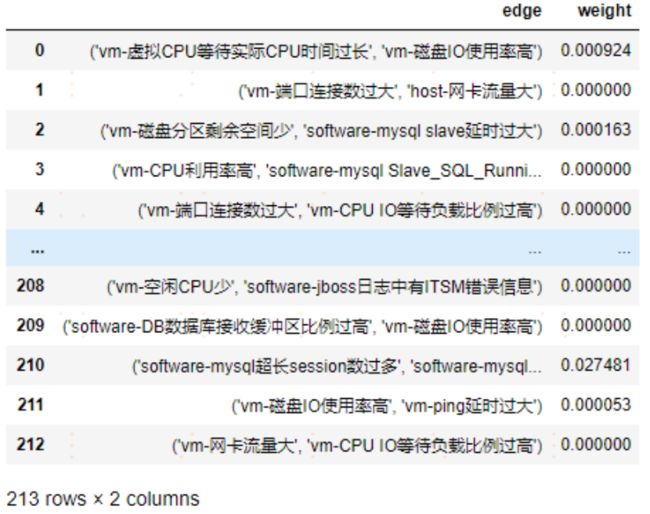
基于 zabbix 的 781288 条告警数据,最终确定了 213 条因果边(如上图所 示),根据 213 条因果边的指向和权重,构建告警知识图谱(部分结构如下图所示),并将告警知识图谱写入图数据库以便持久化读取,后续的根因定位需从图数据库读取所构建的告警知识图谱进行分析。
知识图谱存储
5.1 图数据库引入
图数据库是以图数据结构存储和查询数据,图包含节点和边。构建运维知识图谱做根因告警分析等场景时,为了实时查询知识图谱,我们引入了图数据库,并将知识图谱持久化存储到图数据库中。另外,引入图数据库还有以下优势:
(1) 图数据库在处理关联数据时的速度快,而关系型数据库在处理反向查询以及多层次关系查询的时候通常开销较大,无法满足我们的要求。
(2) 图数据库可解释性好。图数据库基于节点和边,以一种直观的方式表示这些关系,具有天然可解释性。
(3) 图数据库查询语句表达性好,比如查询一跳,两跳数据,不需要像关系型数据库那样做复杂的表关联。
(4) 图数据库更灵活。图这种通用结构可以对各种场景进行建模,如社交网络、道路系统等。不管有什么新的数据需要存储,都只需要考虑节点属性和边属性。不像关系型数据库中,需要更新表结构,还要考虑和其他表的关联关系 等。
5.2 图数据库选型
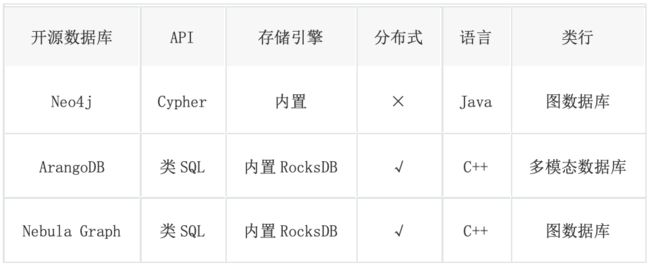
Neo4j 开源版本不支持分布式,无法满足我们对多副本的需求; ArangoDB 是 多模态数据库,支持 graph, document, key/value 和 search,支持分布式部署,查询速度快; NebulaGraph 一款是国产的开源图数据库,支持分布式部署且部署方式比 ArangoDB 更轻便,查询速度快,腾讯、京东等公司内部也在使用。
在充分比较了以上图数据库的性能,以及社区的活跃性以及开放性后,我们最终选择 NebulaGraph。针对上述的三个图数据库,我们做了一个详细的性能 Benchmark 对比: https://discuss.nebula-graph.com.cn/t/topic/1466
告警收敛及根因定位
6.1 流程
针对告警数据的收敛和根因定位,可以分为以下主要几个步骤。
多模态数据库
设置时间切片粒度: 实时获取时间切片内(1min、5min 等)的告警数 据;
告警分类: 针对原始的告警数据,结合具体的告警信息和监控项等信息,根据训练好的分类模型对原始的告警数据从 HOST、VM、SOFTW ARE 三个方面进行分类,例如: vm_网卡流量大、host_磁盘使用率过高、software_网页访问失败等。
告警收敛:查询软硬件知识图谱将告警以系统为单位进行收敛,收敛格式如下,格式如下:
系统 1: {软硬件知识图谱节点 1:[告警类型 1,告警类型 2…], 软硬件知识图谱节点 2:[告警类型 1,告警类型 2…]
告警因果图构建: 基于告警收敛结果,在图数据库中按照系统级别查询每个系统下的所有节点之间的连接子图,并将得到的结果输入到 networkx 中,得到某个系统下的各节点之间的最终连接关系,即告警因果图。
根因路径: 基于上述生成的告警因果图,以及权重来计算疑似路径,排序给出根因路径。
6.2 告警收敛
基于上述的主要流程,我们现以时间粒度为前后 5min 内的告警数据创建时间切片样本,并取告警数量最多的前 100 个时间片的样本作为主要分析的内容,其中第一个时间切片中的各个系统下各节点的告警收敛结果如下:

6.3 根因定位
对于上述第一个时间切片中的某个系统,在图数据库中查询该系统下的所有节点构成的子图,以 “苏宁 XXX 系统”这个系统为例,查询得到在“一跳”范围内与该系统下的所有节点之间有关联的节点的关系大致如下(红色表示物理机节点,棕色表示虚拟机节点,绿色表示软件节点):
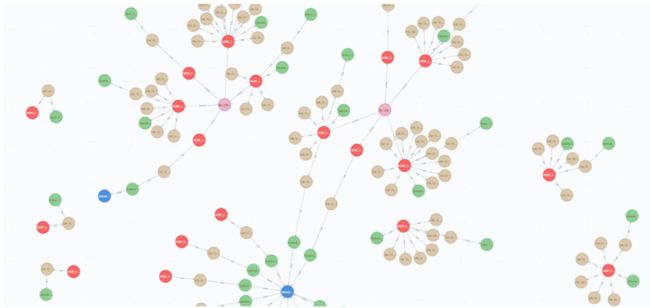
上图中出现的所有节点中,既包括有告警信息的,也包括没有告警消息的,因此将上述因果图输入到 netwokx 后,可以得到最终经过精简后的有告警消息发出的各节点的因果图,其中一部分的因果图展示如下:
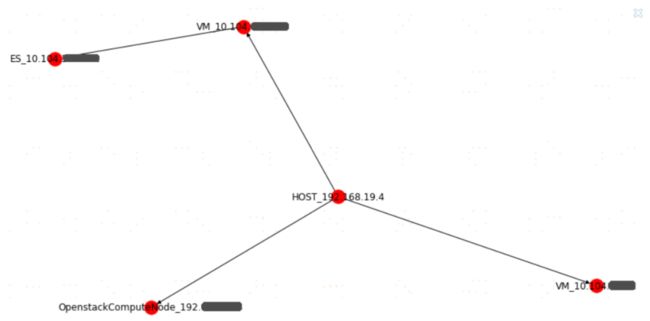
可以解释为: “192.168.xxx.xxx-host-服务器宕机”导致 “10.104.xxx.xxx-vm-服 务器宕机”,进而导致“software-网页访问失败”。
进一步的,根据上述生成的因果图,再结合因果图中每条边的权重,就可以计算出该时间切片下的单个系统层面上的所有疑似根因路径,经过排序后即可得到最终的根因路径。本例中最终得到的几条根因路径如下:

从上图可以看出,程序最终给出了几条疑似的根因路径,其中包括最长的一 条,可以解释为: ip 为 192.168.xxx.xxx 这台物理机由于网卡 overruns 的
原因,导致了这台物理机的宕机,从而使得这台物理机上的 ip 为 10.104.xx x.xxx 的虚拟机宕机,最终导致这台虚拟机上的相关的网页访问失败。
效果及优化方向
在告警收敛方面,经过验证,基于运维知识图谱可缩减至少 50% 的告警量,最高可达到 60% 以上,有效率的缓解了告警风暴的压力; 另外,在时效性方面,基于 1、2、5min 不同长度的时间切片进行告警收敛,耗时可以控制在 6 s 以内,满足告警通知的时效性要求。
在根因定位方面,经一线运维人员验证,每个告警时间段提供的可能根因传播路径集合基本包含了真实的根因,有效缩短了运维人员的干预时间;另外在耗时上,根因定位可以控制在 3s 以内,速度较快,满足时效性要求。
但目前通过因果发现算法自动构建的告警知识图谱准确率有待进一步提升,继续调研评估其他告警知识图谱构建方式。继续完善软硬件和调用链告警知识图谱,当前仅是基于 CMDB 和 Zabbix 告警数据构建运维知识图谱进行告警收 敛和根因定位,基础设施层面的告警数据更简单、规范,后续还要扩展到更复杂的非基础设施层面的告警数据中。当前还没有利用知识图谱对异常检测(时间序列数据)结果做根因定位的应用实践,这需要对时间序列做因果关系的发现,构建时间序列之间的因果图,从而打通知识图谱与异常检测的壁垒,这也是知识图谱后续使用的扩展方向之一。
谢谢你读完本文 (///▽///)
要来近距离体验一把图数据库吗?NebulaGraph 阿里云计算巢现 30 天免费使用中,点击链接 节省大量的部署安装时间来搞定业务吧~
想看源码的小伙伴可以前往 GitHub 阅读、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呢~